Assessment of Reward Functions for Reinforcement Learning Traffic Signal Control under Real-World Limitations
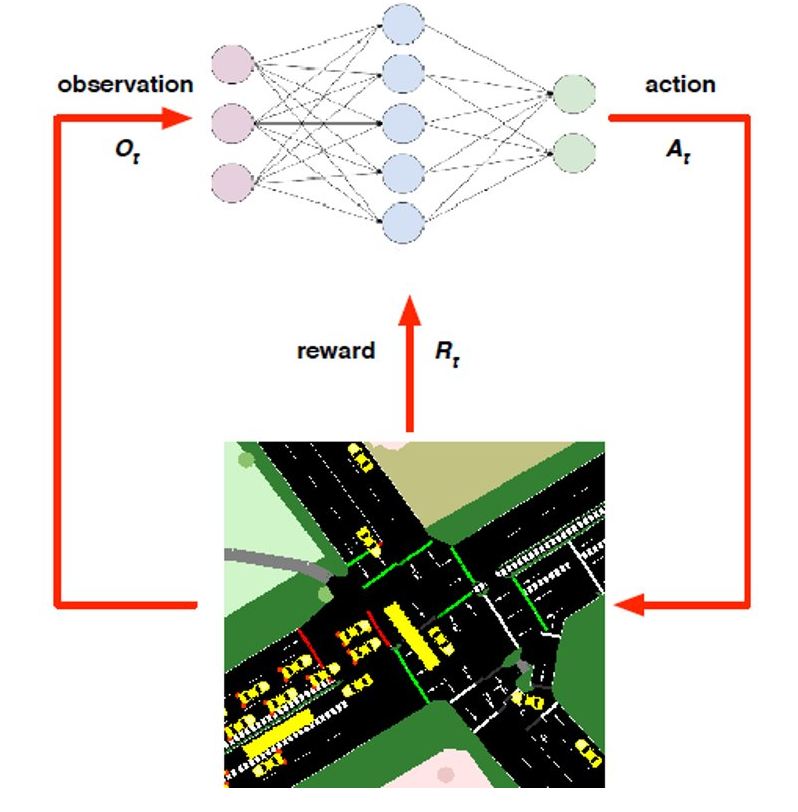
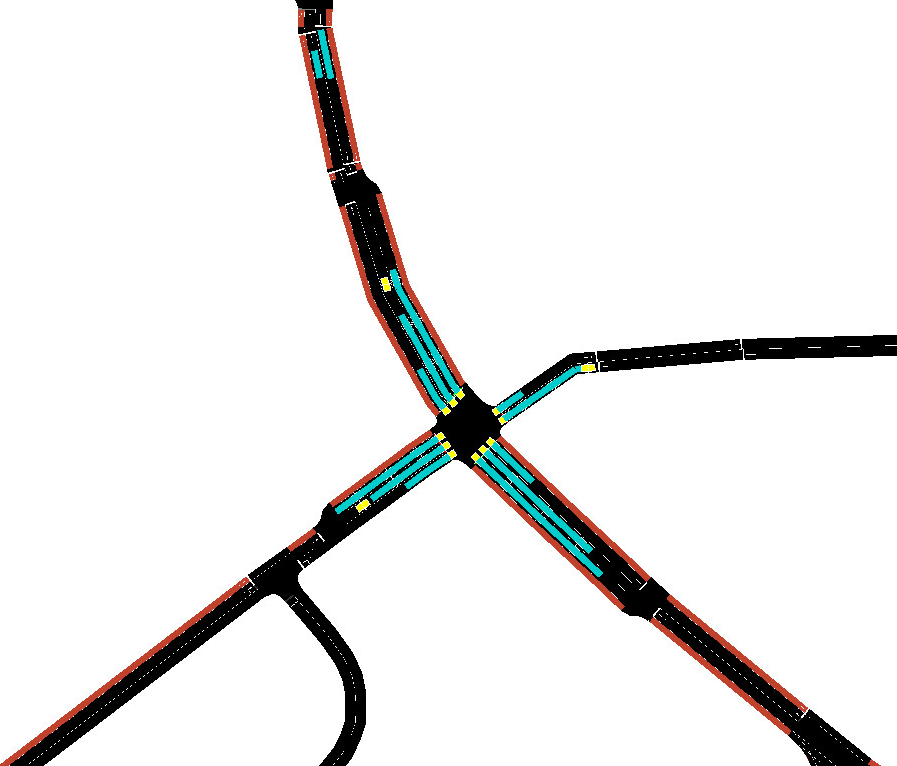
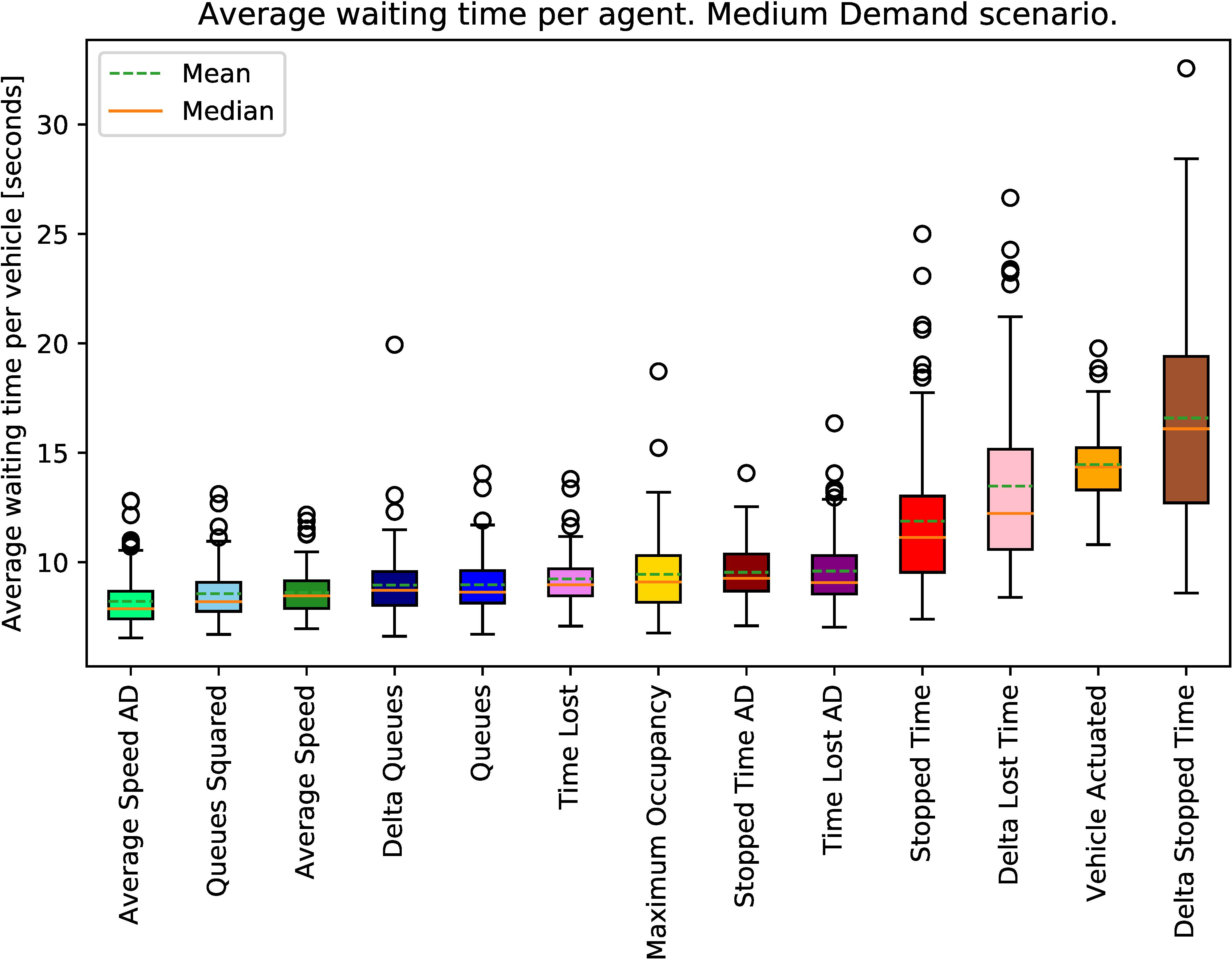
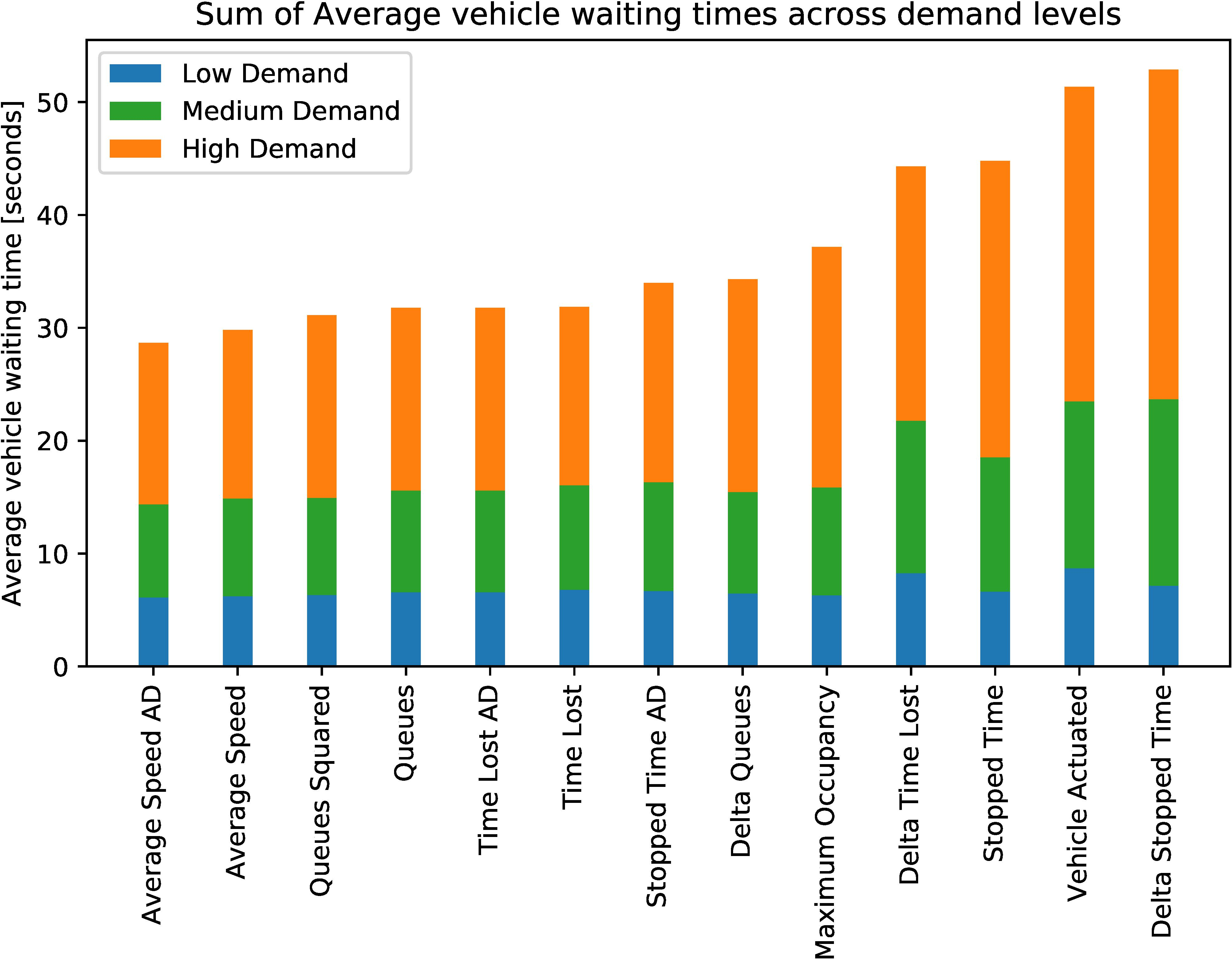
Abstract: Adaptive traffic signal control is one key avenue for mitigating the growing consequences of traffic congestion. Incumbent solutions such as SCOOT and SCATS require regular and time-consuming calibration, can't optimise well for multiple road use modalities, and require the manual curation of many implementation plans. A recent alternative to these approaches are deep reinforcement learning algorithms, in which an agent learns how to take the most appropriate action for a given state of the system. This is guided by neural networks approximating a reward function that provides feedback to the agent regarding the performance of the actions taken, making it sensitive to the specific reward function chosen. Several authors have surveyed the reward functions used in the literature, but attributing outcome differences to reward function choice across works is problematic as there are many uncontrolled differences, as well as different outcome metrics. This paper compares the performance of agents using different reward functions in a simulation of a junction in Greater Manchester, UK, across various demand profiles, subject to real world constraints: realistic sensor inputs, controllers, calibrated demand, intergreen times and stage sequencing. The reward metrics considered are based on the time spent stopped, lost time, change in lost time, average speed, queue length, junction throughput and variations of these magnitudes. The performance of these reward functions is compared in terms of total waiting time. We find that speed maximisation resulted in the lowest average waiting times across all demand levels, displaying significantly better performance than other rewards previously introduced in the literature.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

