- The paper demonstrates that GPT-3, with 175B parameters, achieves competitive few-shot performance without any task-specific fine-tuning.
- It utilizes a deep 96-layer transformer architecture and scales performance predictably with increased model size and data.
- The experimental evaluation confirms robust performance across tasks like translation, comprehension, and arithmetic while highlighting some limitations.
LLMs are Few-Shot Learners
This paper presents the architecture and performance characteristics of GPT-3, a large autoregressive LLM with 175 billion parameters. This model demonstrates remarkable few-shot learning capabilities, where it performs tasks based on minimal context given only in the input sequence without parameter updates. Below, we explore the methods, experimental setups, and implications of GPT-3 as a few-shot learner.
Model Architecture and Training
GPT-3 utilizes a transformer-based autoregressive model architecture similar to its predecessors in the GPT family but scaled significantly. It features 96 transformer layers, with 96 attention heads per layer, each head having a dimensionality of 128. The model was trained on 300 billion tokens gathered from a carefully filtered and deduplicated dataset, comprising Common Crawl, WebText2, Books1, Books2, and Wikipedia.
Notably, GPT-3 does not employ task-specific fine-tuning. Instead, it leverages in-context learning, where the model adapts to new tasks using examples given in the prompt. The training involved optimizing the model with Adam with a high learning rate and large batch sizes, supported by extensive parallelism across GPU clusters.
GPT-3 is assessed on various benchmarks across zero-shot, one-shot, and few-shot settings to evaluate its ability to perform without fine-tuning. The few-shot task examples highlight the model's capacity to understand tasks from minimal context and exhibit competitive performance with state-of-the-art fine-tuned systems.
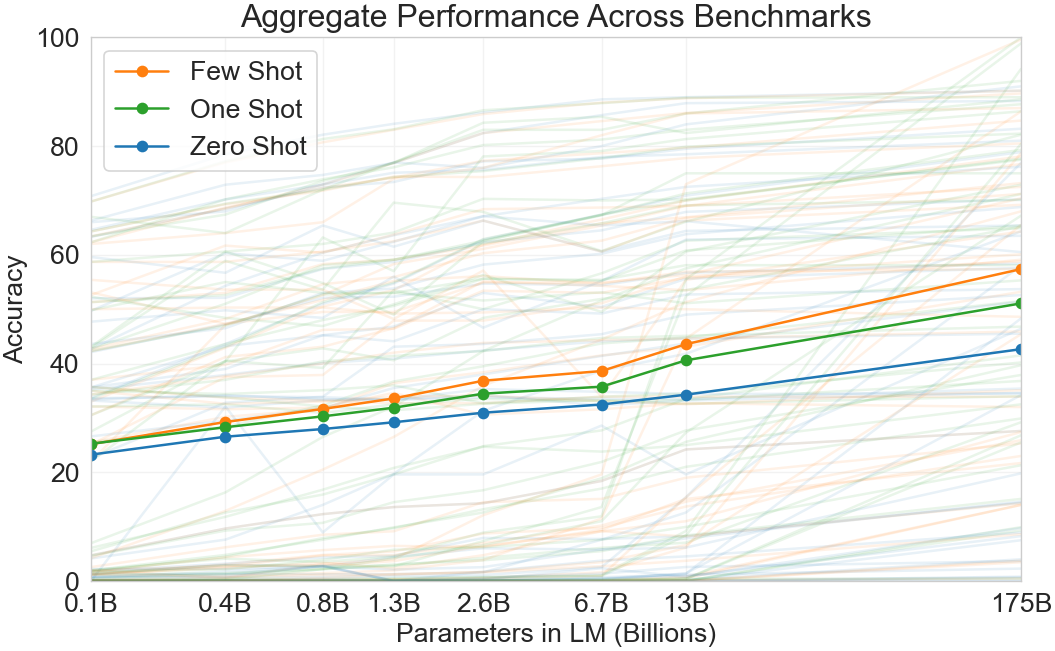
Figure 1: Aggregate performance for all 42 accuracy-denominated benchmarks~~~While zero-shot performance improves steadily with model size, few-shot performance increases more rapidly, demonstrating that larger models are more proficient at in-context learning.
Key findings from the experiments include:
- Zero-shot and Few-shot Learning: GPT-3 achieves impressive zero-shot and few-shot performance on NLP tasks such as translation, comprehension, and question-answering, often matching or surpassing fine-tuned baselines.
- Scaling Laws: The performance improves predictably with the scaling of both model size and computation, consistent with established scaling laws for language modeling.
- Task Versatility: Provides robust performance on diverse tasks, including arithmetic and word unscrambling, showing generalized capabilities in handling unseen challenges.
Implications and Future Research
The results indicate that larger models like GPT-3 can effectively learn new tasks during inference without traditional training or fine-tuning. This paradigm shift towards few-shot learning opens avenues for developing models with broader applicability and reduced need for large labeled datasets for each task.
While GPT-3 demonstrates compelling capabilities, it still faces limitations like coherence in long text generation and biases inherited from training data. Addressing these while improving efficiency and exploring multi-modal integration and more grounded training objectives remains promising in advancing AI.
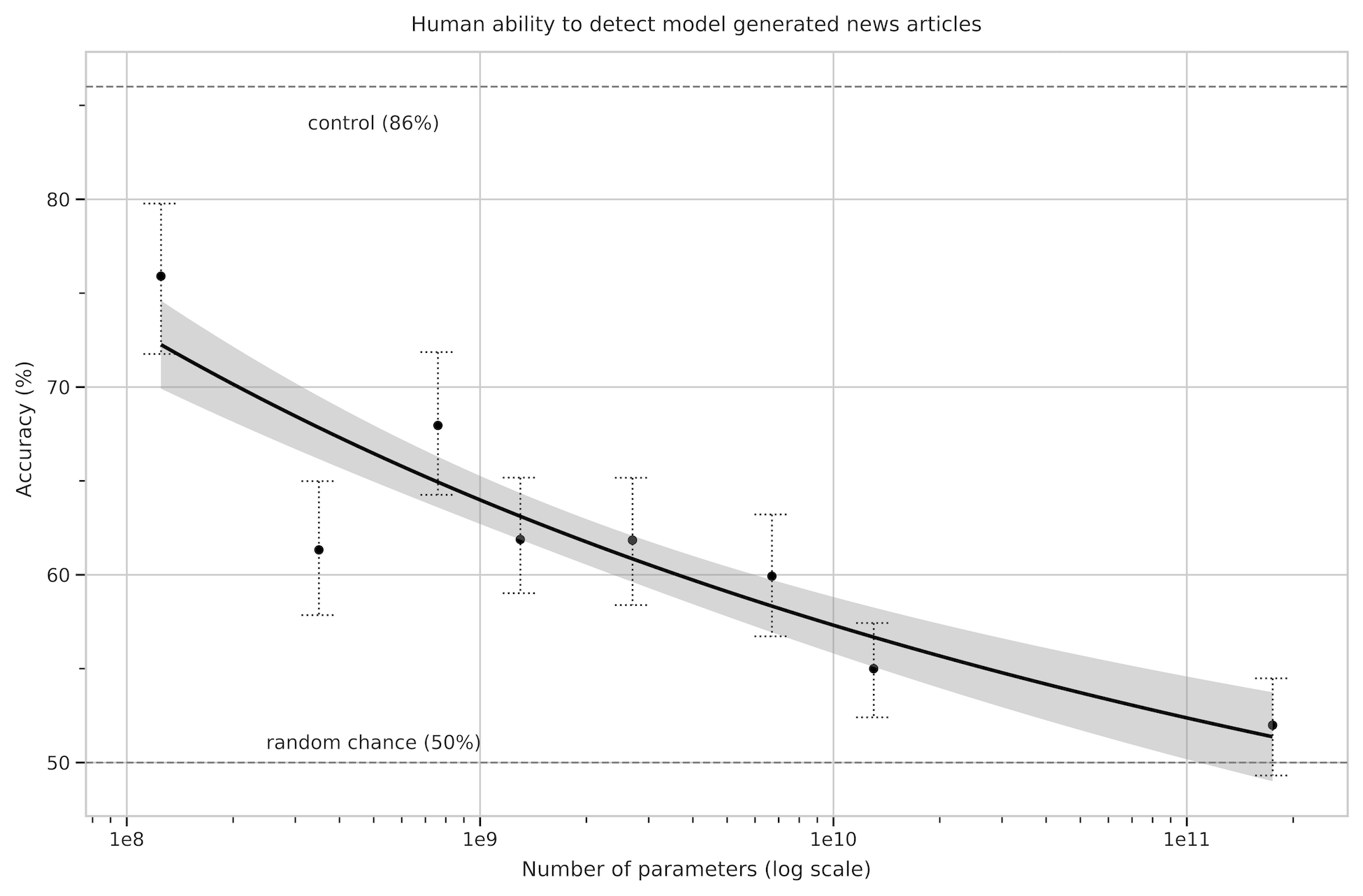
Figure 2: People's ability to identify whether news articles are model-generated (measured by the ratio of correct assignments to non-neutral assignments) decreases as model size increases. Accuracy on the outputs on the deliberately-bad control model (an unconditioned GPT-3 Small model with higher output randomness) is indicated with the dashed line at the top, and the random chance (50\%) is indicated with the dashed line at the bottom. Line of best fit is a power law with 95% confidence intervals.
Conclusion
GPT-3 sets a benchmark for few-shot learning in LLMs, demonstrating that larger models can achieve adaptability and performance close to fine-tuned systems through in-context learning. This capability signifies a pivotal advancement, potentially reducing the labor-intensive task-specific dataset creation burden in NLP. Future directions will focus on addressing remaining limitations and expanding upon this paradigm for widespread real-world applications.