- The paper presents a novel re-ranker strategy that integrates domain-specific DC, IC, and NER models to improve hypothesis ranking.
- It combines Expected SemER and Cross-Entropy loss functions to optimize ranking correctness and score calibration across domains.
- Experimental results demonstrate that the R3 optimization method outperforms baselines, ensuring scalable asynchronous training in NLU systems.
A Re-ranker Scheme for Integrating Large Scale NLU Models
This paper introduces a novel re-ranker strategy designed to integrate large-scale NLU models, emphasizing modularity, cross-domain hypothesis ranking, and score calibration. The approach leverages domain-specific components to maintain scalable and asynchronous model training while achieving cross-domain comparability through calibrated interpretation scores.
NLU System Design
The design of the proposed NLU system involves a modular approach, where each domain is encapsulated by three statistical models: a Domain Classifier (DC), an Intent Classifier (IC), and a Named Entity Recognizer (NER). Each domain generates hypotheses by aggregating outputs from its respective DC, IC, and NER.
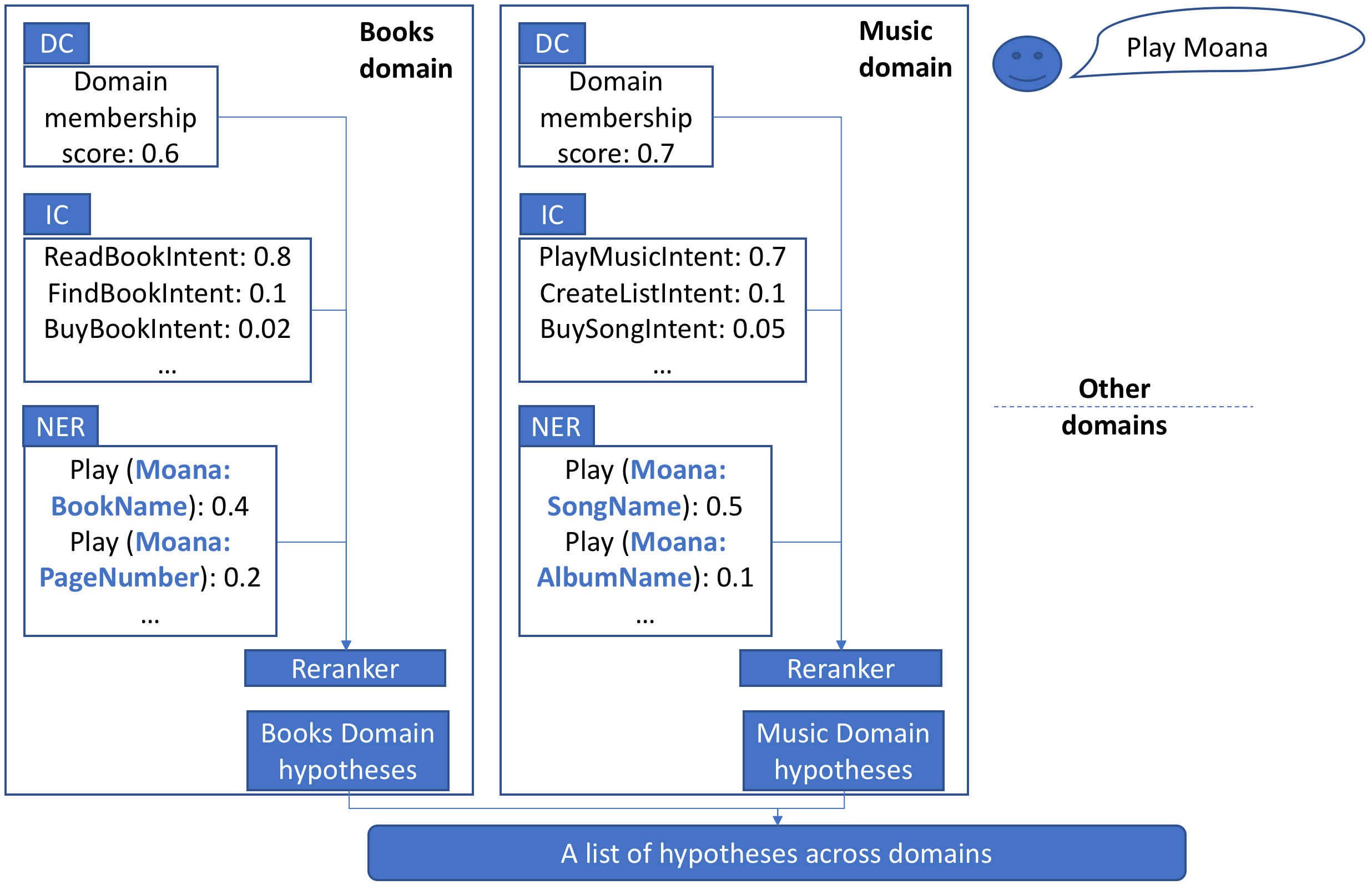
Figure 1: A description of a modularized NLU system design containing DC (One Vs All MaxEnt), IC (Multi class MaxEnt), and NER (CRF model) models. The re-ranker is proposed as the combination scheme to obtain a ranked list of NLU hypotheses.
These models produce domain-specific scores, used as input for a re-ranker model, which ranks hypotheses based on correctness and calibration across domains.
Re-ranker Design and Error Metrics
The re-ranker maintains modularity by employing domain-specific models and optimizing them using custom loss functions designed to ensure hypothesis correctness and score calibration. Two primary error metrics are introduced:
- Semantic Error Rate (SemER): Calculated using Levenshtein distance on IC and NER labels to assess correctness among in-domain hypotheses.
- Interpretation Error (IE): A binary metric indicating exact hypothesis correctness with respect to ground truth.
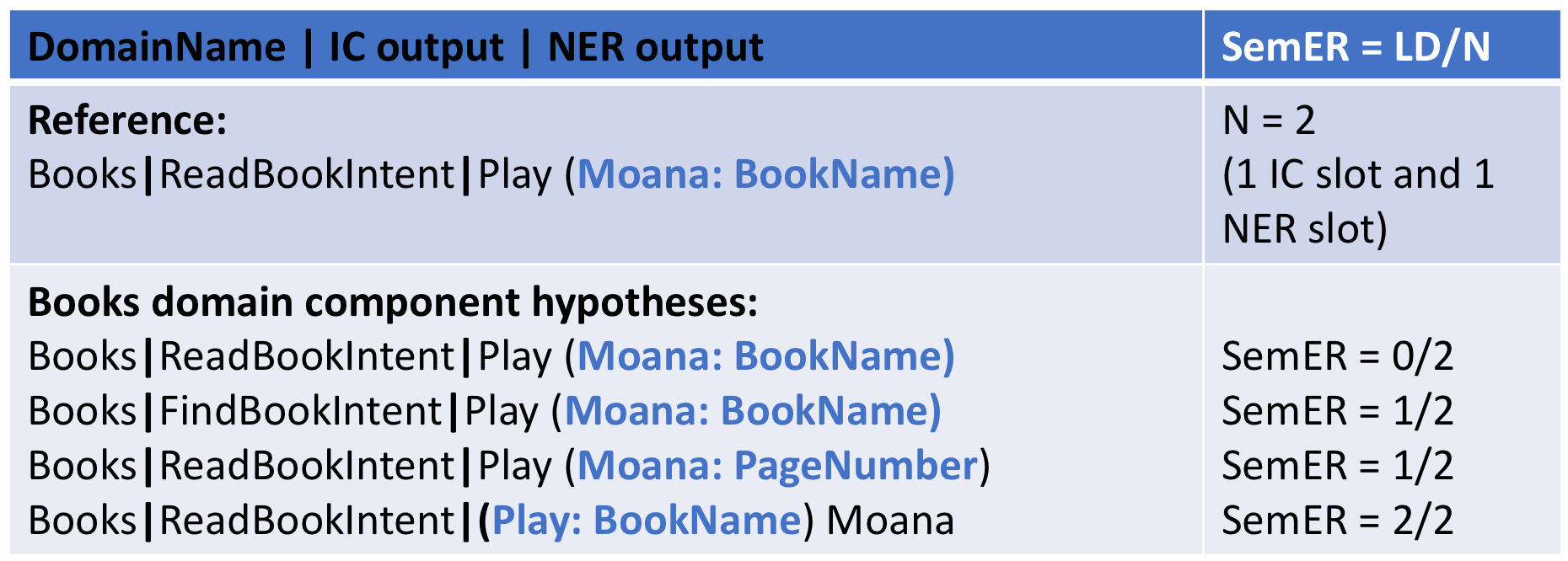
Figure 2: An example of SemER computation for hypotheses from the Books domain component. Note that the DC output is not used to compute Levenshtein distance (LD). N is the number of slots in the annotations.
The re-ranker model is trained using linear functions of DC, IC, and NER scores with various loss functions that incorporate expected SemER and cross-entropy losses for better rank and calibration performance.
Re-ranker Training and Optimization
The re-ranker's objective is to achieve optimal hypothesis selection and score calibration across domains. Three optimization schemes are presented:
- R1: Utilizes Expected SemER loss, focusing on ranking correctness.
- R2: Employs Cross-Entropy loss for calibration, addressing score comparability.
- R3: Combines both R1 and R2 losses, yielding the best outcome in terms of ranking and calibration balance.
These strategies allow the system to perform well even when domains are trained asynchronously or with different data subsets.
Experimental Results and Calibration
Experiments on an Alexa-enabled device with a large annotated dataset show significant performance enhancements using this re-ranker model. The study highlights improvements in aggregated SemER using R3 optimization, outperforming the baseline and other re-ranking strategies.
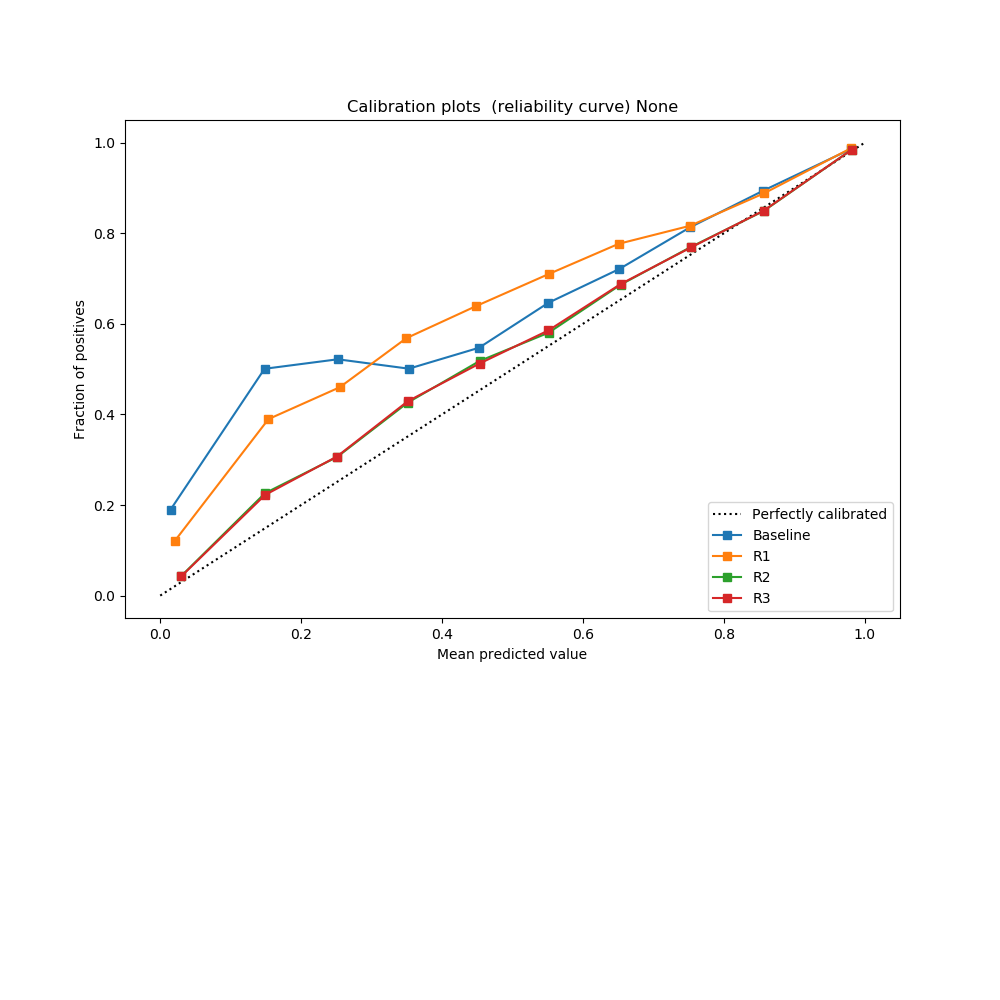
Figure 3: Confidence calibration plots obtained on hypotheses scores across all domains. While baseline and R1 optimization do not yield a good calibration, optimization using R2 and R3 provide the best calibration.
The model's calibration properties are evaluated using reliability curves, demonstrating improved cross-domain score alignment critical for downstream tasks and less error in threshold-based decisions.
Conclusion
The proposed re-ranker scheme underscores the importance of maintaining modularity and calibration in large-scale NLU models, allowing effective cross-domain integration and independent updates. With substantial improvements in SemER measures and reliable hypothesis ranking, this scheme sets a foundation for future developments in scalable NLU systems. Future work may explore enhanced feature integration and non-linear scoring functions to further refine hypothesis selection accuracy.

