- The paper presents the EMBER dataset, a large-scale open resource containing 1.1M labeled Windows PE files for static malware detection.
- It details a methodology that uses feature hashing on PE file structures to convert raw data into numeric vectors suitable for machine learning models.
- Experimental results show that a gradient-boosted decision tree model achieves superior ROC AUC performance compared to more complex deep learning approaches.
EMBER: An Overview
The paper "EMBER: An Open Dataset for Training Static PE Malware Machine Learning Models" (1804.04637) presents a significant advancement in the field of machine learning for malware detection through the creation of the EMBER dataset. This dataset provides a comprehensive resource of labeled data for training models aimed at identifying malicious Windows portable executable files. EMBER encompasses features from 1.1 million binary files, allowing for robust model development and evaluation within the security domain.
Introduction and Background
Machine learning offers powerful tools for automating complex data-driven tasks, such as static malware detection. Despite its potential, the public research community has witnessed limited progress in this area due to the scarcity of open, large-scale datasets comparable to those available for other applications like image recognition or sentiment analysis. The EMBER dataset addresses this gap by providing a well-structured corpus derived from Windows PE files, offering researchers the features necessary to enhance detection capabilities while navigating legal and security challenges.
The PE file format, ubiquitous in Microsoft Windows environments, serves as the foundation for the dataset's features. The format includes headers, sections, and data essential for execution, making it suitable for the static analysis required for malware detection. Several works have explored feature extraction from PE files, but EMBER's contribution lies in its large-scale, open access nature, designed to accommodate diverse research use cases.
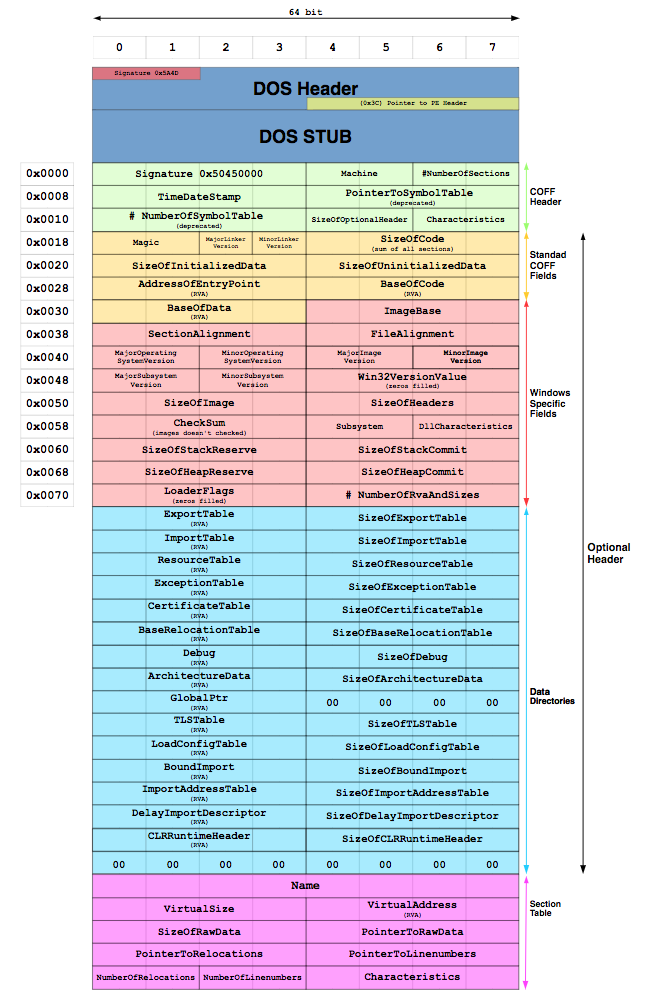
Figure 1: The 32-bit PE file structure. Creative commons image courtesy.
Dataset Structure and Methodology
The EMBER dataset is structured to facilitate a multitude of research approaches, from traditional machine learning model comparisons to the exploration of adversarial learning techniques. It consists of JSON files that detail each sample's features, including raw parsed data and format-agnostic attributes like byte histograms. These raw features are translated into model features using methods like feature hashing, which converts complex string representations into manageable numeric vectors for model training.
A distinct characteristic of EMBER is its allowance for temporal studies through coarse time stamps and the inclusion of unlabeled samples, supporting semi-supervised learning approaches. This setup not only aids in understanding concept drift over time but also broadens the spectrum for research into unsupervised learning strategies in malware detection contexts.
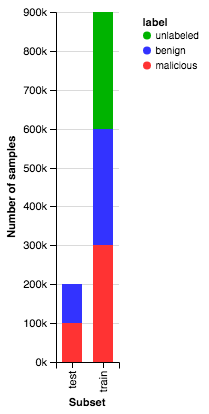
Figure 2: Distribution of malicious, benign, and unlabeled samples in the training and test sets.
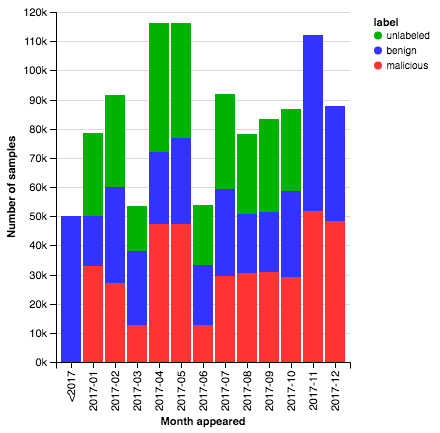
Figure 3: A temporal distribution of the dataset, available from chronology data in the metadata.
Experimental Results
The paper demonstrates the EMBER dataset's utility by constructing a baseline model using gradient-boosted decision trees (GBDT) via LightGBM. Though lacking hyper-parameter optimization, this model achieves impressive ROC AUC results, surpassing performance metrics of more complex models like MalConv, a contemporary end-to-end deep learning solution. This highlights that domain-specific feature knowledge incorporated into machine learning models can yield higher efficacy than raw data-driven methods alone.
The comparison, depicted through ROC curves, affirms the EMBER dataset's capability to serve as a benchmark for evaluating various machine learning models and architectures.
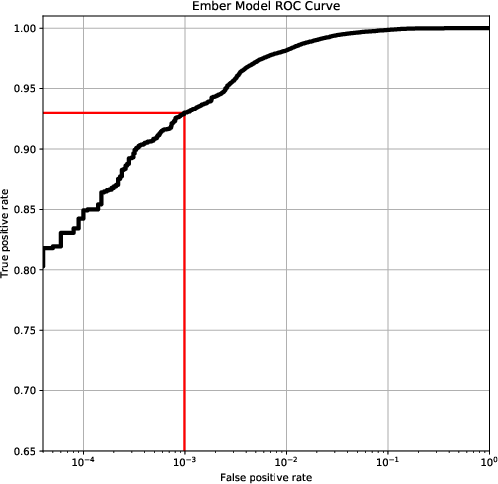
Figure 4: ROC curve with log scale for false positive rate (FPR).
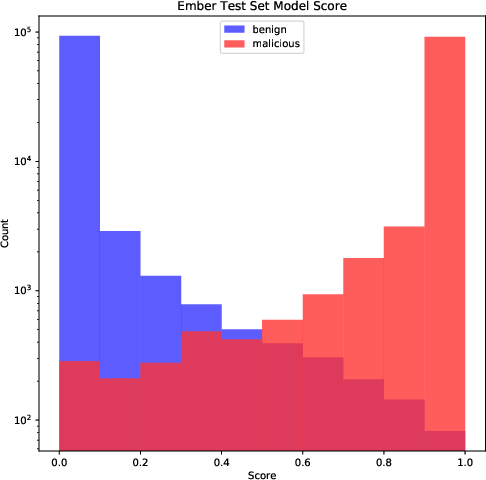
Figure 5: Distribution of model test scores on the test set (note the logarithmic scale).
Conclusion
The EMBER dataset constitutes an invaluable resource for advancing machine learning research in malware detection, bridging previous gaps in publicly available data. By fostering innovation across multiple research domains, EMBER invites exploration into static analysis, interpretability, and adversarial resilience within security contexts. The deployment of this dataset alongside a benchmark model provides a foundation upon which future studies can build, enhancing model accuracy and robustness through methodological refinement and technological advancement. As such, EMBER represents a pivotal step forward in aligning machine learning capabilities with real-world cybersecurity challenges.

