Value Alignment of Social Media Ranking Algorithms
Abstract: While social media feed rankings are primarily driven by engagement signals rather than any explicit value system, the resulting algorithmic feeds are not value-neutral: engagement may prioritize specific individualistic values. This paper presents an approach for social media feed value alignment. We adopt Schwartz's theory of Basic Human Values -- a broad set of human values that articulates complementary and opposing values forming the building blocks of many cultures -- and we implement an algorithmic approach that models and then ranks feeds by expressions of Schwartz's values in social media posts. Our approach enables controls where users can express weights on their desired values, combining these weights and post value expressions into a ranking that respects users' articulated trade-offs. Through controlled experiments (N=141 and N=250), we demonstrate that users can use these controls to architect feeds reflecting their desired values. Across users, value-ranked feeds align with personal values, diverging substantially from existing engagement-driven feeds.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: what if your social media feed showed you posts that match the values you care about, not just the things most likely to get clicks and likes? The authors build and test a way to reorder (rank) a feed so it highlights posts that express human values like caring, fairness, achievement, or respect—letting users choose which values to amplify or tone down.
What questions did the researchers ask?
They focused on four easy-to-understand goals:
- Can we detect which human values a social media post is expressing?
- Can we re-rank a feed based on the values a user cares about, instead of just engagement?
- Will users notice and prefer feeds aligned with their chosen values?
- What happens when users adjust more than one value at a time—do the feeds still feel meaningfully different?
How did they do it?
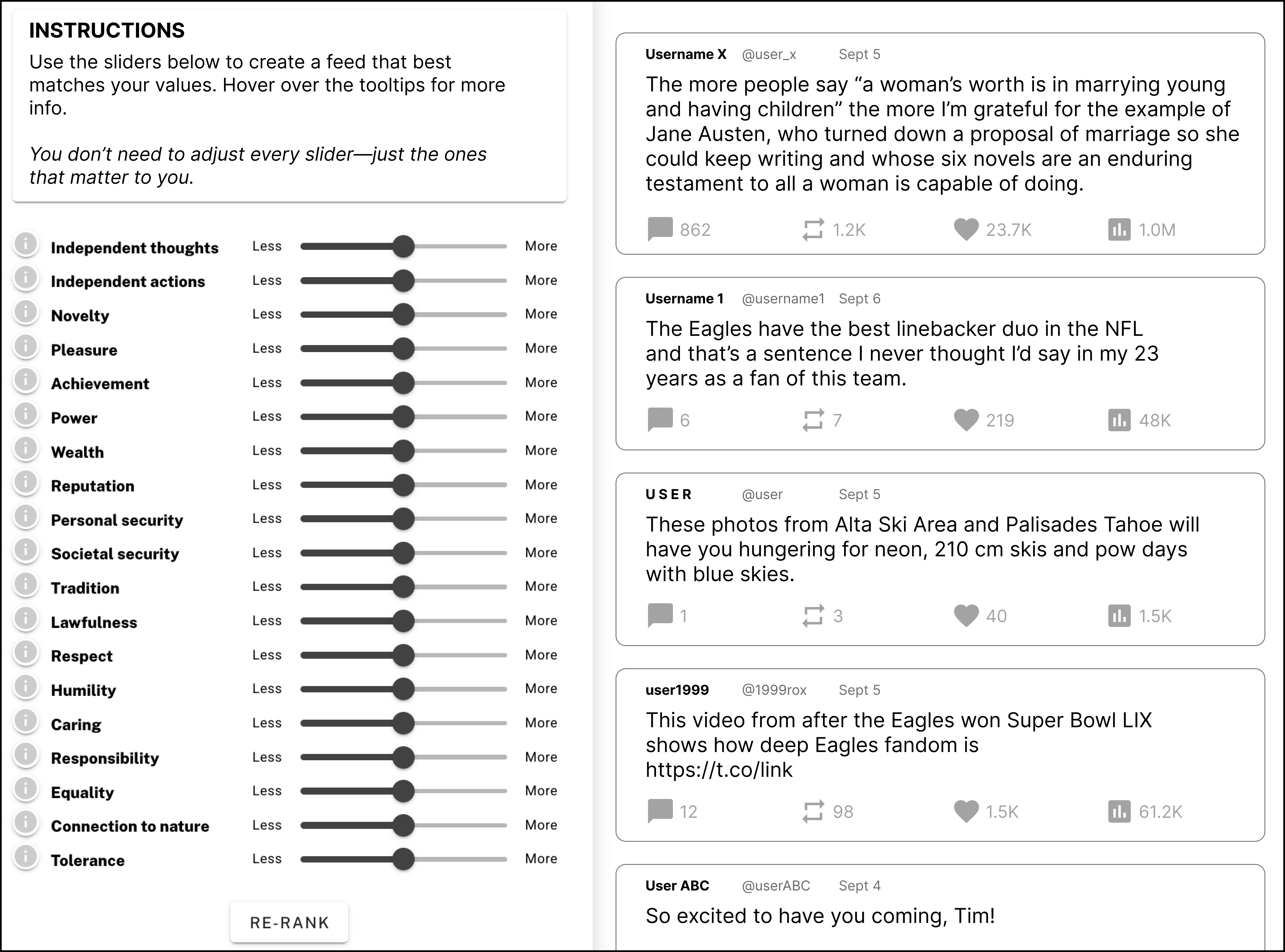
Think of the system like a music equalizer with sliders—each slider is a value. You move the sliders up for values you want more of (like “Caring”) and down for values you want less of (like “Domination”), and your feed reorders itself to fit your settings.
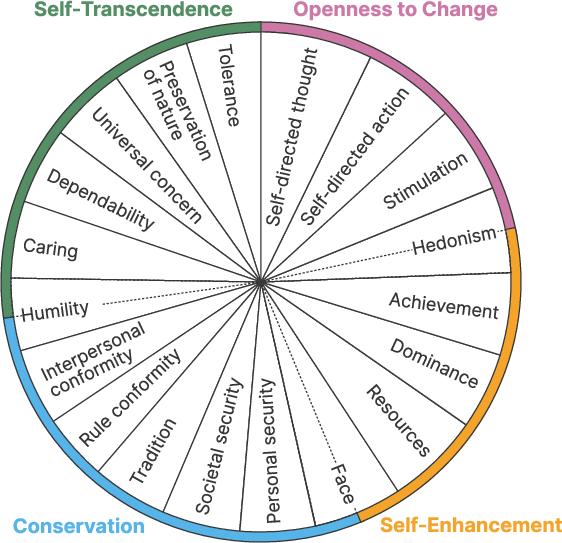
Step 1: A shared “value map”
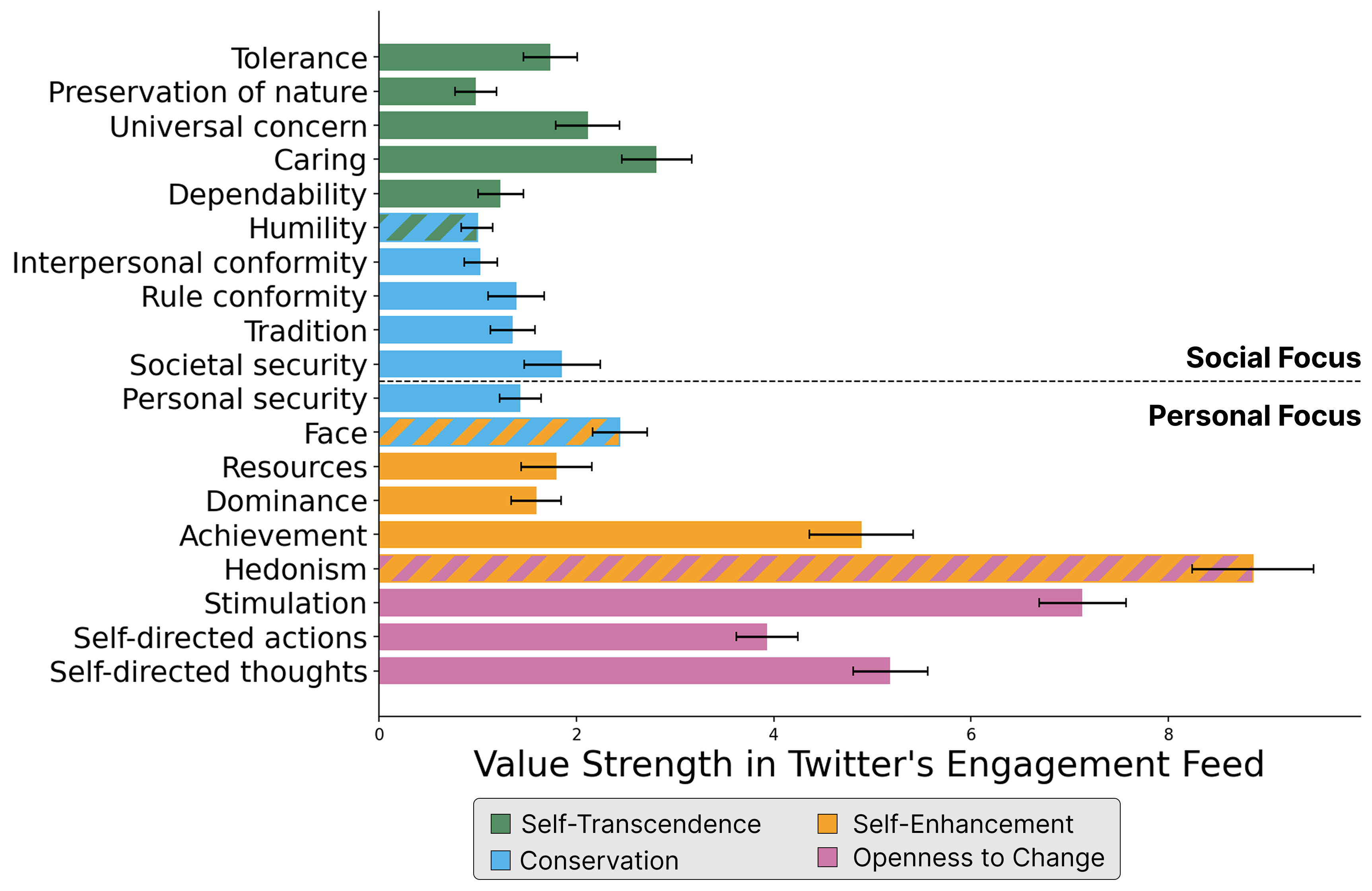
They use Schwartz’s Basic Human Values, a well-studied set of 19 values found across many cultures. These values sit on a “circle” where nearby values are similar (like “Caring” and “Tolerance”) and opposite values can be in tension (like “Achievement” vs. “Humility”). The four big groups are:
- Self-Transcendence (e.g., Caring, Universal Concern)
- Openness to Change (e.g., Stimulation, Self-directed Actions)
- Conservation (e.g., Tradition, Personal/Societal Security)
- Self-Enhancement (e.g., Achievement, Power/Dominance, Resources)
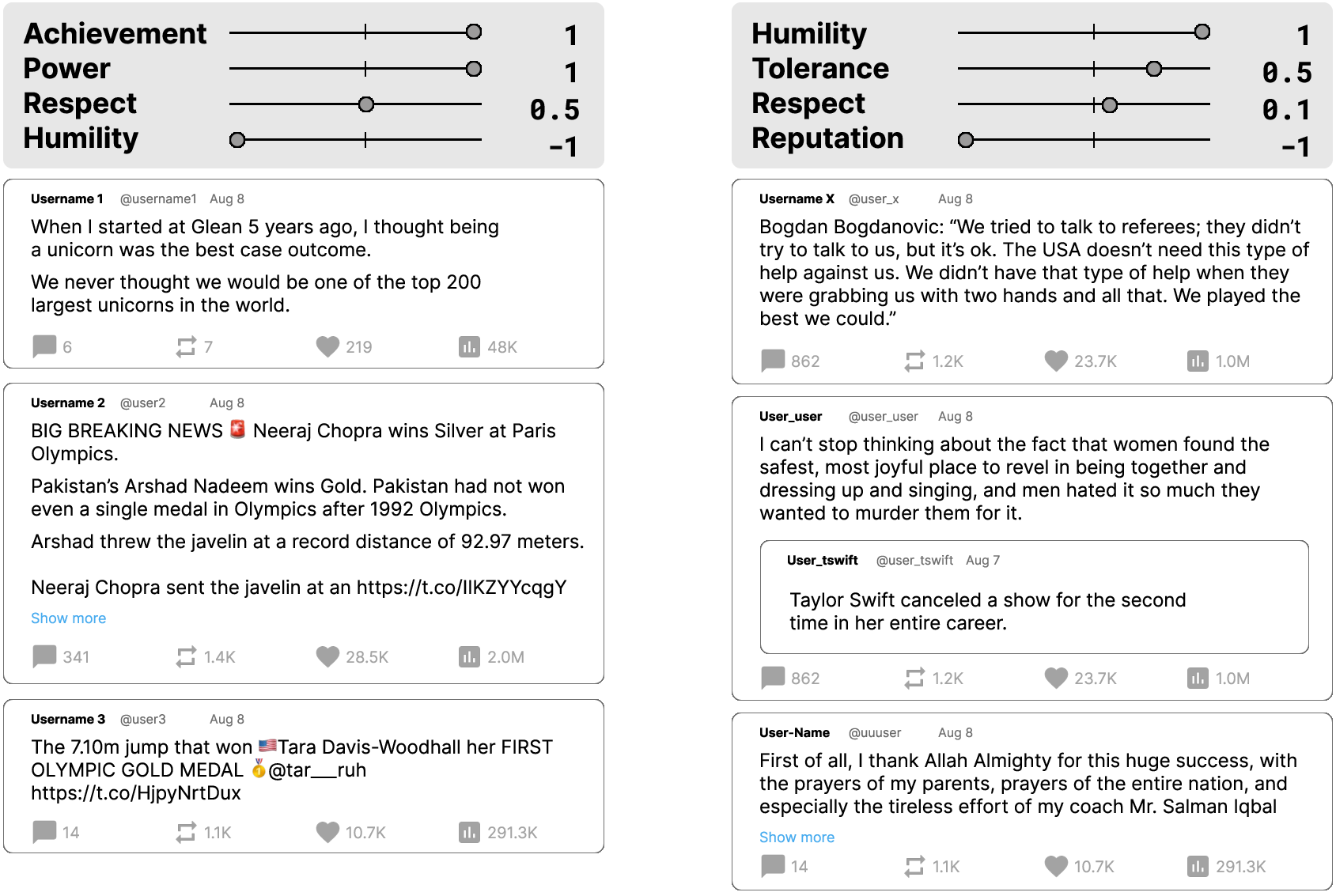
Step 2: Tagging posts with value “stickers”
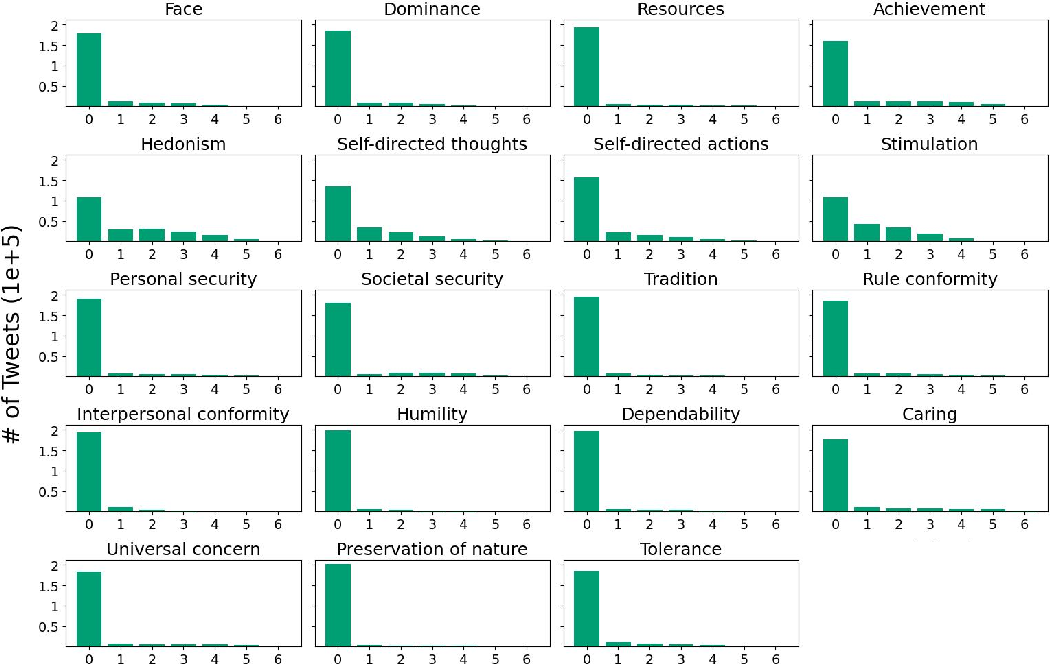
They used a LLM, similar to GPT-4, to read each post (including images and link previews) and assign scores for all 19 values:
- 0 means the post doesn’t support that value (or even opposes it),
- 1–6 means the value is present, from weak to strong.
Think of this like a super-fast librarian putting 19 “value stickers” on every post, with numbers showing how strongly each value appears.
They checked accuracy using a dataset where many humans had labeled thousands of posts. On average, the LLM’s labels were as good as or better than a typical human annotator compared to the group’s consensus.
Step 3: Re-ranking the feed with value sliders
Users set a weight for each value from -1 (show much less) to +1 (show much more). The system calculates a score for each post by combining:
- the post’s value sticker strengths (0–6),
- the user’s slider settings (-1 to +1), then sorts posts from highest to lowest total score.
In everyday terms: posts get “points” when they match your values and lose points when they go against your values. The feed shows the most points first.
Step 4: Experiments with real users and real feeds
They ran controlled online studies:
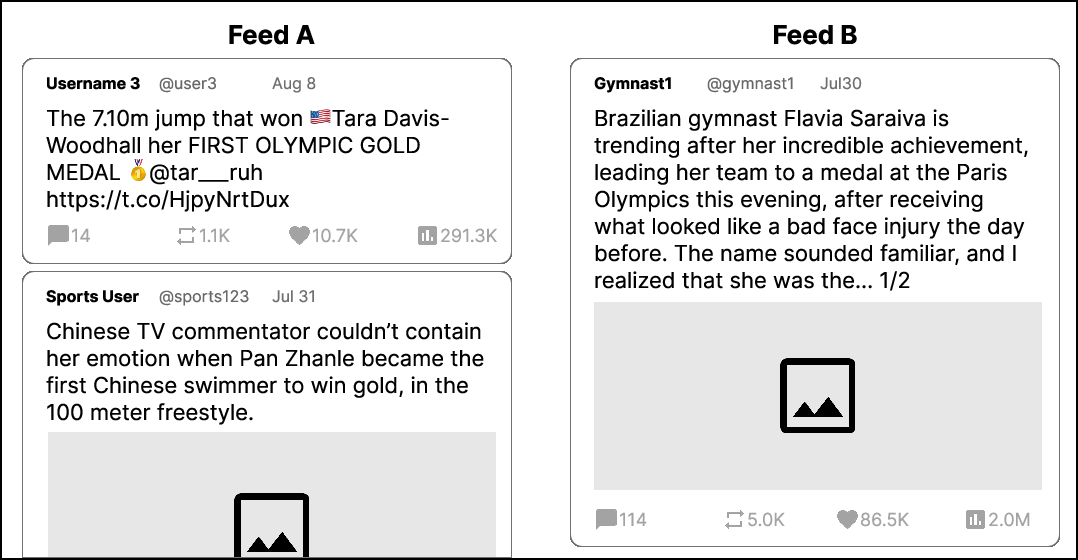
- Study 1 (N=141): Participants installed a browser extension to collect posts from their own Twitter/X “For You” feed. They filled out a standard value survey (PVQ), then saw two feeds side-by-side—one re-ranked by one of their top values vs. the original engagement-based feed—and tried to pick which one matched the named value. This happened for four values per person.
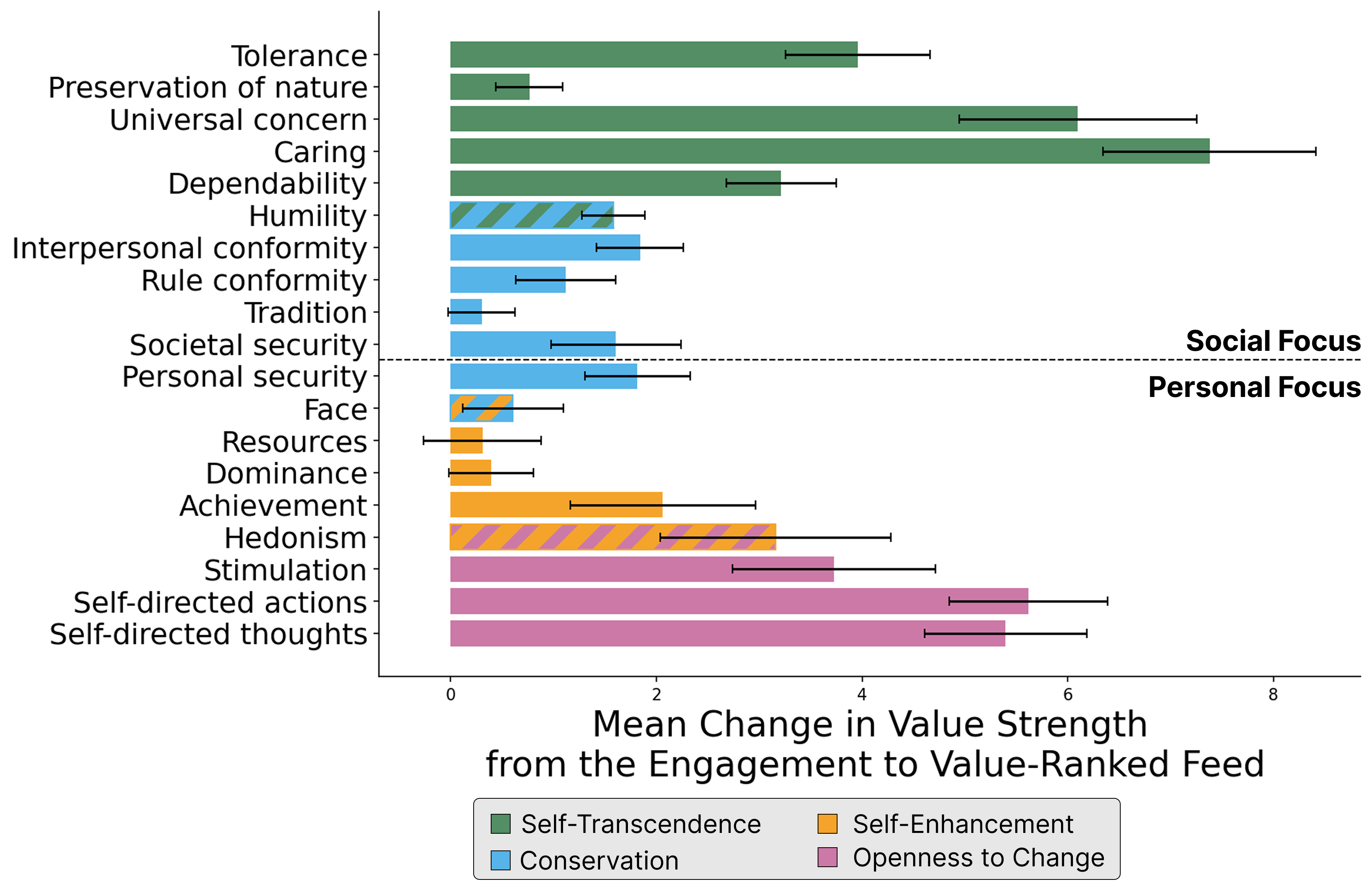
- Study 2 (mentioned in the paper’s overview): Users directly moved value sliders and saw the feed change live, then tried to identify the value-aligned feed in a blinded comparison. Across users, value-ranked feeds were very different from engagement feeds (low similarity, average Kendall’s τ ≈ 0.06).
What did they find?
- The LLM could reliably label values in posts: Its average error compared to human consensus was slightly lower than a typical human’s error in most values.
- People could recognize value-aligned feeds: In Study 1, participants correctly picked the value-aligned feed about 76% of the time (well above random guessing at 50%). Over a third got all four identifications right.
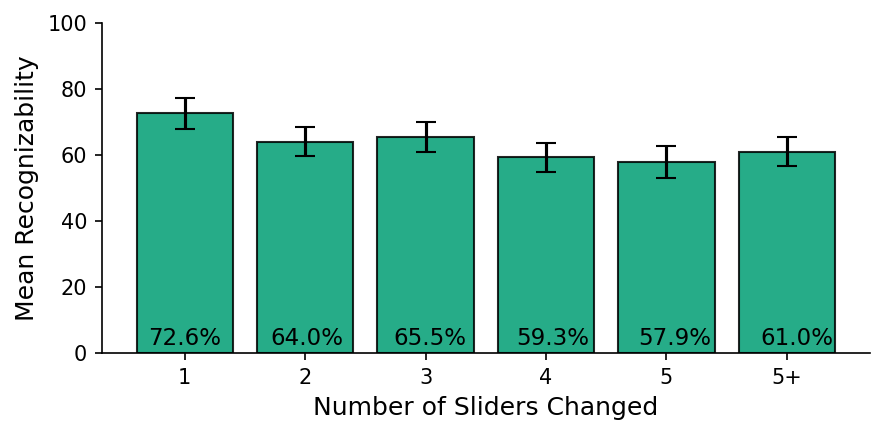
- Most values were recognizable: Values like “Caring” and “Preservation of Nature” were highly recognizable. A few (like “Interpersonal Conformity”) were harder to spot. Values in the “Openness to Change” group (like “Self-directed Actions” and “Stimulation”) tended to be less recognizable, possibly because the engagement feed already leans toward novelty.
- Value-tuned feeds diverged from engagement: When users pushed multiple sliders, the resulting feeds differed a lot from the platform’s engagement ranking. Users often set sliders to match their personal values, and the system reflected those choices.
Why this matters: It shows we don’t have to accept a one-size-fits-all, engagement-only feed. People can steer their feeds toward the values they care about.
What does this mean and why is it important?
- More control for users: Instead of guessing what the algorithm wants, people can decide what matters to them—like more kindness and less vanity—and the feed can follow their lead.
- Healthier online spaces: Aligning feeds to values could reduce problems linked to engagement-only ranking, like polarization, outrage-bait, or shallow novelty. It can encourage balance—e.g., more posts about helping others, community, or the environment—if users want that.
- Flexible for platforms and communities: The method could be used by big platforms, community-run networks, or personal tools. It fits different governance styles (centralized or user-driven).
- Important guardrails: There’s also a risk—powerful actors could push certain values to control narratives. The authors emphasize user choice, transparency, and pluralism (many value options, not just one) to reduce that risk.
In short, the paper shows a practical, tested way to re-rank social media feeds by human values. It gives people a clear, adjustable “equalizer” for what they see online, proving that value-aware feeds are both technically possible and meaningful to users.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single list of specific gaps and open questions that remain unresolved and could guide future research:
- Generalizability beyond Twitter/X: Does the approach (classification and reranking) transfer to other platforms (Instagram, TikTok, Reddit, Mastodon/Bluesky) with different content formats, social graphs, and ranking pipelines?
- Language and cultural coverage: How well do value classifications perform on non-English posts, code-switching, and in culturally diverse contexts where Schwartz’s values may manifest differently or be interpreted differently?
- Ground-truth validity and annotator bias: The human-labeled dataset’s composition and annotator demographics are not detailed; inter-annotator reliability (e.g., Krippendorff’s alpha) and potential biases in consensus labels need to be reported and audited, especially across values and topics.
- Differentiating neutral vs counter-value content: The 0–6 scale conflates “no value present” with “value contradicted”; should negative scores (e.g., −6 to +6) or separate labels capture active opposition to a value?
- Magnitude calibration across values: Are scores comparable across values (e.g., is a “6” on Caring commensurate with a “6” on Achievement)? Methods for cross-value calibration and normalization are not provided.
- Model uncertainty and abstention: No confidence estimates or abstain mechanisms are used; can uncertainty-aware classification reduce mislabeling and support human-in-the-loop review for borderline cases?
- Multi-modal robustness: Performance on images, memes, videos, embedded links, and sarcasm/irony is not analyzed separately; how does accuracy vary by modality and genre?
- Proprietary model dependency: The pipeline relies on GPT-4o; how stable are results across model versions, and can open-source models achieve comparable performance to ensure reproducibility and cost control?
- Adversarial gaming risks: Could creators optimize content to trigger specific value labels (Goodhart’s law)? What defenses (adversarial training, behavioral monitoring) are effective against strategic manipulation?
- Real-time scalability and cost: What are the latency, throughput, and cost implications of classifying and reranking at platform scale in near-real-time, including API rate limits and model inference constraints?
- Privacy and data governance: What safeguards and retention policies apply to processing users’ feeds (including images and links) via a browser extension; how is PII handled, and can on-device inference mitigate risks?
- Engagement trade-offs: How does value-aligned reranking affect key platform metrics (session length, retention, revenue) compared to engagement-driven ranking in realistic A/B deployments?
- Longitudinal effects: Do value-aligned feeds affect well-being, trust, civic outcomes, or polarization over time? Are there value-drift dynamics where user preferences evolve with exposure?
- Echo chamber risks and diversity: Does tailoring by values reduce viewpoint diversity or increase homophily? How should diversity constraints or exploration policies be incorporated?
- Governance and misuse: What protections prevent platforms or governments from imposing specific values on populations? Which transparency, consent, and opt-out mechanisms are necessary?
- Multi-stakeholder alignment: How are conflicts between individual, community, and societal values resolved (e.g., arbitration, multi-objective optimization, collective weighting)?
- Preference elicitation methods: How do PVQ-derived weights compare to direct slider controls or implicit learning (from behavior) in accuracy, usability, and cognitive load? What onboarding aids reduce misinterpretation of values?
- Non-linear trade-offs: The approach uses a linear dot product; do interaction effects between values require non-linear models (e.g., learned reward functions), and does linearity suffice empirically across complex preferences?
- Circumplex-informed constraints: Can the circumplex geometry (adjacency and opposition) be explicitly encoded (e.g., regularization that penalizes opposites or couples adjacent values) to improve coherence and stability?
- Inventory bias: Reranking only content pre-selected by the “For You” algorithm may inherit engagement biases; how do results differ on chronological or follow-graph inventories or when expanding content retrieval?
- Platform integration: How should value scores be combined with engagement, quality, and safety signals in a multi-objective ranker? What weighting strategies and Pareto-front analyses perform best?
- Multi-value recognizability thresholds: At what number/complexity of simultaneously-optimized values does recognizability degrade, and can explanations or interface aids preserve perceived coherence?
- Explainability to users: Can per-post explanations (e.g., “ranked higher due to Caring and Humility”) improve trust, understanding, and control without overwhelming users?
- Demographic fairness: Do classification errors or value-based reranking systematically advantage or disadvantage content from particular dialects, minority groups, or creators? How should fairness audits and mitigations be designed?
- Topic coverage: How do values manifest in non-political domains (entertainment, hobbies, niche communities), and are there coverage gaps or systematic blind spots?
- Video and live content: The pipeline’s support for video and live streams is not evaluated; how can temporal and audio cues be incorporated into value detection reliably?
- Prompt stability and replication: How sensitive are labels to prompt wording and few-shot examples; can standardized prompts and public benchmarks reduce variance and enable reproducible comparisons?
- Ranking stability: How do ties, score saturation, and weight granularity (−1 to 1 in 0.25 steps) affect rank volatility; are normalization or temperature-like controls needed?
- Safety constraints: How to enforce guardrails (e.g., limit amplification of values when linked to harmful behaviors) without overriding user autonomy? What policy frameworks are appropriate?
- Creator impacts: How will value-aligned ranking affect reach, monetization, and perceived fairness for creators across genres and demographics?
- Code-switching and multilingual posts: How accurate is classification on bilingual content, transliteration, and mixed-modality text (e.g., alt text, captions)?
- Interface design: Are slider-based UIs optimal for lay users; do alternative controls (presets, narratives, wizard flows) reduce error and effort?
- Divergence metrics: Kendall’s τ quantifies order differences; what alternative metrics (e.g., coverage, topical diversity, value intensity distributions) better capture meaningful feed changes?
- Legal and regulatory compliance: How does value-based reranking intersect with platform liability, transparency laws, and moderation mandates across jurisdictions?
Collections
Sign up for free to add this paper to one or more collections.

