- The paper introduces covariant quantum kernels for symmetry-structured data, effectively overcoming the exponential concentration issue common in quantum kernel methods.
- It demonstrates robust trainability by maintaining stable kernel variance under coherent noise, as verified through extensive numerical simulations.
- The study extends quantum kernel design beyond two-coset constructions, offering scalable solutions for NISQ-era quantum machine learning applications.
Quantum Advantage without Exponential Concentration: Trainable Kernels for Symmetry-Structured Data
Introduction
The paper explores the intersection of quantum computing and machine learning, focusing on Quantum Machine Learning (QML) and its potential to harness quantum mechanics for enhanced learning algorithms. A central aspect of this research is the application of quantum kernel methods, which traditionally suffer from kernel concentration and barren plateaus, limiting their efficacy and trainability.
Covariant Quantum Kernels
The paper introduces covariant quantum kernels tailored to datasets with inherent group symmetries. This approach avoids the problem of exponential concentration, characterized by the concentration of kernel values, which impairs the expressivity and trainability of quantum models. The authors extend prior work beyond two-coset constructions, facilitating broader application of quantum kernels to a wider range of problems with symmetry-based data structures.
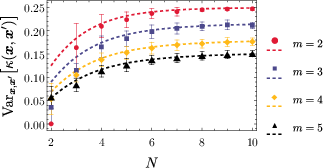
Figure 1: An illustration of kernel variance for simulations of N=10 qubits across different subsets.
Trainability and Coherent Noise
An important contribution of the paper is the derivation of trainable quantum models that are resilient to coherent noise, a common challenge in practical QML implementations. These models maintain a finite, stable variance across different levels of unitary errors and other perturbations during state preparation and group element selection.
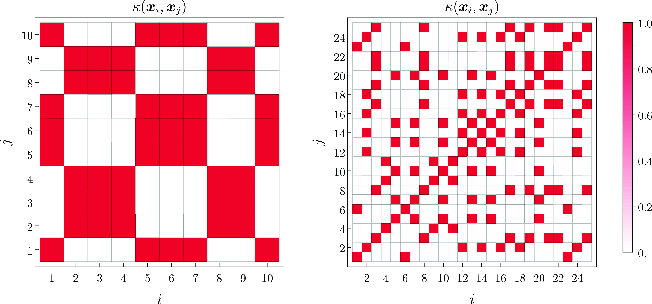
Figure 2: A heat map of kernel values for N=10 qubits showing the distribution of kernel entries.
Numerical Simulations and Results
The researchers conducted extensive numerical simulations demonstrating that their quantum kernel construction robustly maintains significant variance without falling prey to exponential concentration, even when perturbations are introduced. These simulations provide practical evidence that the kernels can distinguish between data points effectively in a high-dimensional Hilbert space.
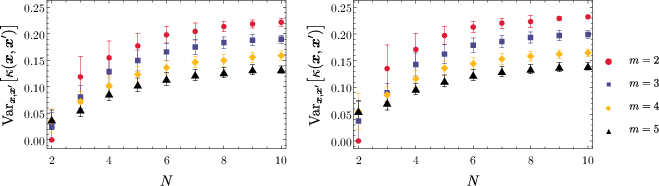
Figure 3: Kernel variance in the presence of noise, demonstrating robustness to coherent errors.
Implications and Future Directions
This research solidifies the potential of group-symmetric quantum kernels as a viable framework for scalable quantum machine learning applications. The findings encourage further exploration in designing QML models that inherently circumvent trainability barriers and remain effective under realistic noise conditions, offering a promising direction for NISQ-era quantum computation.
Conclusion
The study articulates a significant advancement in quantum kernel methods by demonstrating their inherent resilience to kernel concentration and noise. This positions group-symmetric quantum kernels as a robust and scalable solution for complex symmetry-structured data, emphasizing their applicability in advancing the frontier of quantum machine learning.