IMD: A 6-DoF Pose Estimation Benchmark for Industrial Metallic Objects
Abstract: Object 6DoF (6D) pose estimation is essential for robotic perception, especially in industrial settings. It enables robots to interact with the environment and manipulate objects. However, existing benchmarks on object 6D pose estimation primarily use everyday objects with rich textures and low-reflectivity, limiting model generalization to industrial scenarios where objects are often metallic, texture-less, and highly reflective. To address this gap, we propose a novel dataset and benchmark namely \textit{Industrial Metallic Dataset (IMD)}, tailored for industrial applications. Our dataset comprises 45 true-to-scale industrial components, captured with an RGB-D camera under natural indoor lighting and varied object arrangements to replicate real-world conditions. The benchmark supports three tasks, including video object segmentation, 6D pose tracking, and one-shot 6D pose estimation. We evaluate existing state-of-the-art models, including XMem and SAM2 for segmentation, and BundleTrack and BundleSDF for pose estimation, to assess model performance in industrial contexts. Evaluation results show that our industrial dataset is more challenging than existing household object datasets. This benchmark provides the baseline for developing and comparing segmentation and pose estimation algorithms that better generalize to industrial robotics scenarios.
























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, simple explanation of the paper
What is this paper about?
This paper introduces a new collection of videos and images called the Industrial Metallic Dataset (IMD). It’s made to help robots “see” shiny, metal parts in factories. The main goal is to measure and improve how well computer programs can figure out where an object is and how it’s turned in 3D space—this is called 6-DoF (6 degrees of freedom) pose estimation.
To picture 6-DoF: imagine holding a wrench. A robot needs to know:
- Where it is in space (left/right, forward/back, up/down)
- How it’s rotated (tilted, rolled, or turned around)
Most past datasets show everyday, non-shiny objects (like plastic bottles or toys). Those are easier for cameras and AI. But real factory parts are often metallic, smooth, and reflective—much harder to see and track. IMD fills that gap.
What questions did the researchers ask?
In simple terms, the paper asks:
- Can today’s best vision models still work well on shiny, metal, texture-less factory parts?
- How much harder are industrial scenes compared to everyday scenes?
- Which methods are best at:
- Finding the object in each frame of a video (segmentation)
- Following its position and rotation over time (pose tracking)
- Estimating its 3D pose from single images after seeing it once (one-shot pose estimation)
How did they do the research?
Building the dataset
They collected videos of 45 real metal parts you might find in a factory. Each part has a 3D CAD model (a precise digital shape). They recorded:
- 55 different scenes, with different object layouts (single objects, similar shapes grouped together, random groups, and all objects mixed)
- Two camera views: straight down (top-down) and angled at 45 degrees
- About 200 frames per view, using a color+depth camera (RGB-D) attached to a robot arm
- Natural indoor lighting to keep real-world reflections and shadows
In total: 110 videos and 256 labeled object sequences.
An RGB-D camera is like a normal camera plus a distance sensor. It records color and how far things are from the camera.
Labeling the data
They created two “ground truth” labels for every frame:
- Segmentation mask: exactly which pixels belong to the object (like coloring in the object)
- 6D pose: the object’s exact position and rotation in 3D
How they did it:
- First, they used a powerful segmentation tool (SAM2) to get initial object masks, then refined them by aligning the object’s CAD model to the image and adjusting details by hand.
- For pose, they used the robot’s precise measurements of the camera and object positions to compute the true 3D pose in each frame, and then polished it manually for best accuracy.
Testing existing tools
They evaluated well-known methods without extra training:
- Segmentation: XMem and SAM2
- 6D pose tracking: BundleTrack and BundleSDF
- One-shot 6D pose estimation: adapted versions of BundleTrack and BundleSDF
They also compared performance on common everyday-object datasets:
- Segmentation on DAVIS-2017
- Pose estimation on YCB-Video
To judge quality, they used:
- IoU (Intersection over Union) for segmentation: how much the predicted object pixels overlap the true ones
- Translation error (in millimeters): how far the predicted position is from the true position
- Rotation error (in degrees): how different the predicted rotation is from the true rotation
What did they find, and why is it important?
1) Segmentation (finding the object in each frame)
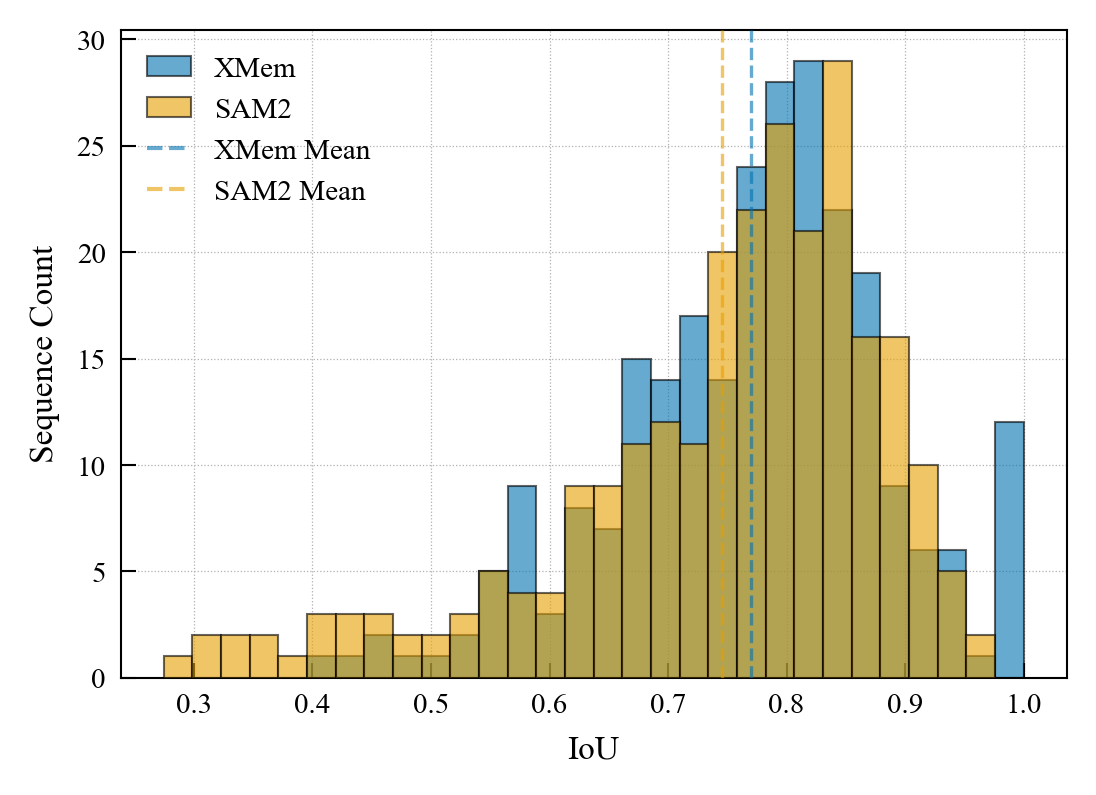
- SAM2 beat XMem on both everyday scenes and industrial scenes.
- Both models did worse on IMD than on everyday videos. Shiny, low-texture metal surfaces are harder to segment.
- Takeaway: industrial metallic objects are a tougher test. Even strong models drop in accuracy.
2) 6D pose tracking (following position and rotation over time)
- BundleTrack generally did better than BundleSDF on tracking across datasets.
- Both struggled more on IMD than on everyday YCB-Video.
- The 45-degree angled view was much harder than top-down. Big viewpoint changes and reflections made tracking less reliable.
- Takeaway: tracking industrial parts is challenging, especially from slanted angles that create more reflections and fewer visible features.
3) One-shot 6D pose estimation (estimate pose in separate single images after a short “warm-up” video)
- BundleSDF worked better than BundleTrack in this “one-shot” setting. BundleTrack often failed here.
- Even so, one-shot was noticeably worse than continuous tracking, especially for rotation.
- Performance dropped further on the IMD dataset compared to everyday objects.
- Takeaway: estimating pose from single frames of shiny, texture-less parts is very hard with current methods.
Why are shiny metal parts so tough?
Two big reasons:
- Depth sensors struggle on reflective surfaces, so distance measurements get noisy or missing.
- Feature matching (finding distinctive points on an object across images) fails on smooth, texture-less metal, so the model can’t “lock on” to the same places frame-to-frame.
What does this mean for the future?
- IMD gives researchers a realistic, challenging benchmark for factory settings. It sets a new “test track” to see what works and what doesn’t on shiny, metal parts.
- The results show that today’s top methods don’t generalize well from household objects to industrial ones, especially with angled views and one-shot use.
- This will push the community to build new algorithms that handle reflections, low texture, and tough lighting—critical for jobs like bin picking, machine tending, and precise assembly.
- Over time, better performance on IMD should lead to more reliable, flexible factory robots that can handle real parts in real conditions.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research:
- Limited lighting diversity: data captured only under natural indoor daylight; lacks controlled illumination variations (direction, intensity, spectra), high dynamic range, and polarization to systematically study specular highlights.
- Single sensor modality: only Intel RealSense D405 RGB-D used; no comparison across ToF, structured-light, LiDAR, stereo variants, polarized RGB, multi-exposure HDR, or multi-sensor fusion.
- Unquantified depth reliability: no measurement of depth noise, missing data rates, or confidence maps on reflective metals; no per-material or pose-dependent depth quality characterization.
- Restricted object materials: focus solely on metallic parts; excludes common industrial non-metals (plastics, rubber, composites) and semi-specular/painted finishes, limiting material-domain generalization analysis.
- Static objects only: objects remain stationary; no sequences with object motion, robot-manipulated parts, dynamic occluders, or motion blur to reflect real pick-and-place and bin-picking workflows.
- Narrow viewpoint coverage: only top-down and 45-degree camera paths at close range; lacks grazing angles, far-field viewpoints, varied baselines, and off-nominal camera poses (tilt/roll/jitter).
- Simplistic backgrounds: all scenes on a matte-gray tabletop; no textured conveyors, bins, cluttered industrial backgrounds, or visually distracting fixtures to test segmentation robustness.
- Occlusion not systematically controlled/annotated: no per-frame visibility or occlusion ratios; no protocols that vary occlusion levels to assess method breakdown points.
- No symmetry/pose-ambiguity labels: dataset lacks BOP-style ambiguity/symmetry annotations; evaluation uses raw TE/RE that can penalize symmetric objects unfairly.
- Non-standard pose metrics: evaluation omits ADD/ADD-S, VSD, 2D reprojection error, and mAP@thresholds used in BOP; limits comparability with established benchmarks.
- Ground-truth pose uncertainty unreported: robot–camera–object calibration pipeline lacks quantified error bounds, validation experiments (e.g., fiducial scans), and uncertainty propagation to GT poses.
- Potential segmentation GT bias: masks are sometimes adopted from SAM2, risking evaluation bias toward SAM2; lacks fully independent, multi-annotator masks and inter-annotator agreement analysis.
- No train/val/test protocol: dataset used only for testing; no standardized splits or cross-scene splits for reproducible training and generalization studies.
- Limited baselines: segmentation limited to XMem and SAM2; pose to BundleTrack/BundleSDF. Missing evaluations of FoundationPose, OnePose/OnePose++, PoseMatcher, DenseFusion, PoseCNN, and recent category-/CAD-based methods.
- “One-shot” setup not strict: uses 50% of a video for initialization rather than a single template view or CAD; not aligned with canonical one-shot definitions; unclear comparability to OnePose-style protocols.
- Initialization robustness untested: trackers assume perfect initial mask and pose; no experiments with noisy initialization, partial masks, or missing depth in the first frame.
- Failure handling asymmetry: sequences where BundleSDF fails are excluded; BundleTrack resets to image center on failure. Lacks standardized success rates, failure penalties, and re-localization metrics.
- Missing per-object and factor analyses: no breakdown by geometry (thin/reflective/symmetric), size, finish/roughness, or occlusion level; no correlation studies between factors and error.
- No reflectance/BRDF characterization: surface finish (polish/roughness/anisotropy) is neither measured nor annotated; cannot relate specularity to failure modes or enable reflectance-aware modeling.
- No RGB vs depth ablations: absent studies on RGB-only, depth-only, and RGB-D contributions, or feature-match vs photometric alignment trade-offs under specularity.
- Limited dataset scale: 45 objects, 256 sequences may be small for training large models; unclear object/category diversity sufficiency or long-tail coverage for generalization.
- Cross-domain learning untested: no experiments training on IMD and testing on other industrial datasets (e.g., T-LESS, ITODD), or vice versa, nor domain adaptation/bias mitigation baselines.
- Reproducibility details missing: no public links, licensing terms, BOP-compatible data format specification, or code/scripts for evaluation pipelines.
- No downstream robotics validation: lacks grasping/manipulation experiments quantifying task success sensitivity to pose errors; no success-rate vs TE/RE thresholds for practical relevance.
- Runtime/resource profiling absent: no standardized benchmarking of inference time, memory, and energy on edge/industrial hardware to assess deployability.
- Multi-object tracking/pose not evaluated: per-object sequences avoid ID association and interaction challenges in multi-object, cluttered industrial scenes.
- Active perception unexplored: no studies on planned viewpoints, adaptive illumination (e.g., polarizers, cross-polarization), or exposure control to mitigate specular failures.
- Missing scene metadata: no per-frame metadata for occlusion ratio, specularity intensity, depth missing rate, ambient light; limits diagnostic analysis and targeted training.
- Short sequences for drift analysis: 200-frame clips may be insufficient to assess long-horizon drift, loop-closure tracking, or persistent occlusion recovery.
- Uncertainty not evaluated: methods’ confidence/uncertainty estimates and calibration (e.g., rotation/translation covariance) are not reported or benchmarked.
Practical Applications
Immediate Applications
The following applications can be deployed now using the IMD dataset, the reported baselines, and the paper’s data collection/annotation pipeline.
- Industrial robot cell validation and acceptance testing for metallic parts — Sectors: robotics, manufacturing
- What: Use IMD to benchmark and validate vision pipelines (segmentation + 6D pose) during cell bring-up for bin picking, machine tending, and assembly on metallic, low-texture, reflective parts.
- How/Tools/Workflows:
- Use SAM2 for higher segmentation accuracy when memory allows; fall back to XMem for lower-latency/low-memory devices.
- Prefer top-down camera mounting to reduce pose errors (as evidenced by improved metrics vs 45° view).
- Define acceptance criteria using TE/RE thresholds on IMD sequences (e.g., TE < 10 mm, RE < 10° under top-down IMD).
- Assumptions/Dependencies: Availability of RGB-D sensor; ability to provide first-frame mask/pose for tracking; metallic parts similar to IMD characteristics.
- Algorithm selection and deployment guidance for perception stacks — Sectors: software, robotics, system integration
- What: Choose tracking vs one-shot components based on application constraints (e.g., BundleTrack for tracking; BundleSDF for one-shot).
- How/Tools/Workflows:
- For continuous video streams with stable views, deploy BundleTrack; for single-frame re-localization, favor BundleSDF.
- Pair with SAM2 for segmentation if compute allows; otherwise XMem.
- Assumptions/Dependencies: Compute budget (GPU memory favors SAM2); application tolerance to latency; availability of initialization frames.
- Camera placement and motion planning guidelines for industrial perception — Sectors: robotics, automation engineering
- What: Reconfigure camera placements/trajectories to minimize oblique angles that degrade pose accuracy on reflective objects.
- How/Tools/Workflows:
- Adopt top-down configurations when possible; use IMD top-down sequences to tune trajectory and field-of-view coverage.
- Use the provided evaluation metrics (IoU/TE/RE) to quantify trade-offs between mount options.
- Assumptions/Dependencies: Mechanical feasibility of mounts; field-of-view and working distance constraints.
- Procurement benchmarking for vision components and software — Sectors: manufacturing, supply chain, QA
- What: Use IMD as a standard test suite in RFPs for cameras, lenses, lighting, and pose estimation software intended for metallic parts.
- How/Tools/Workflows:
- Require vendors to report IoU/TE/RE on IMD top-down and 45° sequences to expose performance under reflections and low texture.
- Assumptions/Dependencies: Access to IMD; agreed evaluation protocols; comparable hardware during benchmarking.
- Training and education modules for industrial robotics vision — Sectors: academia, workforce development
- What: Integrate IMD into courses/labs to teach 6D pose on challenging materials and evaluate domain shift from household to industrial objects.
- How/Tools/Workflows:
- Provide students with SAM2/XMem, BundleTrack/BundleSDF baselines and grading rubrics based on IMD metrics.
- Assumptions/Dependencies: Course compute resources; licensing and access to IMD.
- Reusable annotation workflow leveraging robot kinematics + SAM2 — Sectors: research, internal dataset creation
- What: Adopt the paper’s hybrid annotation pipeline (robot-to-camera transforms + SAM2 masks + manual refinement) to label new industrial datasets quickly.
- How/Tools/Workflows:
- Apply CAD-aligned silhouette projection and centroid correction to achieve pixel-level masks and accurate 6D poses.
- Assumptions/Dependencies: Calibrated robot-camera-TCP; CAD availability; human-in-the-loop refinement.
- Synthetic data bootstrapping via CAD and measured poses — Sectors: software, simulation, ML ops
- What: Use the provided CAD models and recorded 6D poses to render photorealistic training data for metallic parts (domain randomization).
- How/Tools/Workflows:
- Render specular materials and varied daylight conditions; fine-tune segmentation/pose networks on hybrid real+synthetic sets.
- Assumptions/Dependencies: Rendering stack (e.g., Blender/Omniverse); material models for metal; sim-to-real validation on IMD.
- On-line robustness checks in production — Sectors: manufacturing, QA
- What: Monitor segmentation IoU and pose consistency (TE/RE drift) against IMD-calibrated thresholds to trigger re-initialization or safe stops.
- How/Tools/Workflows:
- Use one-shot re-localization with BundleSDF when tracking degrades; reset ROI or adjust camera exposure/lighting.
- Assumptions/Dependencies: Telemetry from perception stack; fallback routines; real-time constraints.
- Curriculum-aligned challenge datasets and leaderboards — Sectors: academia, competitions
- What: Host IMD-based challenges focusing on reflective-metal pose estimation to drive community improvements.
- How/Tools/Workflows:
- Public leaderboards for top-down and 45° tracks; baseline kits with SAM2/XMem and BundleTrack/BundleSDF.
- Assumptions/Dependencies: Hosting infrastructure; clear evaluation scripts; dataset licensing.
- Design-for-automation feedback to part designers — Sectors: manufacturing engineering, product design
- What: Use IMD-derived failure modes (symmetry, low texture, reflections) to recommend minor design tweaks (fiducials, matte patches) that improve robotic handling.
- How/Tools/Workflows:
- Run A/B tests with temporary fiducials or surface treatments; measure delta in TE/RE on IMD-like test rigs.
- Assumptions/Dependencies: Willingness to adjust parts or add removable markers; line qualification process.
Long-Term Applications
These applications are feasible but require further research, productization, or scaling beyond what the paper delivers today.
- Industrial-grade 6D pose estimation SDK optimized for metallic, reflective parts — Sectors: software, robotics
- What: A commercial SDK that consistently outperforms current baselines on specular, low-texture objects and at oblique views.
- How/Tools/Workflows:
- Incorporate physics-aware rendering for training, cross-polarized imaging, uncertainty-aware fusion of RGB + depth, and better specularity-invariant features.
- Assumptions/Dependencies: R&D on robust features for specular surfaces; sensor fusion; dataset expansion beyond IMD.
- Standards and certification for industrial perception on reflective objects — Sectors: policy, standards bodies, manufacturing
- What: Establish a certification (e.g., “IMD-compliant”) requiring minimum IoU/TE/RE across defined scenarios and camera placements.
- How/Tools/Workflows:
- Develop test protocols with top-down and 45° tracks; include occlusions, symmetry, and lighting variability.
- Assumptions/Dependencies: Multi-stakeholder agreement (vendors, integrators, standards orgs); public test suites; governance.
- Sensor and illumination co-design for metals — Sectors: hardware, photonics, robotics
- What: Co-optimized camera + lighting solutions (polarization cameras, NIR/IR active illumination, structured light tuned for metals) to stabilize depth and features.
- How/Tools/Workflows:
- Evaluate with IMD; quantify gains in TE/RE; integrate adaptive exposure/polarization control into robot cell PLCs.
- Assumptions/Dependencies: New sensor SKUs; cost and integration constraints; safety certification.
- Foundation models for industrial object pose with zero-/few-shot generalization — Sectors: AI, software
- What: Large pre-trained models that generalize to unseen metallic parts with minimal prompts (text, CAD, or a single view).
- How/Tools/Workflows:
- Leverage IMD for hard negatives; self-supervised learning from robot motion; diffusion-based synthetic data of metal optics.
- Assumptions/Dependencies: Large-scale curated data beyond IMD; compute-intensive training; robust evaluation under domain shifts.
- Closed-loop manipulation with pose uncertainty and occlusion reasoning — Sectors: robotics, manufacturing
- What: Controllers that use pose uncertainty estimates and multi-view active sensing to reliably grasp metallic parts amid occlusions/clutter.
- How/Tools/Workflows:
- Integrate belief-space planning; next-best-view policies; dynamic re-illumination to reduce specular artifacts.
- Assumptions/Dependencies: Real-time inference; robot-camera coordination; fast repositioning and safety interlocks.
- Digital twin calibration and drift monitoring using robot-vision geometry — Sectors: industrial software, QA
- What: Continuous calibration between robot kinematics and vision using IMD-like sequences to detect drift in extrinsics or camera parameters.
- How/Tools/Workflows:
- Periodic scan routines; compare predicted vs ground-truth poses; auto-compensate or alert maintenance.
- Assumptions/Dependencies: Access to calibration fixtures or known parts; scheduling downtime; management of cumulative errors.
- Domain-specific curriculum and micro-credentials for industrial vision — Sectors: academia, workforce training
- What: Certification programs focused on metallic-object perception, covering data collection, annotation via robot kinematics, and robust 6D pipelines.
- How/Tools/Workflows:
- Capstone on improving IMD baselines; industry internships; standardized practical exams.
- Assumptions/Dependencies: Industry-academic partnerships; maintained datasets; funding.
- Automated part inspection and metrology leveraging precise 6D alignment — Sectors: quality control, metrology
- What: High-precision inspection by aligning CAD to observed parts under varying reflectance, with robust pose even at 45° views.
- How/Tools/Workflows:
- Pose-driven CAD overlay; deviation maps; integrate with SPC dashboards.
- Assumptions/Dependencies: Enhanced pose accuracy on specular objects (beyond current baselines); controlled lighting; high-fidelity CAD.
- Cross-factory generalization benchmarks and federated evaluation — Sectors: manufacturing networks, policy
- What: Multi-site IMD-like benchmarks that capture lighting/material variability across facilities; federated testing for fair vendor comparison.
- How/Tools/Workflows:
- Shared metrics and scripts; privacy-preserving result aggregation; public scorecards tied to procurement.
- Assumptions/Dependencies: Data-sharing agreements; standardized capture protocols; harmonized IP/licensing.
- AR-guided maintenance and assembly with robust alignment on metallic components — Sectors: AR/VR, field service
- What: Accurate overlay of instructions on shiny, symmetric parts in real workshops.
- How/Tools/Workflows:
- One/few-shot pose estimation specialized for metals; multi-sensor fusion (IMU + RGB-D + polarizers) for stable overlay.
- Assumptions/Dependencies: Improved one-shot performance under oblique views; wearable-friendly compute; safety certification.
Notes on feasibility across applications:
- The IMD findings indicate clear performance degradation under oblique (45°) views and on reflective, low-texture metals. Immediate deployments should prefer top-down mounts and allocate compute for SAM2 where accuracy is critical.
- Depth sensing on metallic surfaces is unreliable; applications relying on RGB-D must plan for sensor fusion or lighting control.
- One-shot 6D on metallic parts remains challenging, especially under large viewpoint changes; treat it as a fallback, not a primary mode, until improved models mature.
Collections
Sign up for free to add this paper to one or more collections.