- The paper demonstrates that single-vector embedding models are theoretically limited by sign-rank constraints, making them unable to represent all top-k document combinations.
- Empirical validation on the LIMIT dataset shows that state-of-the-art models struggle with low recall scores even at high embedding dimensions.
- The findings underscore the need for alternative retrieval architectures, such as multi-vector and hybrid models, to handle complex query tasks.
Theoretical and Empirical Limits of Embedding-Based Retrieval
Introduction
This paper rigorously investigates the representational limits of single-vector embedding models in information retrieval (IR), connecting geometric and communication complexity theory to practical retrieval tasks. The authors formalize the relationship between embedding dimension and the number of top-k document combinations that can be represented, demonstrating both theoretically and empirically that current embedding models are fundamentally limited in their ability to capture all possible relevance patterns, even for simple queries. The work introduces the LIMIT dataset, a natural language benchmark constructed to stress-test these theoretical boundaries, and shows that state-of-the-art (SoTA) embedding models fail to solve it, despite its simplicity.
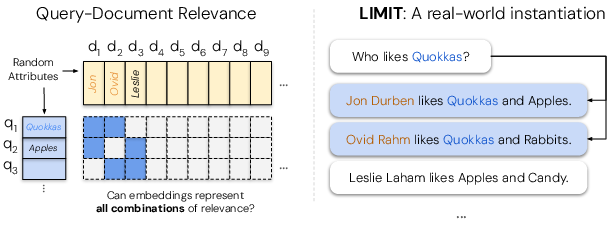
Figure 1: LIMIT dataset creation process, instantiating all combinations of relevance for N documents with k relevant per query; SoTA models score less than 20 recall@100.
Theoretical Foundations
The paper formalizes the retrieval problem as a mapping from queries and documents to vectors in Rd, with relevance determined by the dot product. The central theoretical result is that the number of distinct top-k subsets of documents that can be returned by any embedding-based model is upper-bounded by the sign-rank of the query relevance (qrel) matrix, which in turn is tightly linked to the embedding dimension d. Specifically, for any binary relevance matrix A, the minimum dimension required to realize all possible top-k combinations is at least sign-rank(2A−1)−1.
This result implies that for any fixed d, there exist retrieval tasks (i.e., qrel matrices) that cannot be solved by d-dimensional embeddings, regardless of training data or optimization. The authors provide formal definitions for row-wise order-preserving rank, row-wise thresholdable rank, and globally thresholdable rank, and prove their equivalence for binary matrices. The connection to sign-rank provides a practical mechanism for estimating the representational capacity of embedding models.
Empirical Validation: Free Embedding Optimization
To empirically validate the theoretical limits, the authors conduct "free embedding" experiments, directly optimizing query and document vectors via gradient descent to match the test qrel matrix, unconstrained by natural language. This setup represents the best-case scenario for embedding models. The experiments reveal a critical point for each d where the number of documents n exceeds the model's capacity to encode all top-k combinations. The relationship between d and the critical n is well-modeled by a cubic polynomial, with extrapolated results indicating that even large embedding dimensions (e.g., d=4096) are insufficient for web-scale retrieval tasks.
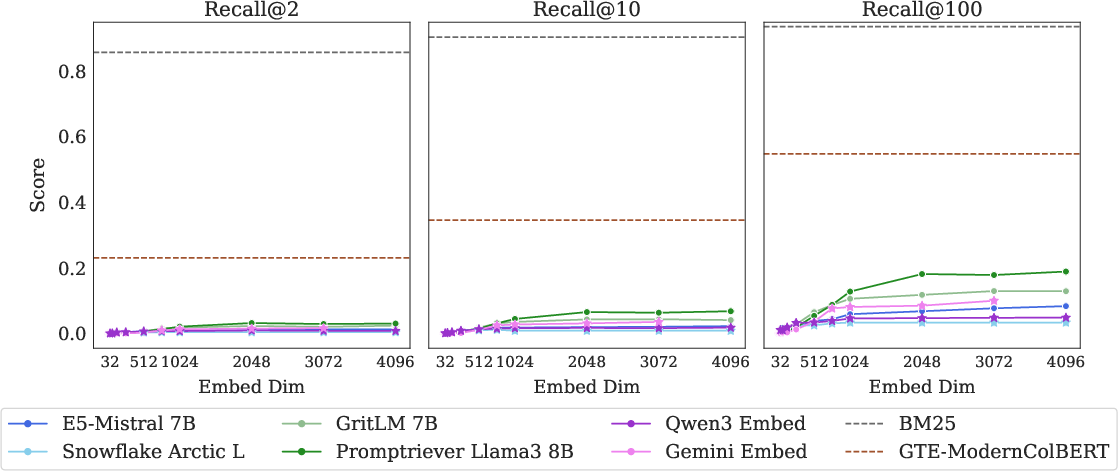
Figure 2: LIMIT task scores; SOTA models struggle, performance increases with embedding dimension, but even multi-vector models are challenged. Lexical models like BM25 excel due to high dimensionality.
The LIMIT Dataset: Real-World Stress Test
The LIMIT dataset is constructed to instantiate all possible top-k combinations for a small set of documents, using simple natural language queries (e.g., "Who likes Apples?") and documents (e.g., "Jon likes Apples"). The dataset enforces constraints for realism and statistical significance, and includes both a full version (50k docs, 1k queries) and a small version (46 docs, 1k queries).
Evaluation of SoTA embedding models (GritLM, Qwen3, Promptriever, Gemini Embeddings, Snowflake Arctic, E5-Mistral) reveals severe performance degradation: recall@100 scores are below 20% for the full LIMIT, and models cannot solve the small version even with recall@20. Performance is strongly correlated with embedding dimension, but even the largest models fail to approach perfect scores. In contrast, sparse lexical models (BM25) and multi-vector models (ModernColBERT) perform substantially better, highlighting the limitations of the single-vector paradigm.
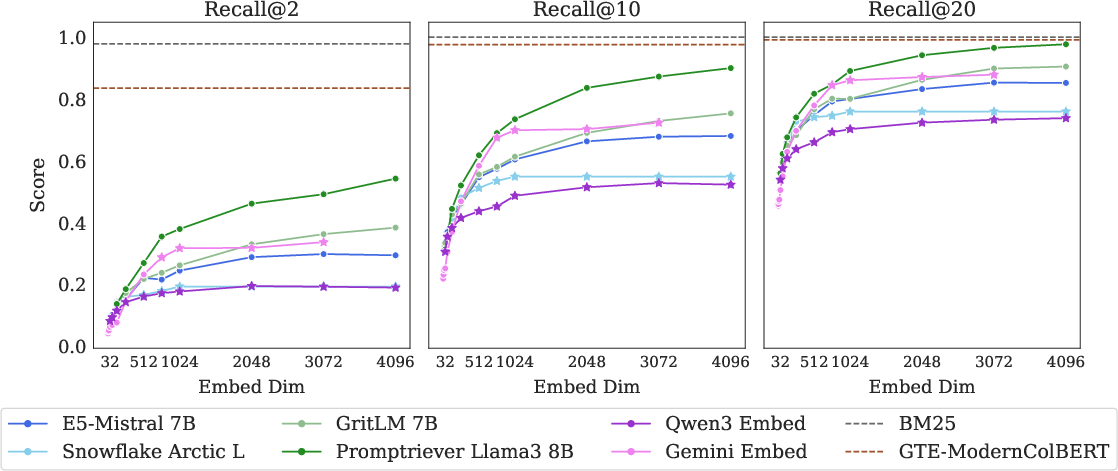
Figure 3: LIMIT small task (N=46) scores over embedding dimensions; models fail even with recall@10, cannot solve with recall@20.
Analysis of Qrel Patterns and Domain Shift
Ablation studies on different qrel patterns (random, cycle, disjoint, dense) show that the dense pattern—maximizing the number of combinations—is significantly harder for embedding models. Fine-tuning experiments indicate that poor performance is not due to domain shift; training on in-domain data yields negligible improvements, while overfitting to the test set allows models to solve the task, consistent with the free embedding results.
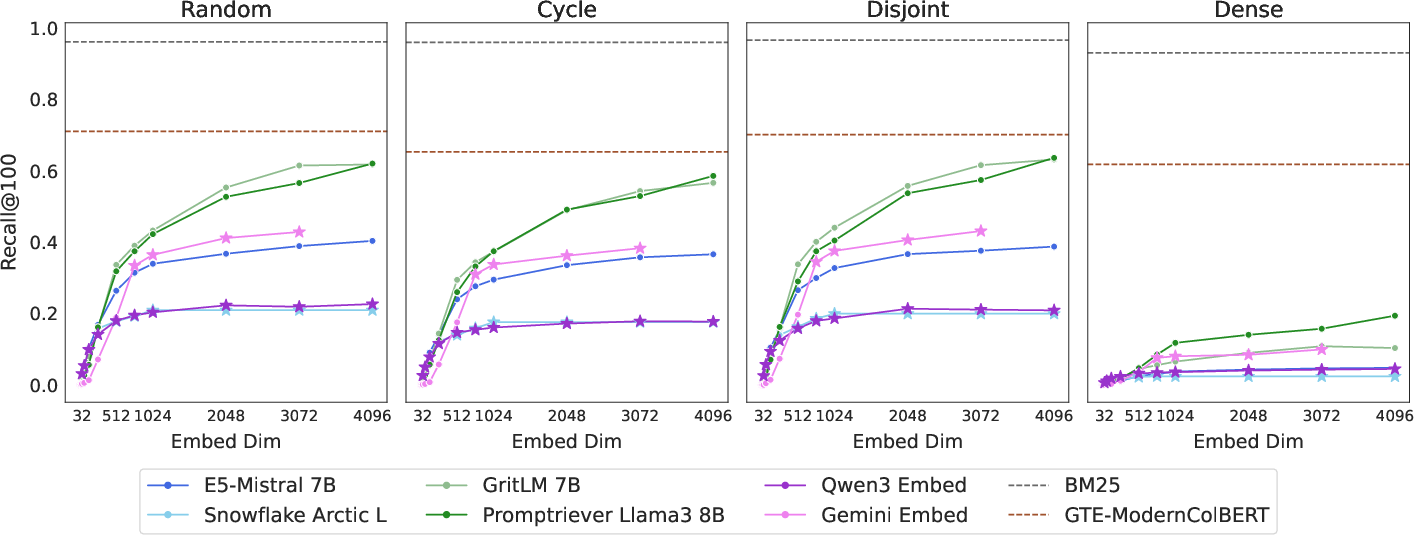
Figure 4: Model results for LIMIT datasets with different qrel patterns; dense pattern is substantially harder than others.
Implications for Retrieval Architectures
The findings have direct implications for the design and evaluation of retrieval systems:
- Single-vector embedding models are fundamentally limited in their ability to represent all possible top-k combinations, especially as tasks become more instruction-based or require reasoning.
- Sparse models (e.g., BM25) and multi-vector models (e.g., ColBERT) can represent more combinations due to higher effective dimensionality, but may not generalize to instruction-following or reasoning tasks.
- Cross-encoders and long-context rerankers (e.g., Gemini-2.5-Pro) do not suffer from these limitations and can solve LIMIT perfectly, but are computationally expensive and unsuitable for first-stage retrieval at scale.
- Instruction-following and reasoning-based retrieval will exacerbate these limitations, as the space of possible queries and relevance definitions grows.
Metrics for Qrel Matrix Density
The paper introduces metrics for qrel graph density and average query strength, showing that LIMIT is uniquely challenging compared to standard IR datasets (NQ, HotpotQA, SciFact, FollowIR Core17). Higher values for these metrics correlate with increased difficulty for embedding models, suggesting that future benchmarks should consider these properties when evaluating retrieval systems.
Conclusion
This work establishes a rigorous theoretical and empirical foundation for the limitations of embedding-based retrieval. The introduction of the LIMIT dataset demonstrates that even simple retrieval tasks can be unsolvable for current embedding models due to fundamental constraints imposed by embedding dimension. The results call for the development of alternative retrieval architectures and evaluation methodologies that account for these limitations, particularly as the field moves toward more complex, instruction-based, and reasoning-intensive retrieval tasks.
Future Directions
Theoretical extensions to multi-vector and hybrid architectures, as well as bounds for approximate retrieval (allowing some errors), remain open research questions. The community should explore new modeling paradigms and evaluation strategies that can handle the full combinatorial space of relevance definitions, especially in the context of instruction-following and agent-based search.
Limitations
The theoretical results apply primarily to single-vector embedding models; multi-vector and sparse models may not be subject to the same constraints. The analysis does not address approximate retrieval scenarios, nor does it identify which specific combinations are unsolvable. Further work is needed to generalize these findings and to develop practical solutions for large-scale, instruction-based retrieval.
References
The paper draws on foundational work in communication complexity theory, geometric algebra, and information retrieval, including studies on sign-rank, Voronoi diagrams, and empirical analyses of embedding dimension effects. The LIMIT dataset and code are publicly available for further research and benchmarking.