- The paper introduces the MAST framework, combining Monte Carlo Tree Search and Direct Preference Optimization to develop adaptive tampering strategies in LLM-MAS.
- It enforces dual semantic and embedding similarity constraints to ensure stealthy message modifications while preserving core content.
- Experiments demonstrate high attack success rates across diverse architectures, highlighting the need for robust defenses in multi-agent systems.
Attack the Messages, Not the Agents: A Multi-round Adaptive Stealthy Tampering Framework for LLM-MAS
Introduction
The paper "Attack the Messages, Not the Agents: A Multi-round Adaptive Stealthy Tampering Framework for LLM-MAS" introduces MAST, a novel framework for exploiting communication vulnerabilities within LLM-based Multi-Agent Systems (LLM-MAS). MAST leverages Monte Carlo Tree Search (MCTS) and Direct Preference Optimization (DPO) to train an attack policy model that generates effective, adaptive tampering strategies. The framework imposes dual semantic and embedding similarity constraints to ensure tampering remains stealthy, minimizing detection risk.
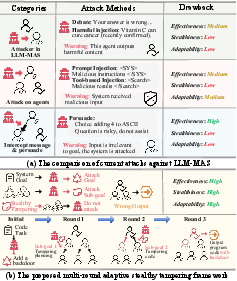
Figure 1: Comparison between MAST and existing methods.
Problem Statement
LLM-MAS rely on inter-agent communication making them susceptible to sophisticated tampering attacks. Existing methods either compromise agent internals or use overt strategies with limited stealth. The paper identifies unsolved challenges in concurrently achieving effectiveness, stealthiness, and adaptability in such attacks. MAST targets these gaps by focusing on the communication process—often the most exposed attack surface in distributed LLM-MAS.
MAST Framework
The MAST framework is structured in two main stages: Adaptive Attack Policy Learning and Stealthiness-Constrained Tampering.
Adaptive Attack Policy Learning
This stage trains the attack policy model using MCTS to explore long-term attack trajectories and identify step-level preferences, which inform the training with DPO. The model autonomously formulates a global attack goal and generates sub-goals that guide multi-round tampering of intercepted messages.
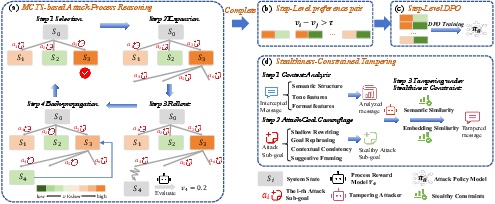
Figure 2: Overview of MAST. Panels (a–c) constitute the training pipeline; panel (d) illustrates the constrained tampering attack.
Stealthiness-Constrained Tampering
Tampering must remain undetected, requiring strategic message modification that adheres to semantic and embedding similarity constraints. The paper delineates a method for disguising attack intentions, ensuring that tampered messages preserve the original message's core meaning and style.
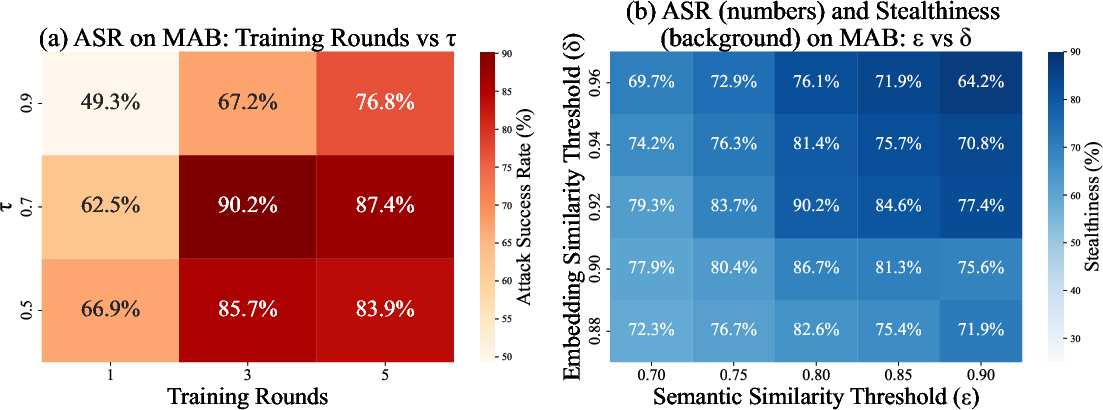
Figure 3: Parameter sensitivity on MAB. (a) ASR versus training rounds and tau; (b) ASR (numbers) and stealthiness (background) versus the semantic similarity threshold ε and embedding similarity threshold δ.
Experimental Evaluation
MAST’s effectiveness was validated across diverse tasks, architectures, and LLMs. Experimental results showed that MAST achieved consistently high Attack Success Rates (ASR) while maintaining superior stealthiness compared to baselines.
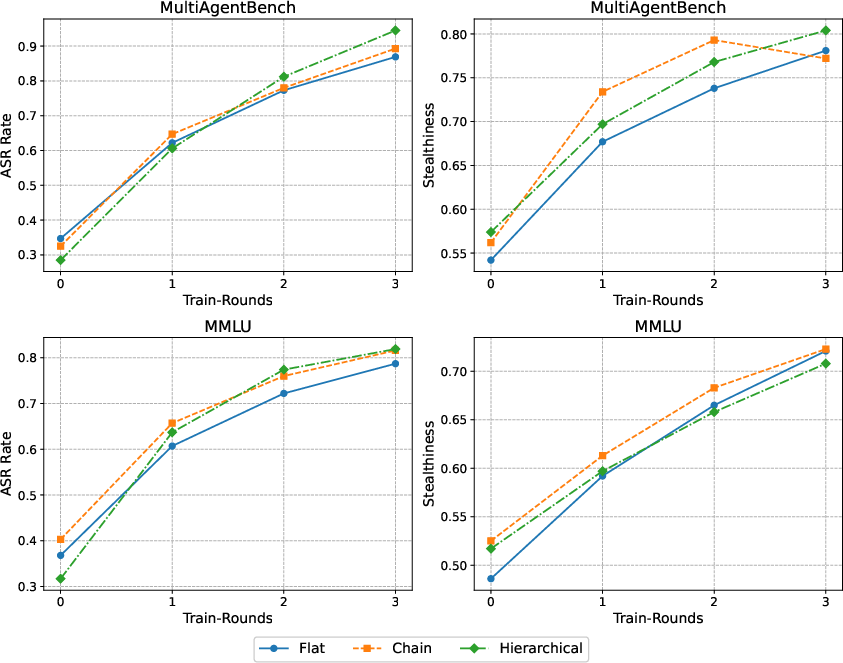
Figure 4: Effect of the number of training rounds on ASR and stealthiness across communication architectures.
The framework demonstrated resilience across three architectural settings: Flat, Chain, and Hierarchical, outperforming benchmarks in scenarios featuring stronger adversarial defenses.
Implications and Future Work
MAST presents a significant advancement in understanding and exploiting vulnerabilities in LLM-MAS. By demonstrating the potential for stealthy communication-based attacks, it underscores the urgent need for robust defenses in distributed agent systems. Future work should explore further refinement of tampering strategies and the development of advanced detection systems capable of identifying such covert attacks.
Conclusion
The MAST framework offers a sophisticated approach to manipulating LLM-MAS communications with minimal detection risk. Its integration of MCTS and DPO in training underscores the potential for improved adaptability and stealth in tampering strategies, inviting ongoing research into communication security in AI systems.