- The paper introduces a novel geospatial embedding model that unifies diverse Earth observation sources from sparse labels to outperform traditional baselines in multiple mapping tasks.
- The paper leverages a Space Time Precision encoder with self-attention and a von Mises-Fisher bottleneck to generate 64-dimensional embeddings at 10m resolution while robustly handling temporal interpolation and missing data.
- The paper demonstrates significant improvements in thematic mapping, biophysical regression, and change detection, achieving error reductions up to 23.9% and R² values as high as 0.72.
AlphaEarth Foundations: A Universal Embedding Field Model for Sparse-Label Global Mapping
Introduction
AlphaEarth Foundations (AEF) introduces a geospatial embedding model that unifies spatial, temporal, and measurement contexts from diverse Earth observation (EO) sources into a compact, information-rich feature space. The model is designed to address the persistent challenge of mapping and monitoring Earth's surface from petabyte-scale EO data, where high-quality ground-truth labels are scarce and spatially/temporally non-uniform. AEF is the first task-agnostic learned EO featurization approach to consistently outperform both designed and learned baselines across a broad suite of mapping tasks, including thematic classification, biophysical variable regression, and change detection, all without retraining or fine-tuning.
Model Architecture and Training
AEF's architecture is built to process multi-source, multi-temporal EO data and produce 64-dimensional embeddings (64 bytes per location) at 10m spatial resolution. The model ingests Ni frames from ME input sources (e.g., Sentinel-2, Sentinel-1, Landsat-8/9), each resampled to a common grid, and associates each frame with a precise timestamp. The core of the model is the Space Time Precision (STP) encoder, which combines spatial self-attention, time-axial self-attention, and convolutional operators in a spatial pyramid structure to efficiently capture both local and long-range dependencies.
Embeddings are generated via a variational bottleneck, parameterized as the mean direction of a von Mises-Fisher (VMF) distribution on the unit hypersphere S63. This enables the model to produce smooth, continuous representations that are robust to input sparsity and noise. Decoding is performed by small, source-specific MLPs that reconstruct target data (e.g., images, climate variables, categorical labels) from the embedding, conditional on metadata such as sensor geometry and timecodes.
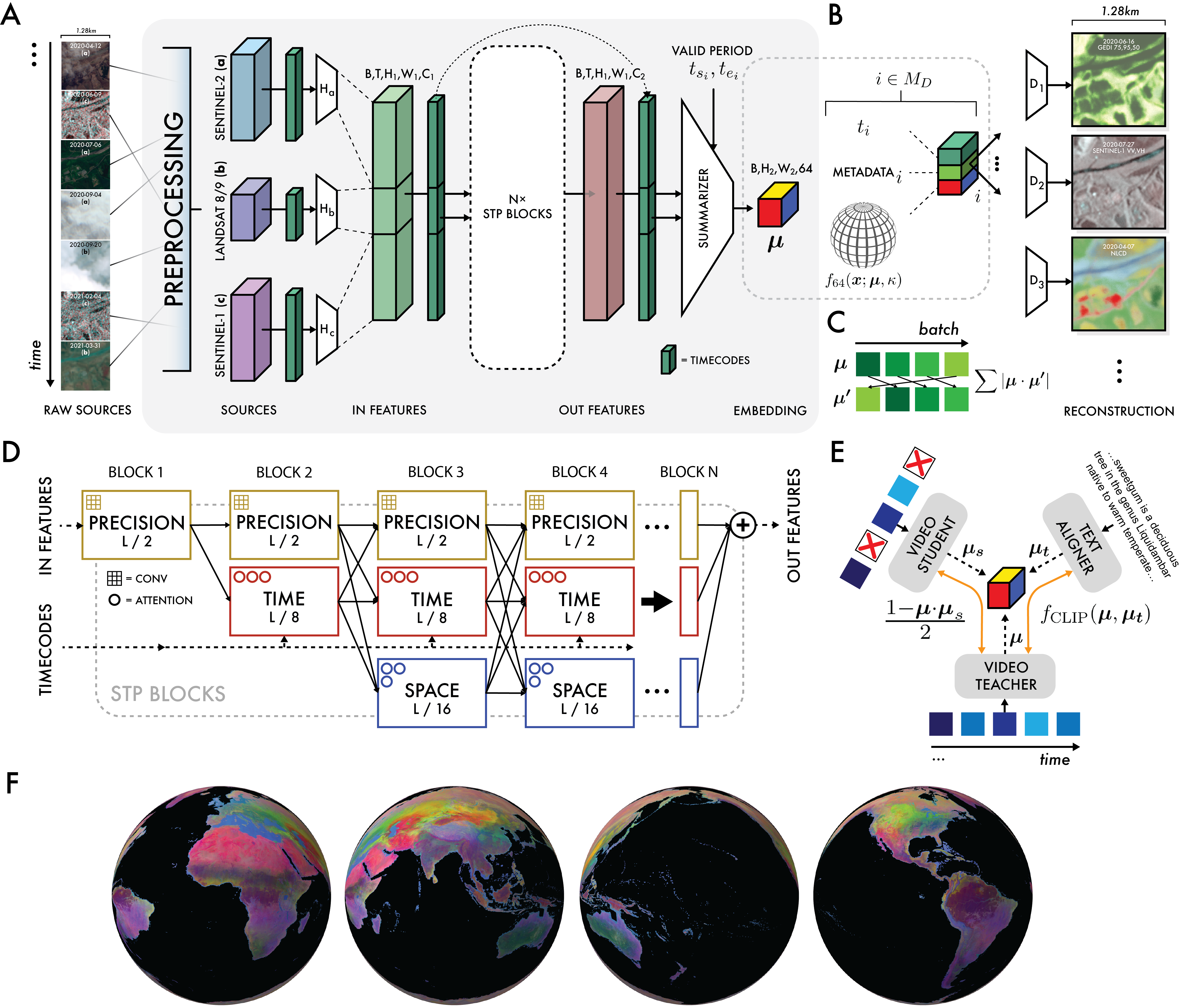
Figure 1: AlphaEarth Foundations architecture, including preprocessing, multi-source encoding, VMF bottleneck, and conditional decoding for each data source.
The training objective is a weighted sum of four terms:
- Reconstruction loss for each source (L1 for continuous, cross-entropy for categorical)
- Batch uniformity to enforce uniform embedding distribution on S63
- Consistency loss between teacher and student models under input perturbation
- Contrastive loss to align geocoded text (Wikipedia, GBIF) and video embeddings
Training utilized over 3 billion frames from 5M+ globally distributed sites, covering 1.1% of Earth's land surface, with 8,412,511 video sequences. The model was trained on 512 TPU v4 devices for 100k steps, using stochastic mini-batch gradient descent and the Adam optimizer.
Handling Sparse and Heterogeneous Data
A key innovation is the explicit separation of the "support period" (input data range) and "valid period" (temporal window for embedding summarization), enabling interpolation and extrapolation in time. The model is robust to missing or irregular data due to:
- Random dropping of sources and frames during training (student-teacher consistency)
- Decoding conditioned on available metadata, not just raw inputs
- Batch uniformity regularization to prevent embedding collapse
The architecture supports continuous-time summarization, allowing embeddings to represent arbitrary temporal intervals, a capability not present in prior EO foundation models.
Evaluation Suite and Baseline Comparisons
AEF was evaluated on 15 tasks derived from 11 high-quality, open datasets, covering:
- Thematic mapping (land use/cover, crop type, species distribution)
- Biophysical regression (evapotranspiration, emissivity)
- Change detection (annual and sub-annual)
Baselines included designed features (CCDC, MOSAIKS, composites), learned models (SatCLIP, Prithvi, Clay), and controls (XY, XYZ, ViT). All baselines were provided with identical inputs and hyperparameters were tuned for fairness.
AEF consistently outperformed all baselines across all tasks and transfer methods (kNN, linear probe), with an average error magnitude reduction of 23.9% in the max-trial setting. Gains persisted in low-shot regimes (10-shot: 10.4%, 1-shot: 4.18%), though variability increased as expected.
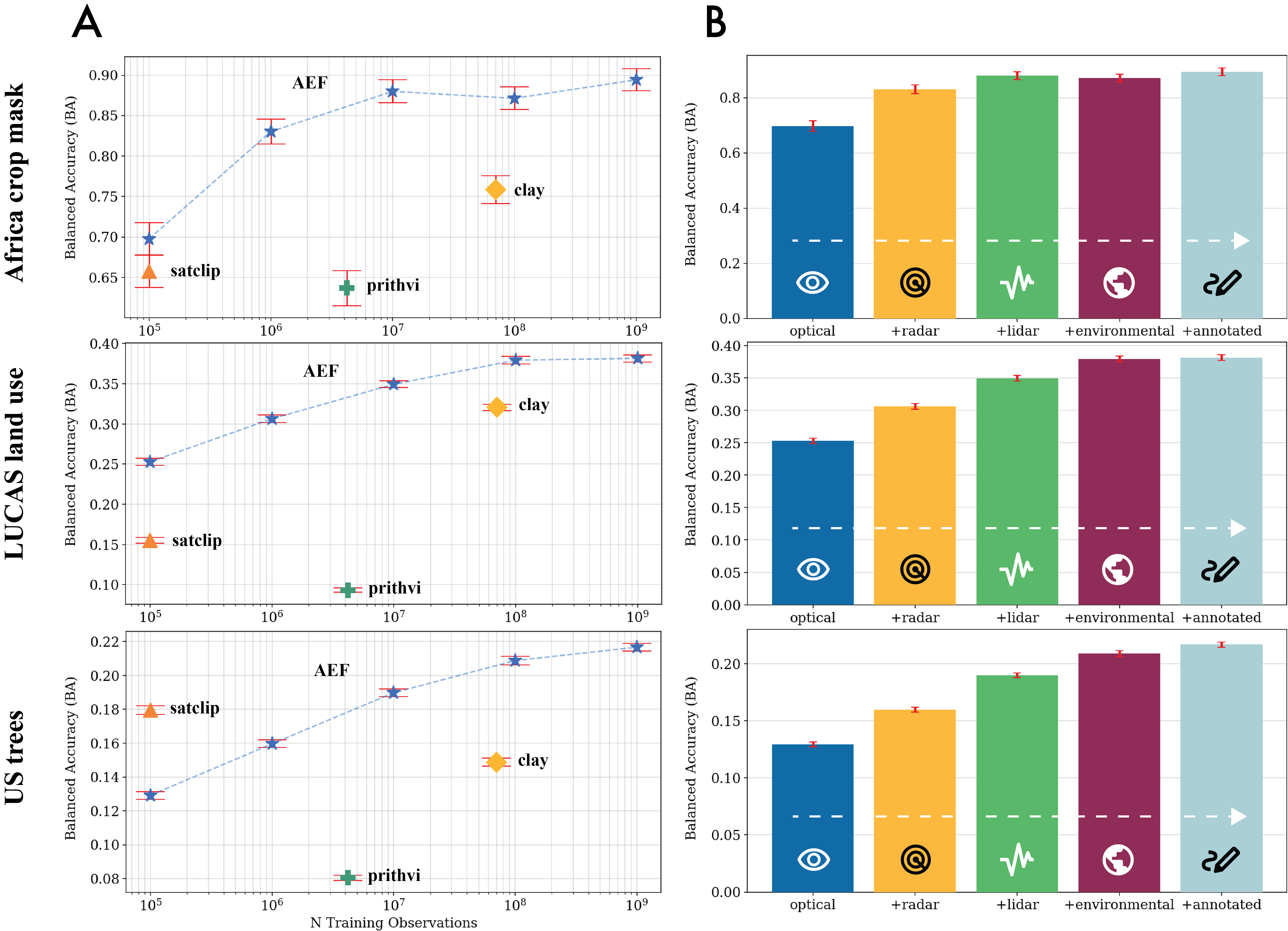
Figure 2: Effects of scaling training examples and source groups on balanced accuracy (BA) for AEF and baselines. AEF outperforms others even with fewer observations; performance saturates as more source groups are added.
Thematic Mapping and Biophysical Regression
In thematic mapping, AEF achieved the largest error reductions for annual-period tasks (e.g., LCMAP land cover, Africa crop mask), and was the only method to consistently outperform all others across diverse legends and geographies. For biophysical regression, AEF was the only approach to achieve R2>0.2 for evapotranspiration (OpenET), with R2=0.58±0.01, and the highest R2 for emissivity (0.72±0.00).
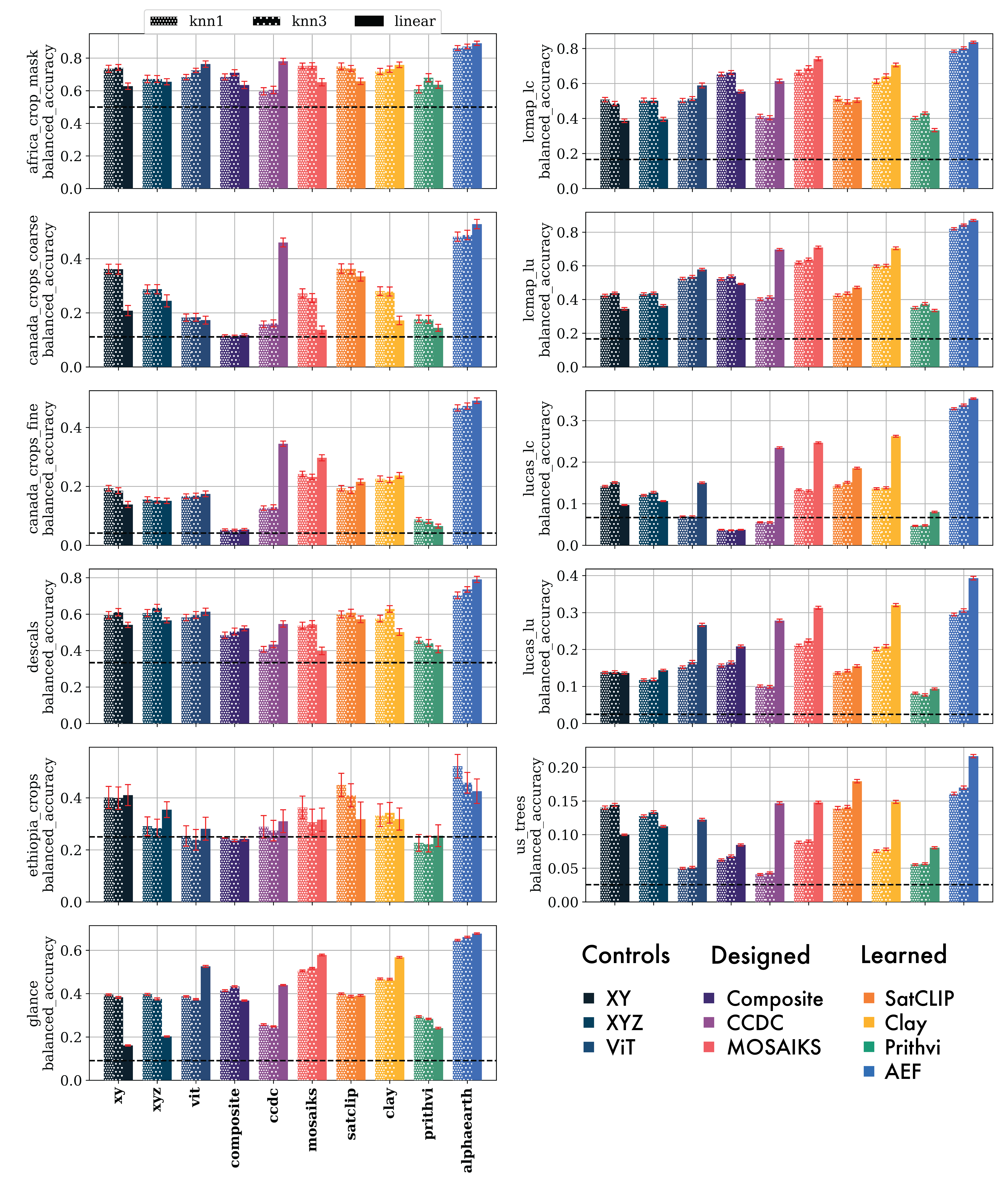
Figure 4: Classification results (balanced accuracy) for AEF and baselines across all evaluation datasets. AEF consistently exceeds random chance and outperforms all alternatives.
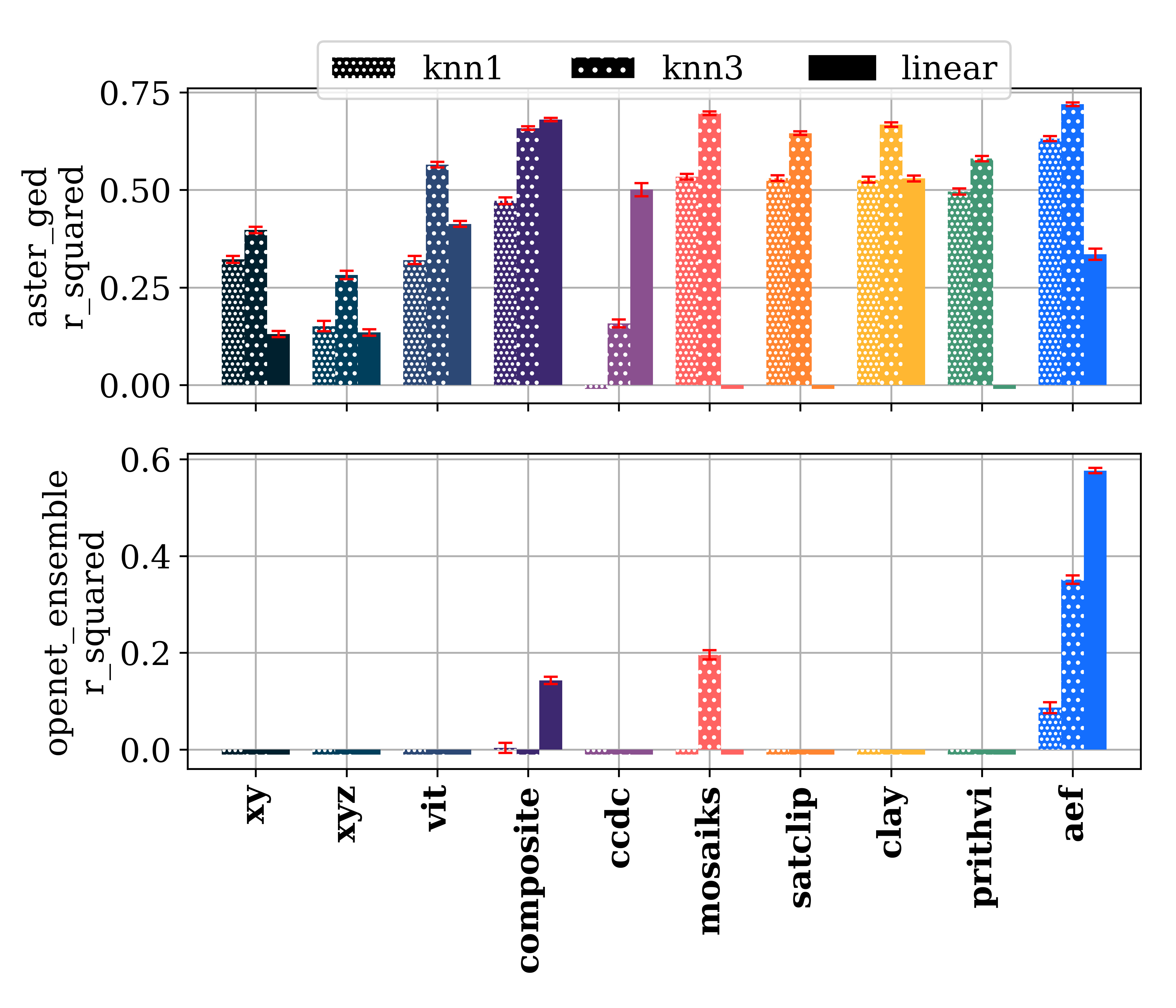
Figure 6: Regression results (R2) for AEF and baselines. Negative R2 values for most baselines on OpenET highlight the difficulty of the task; only AEF achieves substantial explanatory power.
Change Detection
For change detection, AEF achieved 78.4%±1.11 BA (linear) and 79.3%±1.67 BA (kNN, k=3) on land cover and land use change, outperforming the next-best baselines by 6–8 percentage points. In unsupervised settings, AEF also led on land cover change, though supervision remained important for land use change.
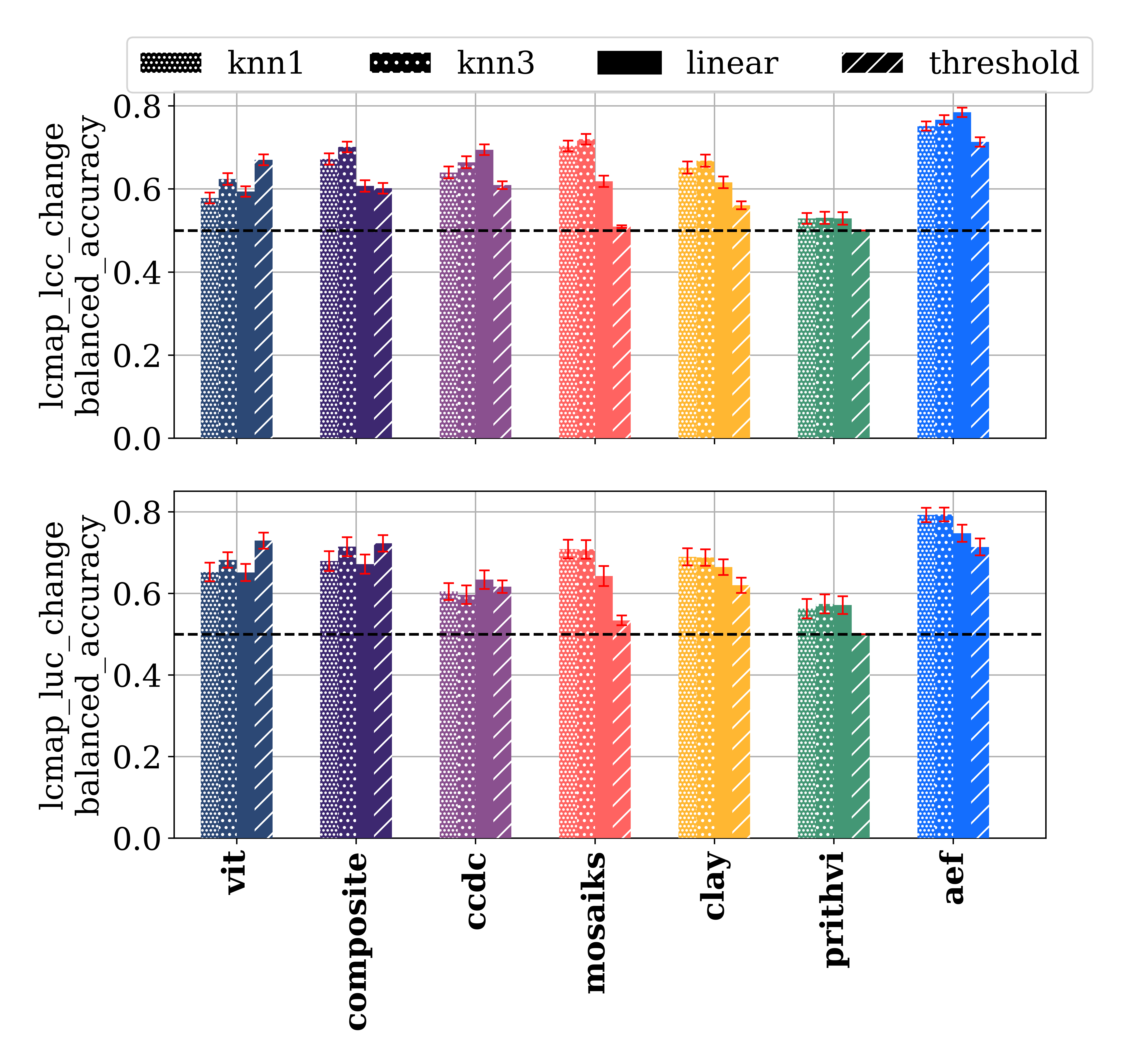
Figure 8: Change detection balanced accuracy for AEF and baselines. AEF outperforms all others, especially in supervised settings.
Scaling, Ablations, and Embedding Properties
Performance scaled monotonically with the number of unique training observations, with some tasks saturating at 100M–1B samples. Adding more source groups (optical, radar, LiDAR, environmental, annotated) improved performance, with diminishing returns after LiDAR/environmental sources for some tasks.
Ablation studies on embedding dimension and VMF κ showed that higher dimensions and lower noise benefited large-legend tasks, while noisier bottlenecks improved low-shot performance.
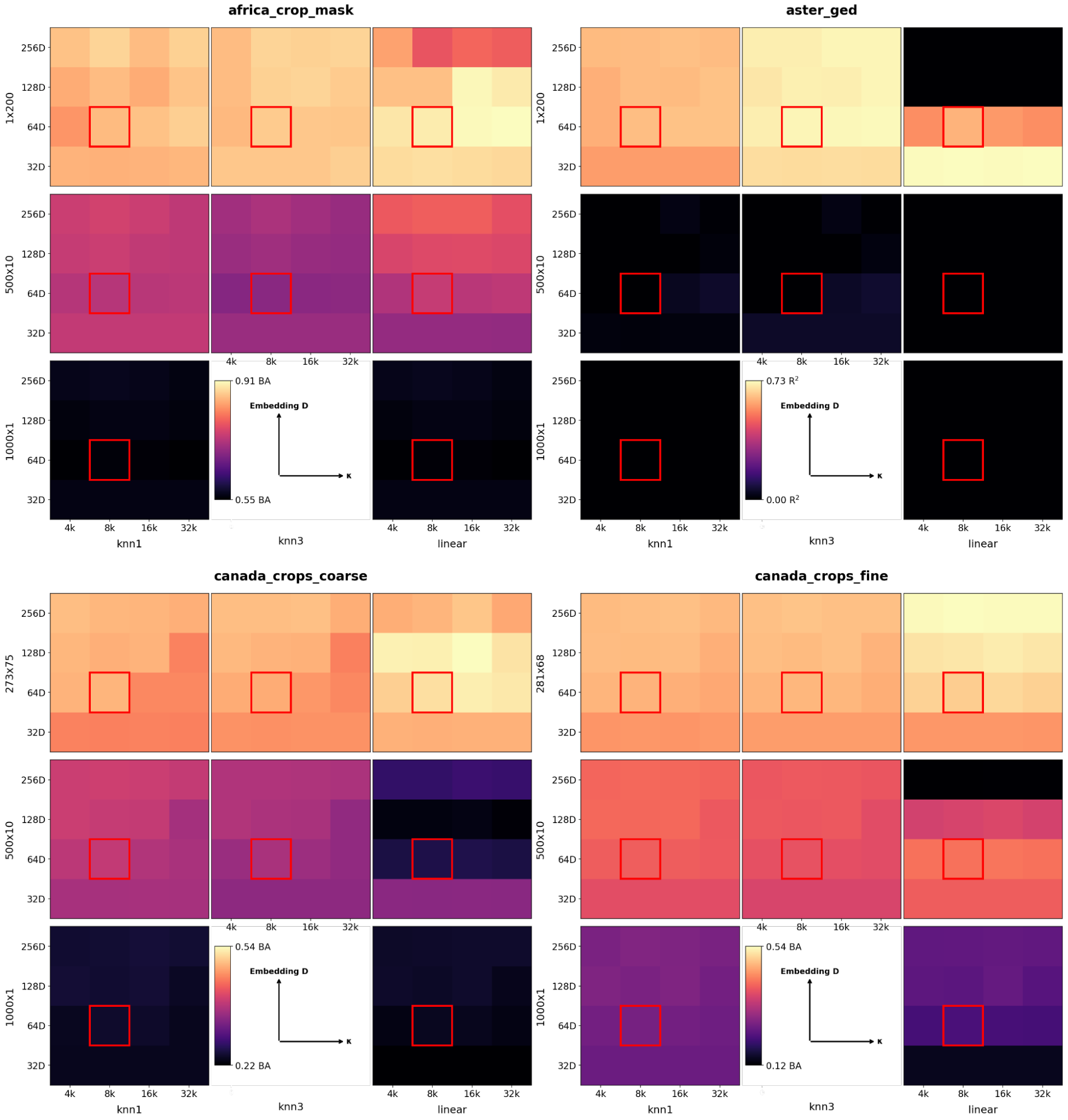
Figure 10: Evaluation performance as a function of embedding dimension and VMF κ for various transfer methods and trial sizes. The chosen setting (D=64, κ=8e3) balances capacity and smoothness.
Practical Considerations and Deployment
AEF embeddings are released as annual, global 10m grids (2017–2024) on Google Earth Engine, quantized to 8 bits for a 4x storage reduction with negligible performance loss. Inference is performed in UTM-tiled batches, with careful overtiling to avoid seams. The model requires only the minimal set of input sources (Sentinel-2, Sentinel-1, Landsat-8/9) for inference, and is robust to missing data.
(Figure 1C–F)
Figure 11: Global embedding field for 2023, showing climatic gradients and high spatial detail at 10m2 resolution.
Implications and Future Directions
AEF demonstrates that a single, compact, task-agnostic embedding field can generalize across a wide range of geospatial tasks, outperforming both hand-designed and prior learned representations, especially in sparse-label regimes. The model's ability to interpolate and extrapolate in time, handle missing data, and align with geocoded text opens new avenues for operational mapping, monitoring, and scientific discovery.
The release of annual embedding fields and evaluation datasets will enable practitioners to build accurate maps and monitoring systems with minimal labeled data and computational overhead. Future work may extend AEF to finer spatial/temporal resolutions, incorporate additional modalities (e.g., hyperspectral, SAR interferometry), and further improve robustness to input irregularities.
Conclusion
AlphaEarth Foundations establishes a new standard for universal, efficient, and accurate geospatial representation learning from sparse labels. Its architecture, training regime, and evaluation demonstrate that compact, information-rich embeddings can serve as a foundation for a wide range of EO applications, with strong empirical gains over existing methods. The open release of embedding fields and benchmarks is poised to accelerate progress in global mapping, environmental monitoring, and applied geoscience.
