- The paper introduces a system integrating vision-language models with language models to enable robots to process both verbal and non-verbal cues.
- The proposed architecture addresses the visual recognition of conversation partners, social cues, and environmental context while meeting high-resolution demands.
- Evaluation methods combine user ratings, third-party annotator feedback, and objective metrics to assess dialogue quality and interaction effectiveness.
Towards Multimodal Social Conversations with Robots: Using Vision-LLMs
Introduction
The paper addresses a significant gap in current capabilities of social robots by exploring the potential to integrate multimodal capabilities into their conversational systems. While LLMs have enabled robots to engage in open-domain verbal conversations, they often lack the capability to process non-verbal cues, which are critical for effective social interactions. The paper proposes leveraging VLMs to address this gap, enabling robots to interpret visual information alongside verbal dialogue.
System Requirements and Challenges
Social robots require the ability to process three main categories of non-verbal information during interactions: identifying the conversation partner, interpreting social cues, and understanding the environmental context. Current systems face challenges such as the subtle, fast, and context-dependent nature of social cues, depicted in Figure 1.
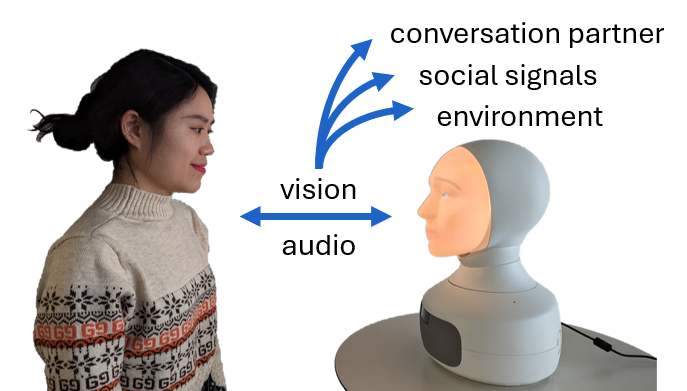
Figure 1: Overview of important information conveyed through visual and auditive channels during social interactions.
Furthermore, processing these cues demands high-resolution and high-framerate capabilities due to the fleeting nature of expressions like microexpressions, paired with the necessity for privacy-preserving data handling. The proposed architecture integrating VLMs with LLMs, shown in Figure 2, seeks to enable these capabilities while aligning the visual data with spoken words efficiently.
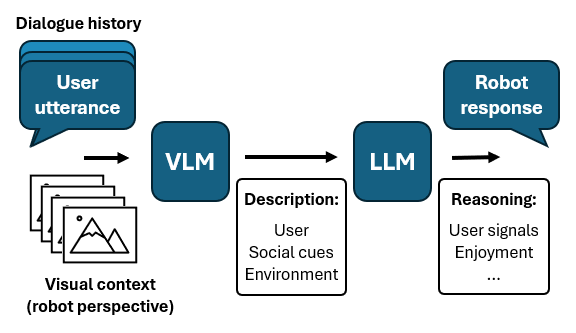
Figure 2: Proposed architecture of a multimodal adaptive social dialogue system for a social robot using a VLM and LLM.
Evaluation
Evaluating multimodal social dialogue systems is challenging, particularly in open-domain settings where the conversation is unscripted and may cover a wide range of topics. Evaluation methods could include user-rated conversations, ratings by third-party annotators on various conversational aspects, and the implementation of an "LLM-as-a-judge" method for assessing dialogue quality. Objective metrics such as turn counts and turn lengths can also be insightful for system evaluation.
Conclusion
Integrating VLMs into social robot systems promises to bridge the gap between verbal and non-verbal interactions, enhancing social dialogue capabilities. The challenges in cue recognition, processing, and maintaining privacy are formidable but critical to address for meaningful robot-human interactions. Future research should focus on refining evaluation methodologies to ensure robust and practical deployment of these systems. The implications for both theoretical advances and practical applications in AI are profound, with potential impact across diverse socially assistive roles for robots.