Published 16 Jul 2025 in cs.LG and cs.AI | (2507.12419v1)
Abstract: We introduce a Mixture of Raytraced Experts, a stacked Mixture of Experts (MoE) architecture which can dynamically select sequences of experts, producing computational graphs of variable width and depth. Existing MoE architectures generally require a fixed amount of computation for a given sample. Our approach, in contrast, yields predictions with increasing accuracy as the computation cycles through the experts' sequence. We train our model by iteratively sampling from a set of candidate experts, unfolding the sequence akin to how Recurrent Neural Networks are trained. Our method does not require load-balancing mechanisms, and preliminary experiments show a reduction in training epochs of 10\% to 40\% with a comparable/higher accuracy. These results point to new research directions in the field of MoEs, allowing the design of potentially faster and more expressive models. The code is available at https://github.com/nutig/RayTracing
The paper introduces a novel MoE architecture that dynamically selects expert sequences using a Poisson process for routing.
The design adapts computation to sample difficulty, reducing training epochs and boosting accuracy on vision benchmarks.
The approach eliminates the need for load-balancing by employing recurrent-style unfolding and a differentiable activation mask via the Gumbel-softmax trick.
Mixture of Raytraced Experts: An In-Depth Analysis
The paper "Mixture of Raytraced Experts" (2507.12419) introduces a novel Mixture of Experts (MoE) architecture that dynamically selects sequences of experts to form computational graphs with variable width and depth. This approach, termed Mixture of Raytraced Experts (MRE), contrasts with traditional MoE models that typically employ a fixed amount of computation for each sample. The authors propose an iterative training method akin to recurrent neural networks, eliminating the need for load-balancing mechanisms and demonstrating a reduction in training epochs while maintaining or improving accuracy.
Architectural and Algorithmic Innovations
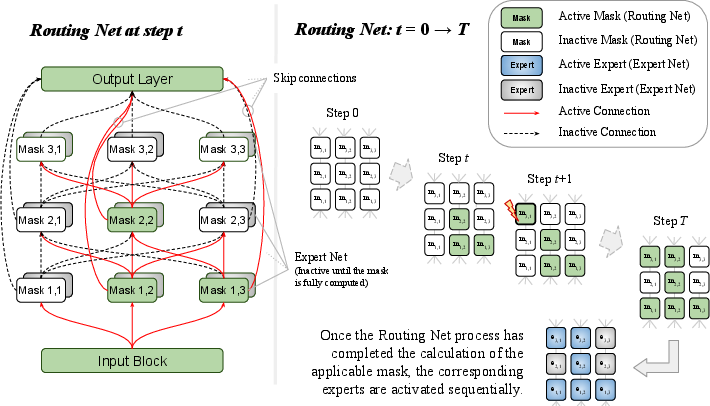
The MRE architecture, illustrated in Figure 1, centers on a routing network composed of stacked gates that govern the activation mask of the experts. An initial firing rate propagates through the routing network, activating subsequent nodes with a probability proportional to the cumulative firing rate of each unactivated node. This allows the model to identify the sequence of experts that best suits a given input, training the sequence via an unfolding process similar to that used in recurrent neural networks.
Figure 1: An iterative stochastic process determines the sequence of activated experts by computing an experts' mask: at each step, the next activated node is drawn from the eligible nodes proportionally to their firing rate.
The routing network can be conceptualized as a collection of nodes that receive activation rays originating from the initial gate(s) via a Poisson process. These rays are routed through the activated nodes, with each node's softmax function determining the probability of the ray's local route, until a yet-to-be-activated node is reached, which then becomes the next node in the activation sequence. The authors train this process efficiently by converting ray path probabilities into waiting time probabilities, representing the time until a ray activates each of the remaining nodes.
Dynamic Adjustment of Experts and Performance
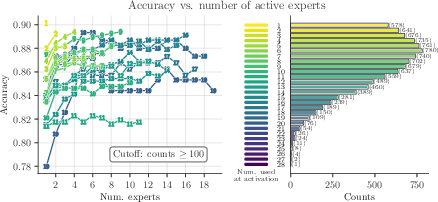
A key feature of MRE is its ability to dynamically adjust the number of experts based on the complexity of the input sample. As demonstrated in Figure 2, samples processed by fewer experts tend to achieve higher accuracy, while more complex samples benefit from the involvement of a larger number of experts. This adaptive behavior allows for a more efficient allocation of computational resources, focusing computational power on samples that require it most.
Figure 2: MRE can dynamically adjust the number of experts based on sample difficulty.
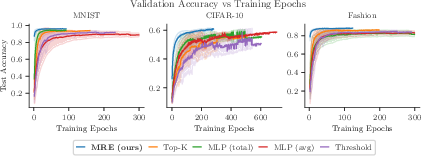
Experimental results on standard vision benchmarks (MNIST, Fashion-MNIST, and CIFAR) demonstrate the proportionality and sequential nature of the computation. The accuracy curves in Figure 2 illustrate that competitive accuracy can be achieved with significantly fewer training epochs. Furthermore, Figure 3 shows that MRE reaches higher accuracy values in fewer epochs compared to baseline models.
Figure 3: Test accuracy versus training epochs of MRE and baselines with equal learning rate set to 10−3.
Implementation Details and Routing Mechanism
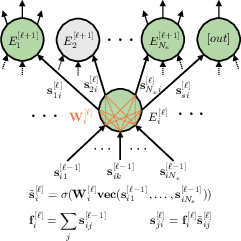
The routing mechanism, depicted in Figure 4, involves stacked and parallel softmax gates, with each expert associated with a gating node. The topology of experts and gates mirrors each other, forming a rectangular grid with L layers and Ne nodes per layer. For a given input firing rate f(0)∈ΔNe and a set of active nodes A(t)∈{0,1}L×Ne, the routing network produces a vector of firing rates $\mathbf{f}^{(t)}\inR_+^{L*N_e}$ and an output firing rate $f^{(t)}_{out}\inR_+$.
Figure 4: A pictorial representation of the routing mechanism for node i at layer ell.
Inactive nodes within the routing network do not propagate their firing rate, effectively zeroing out their outputs. This ensures that the total firing rate flowing through the network is reduced when fewer nodes are active. The routing network's weight initialization is scaled by Ne+1 to achieve higher heterogeneity, which is empirically observed to improve performance.
Expert Network and Training
The expert network consists of L layers, each containing Ne models, with all models sharing the same architecture, specifically a small MLP. The output of layer ℓ is computed as the sum of the outputs of each active expert in the layer, weighted by the activation mask Ai[ℓ]. Unlike top-k MoEs, MRE does not require weighting the experts' outputs by their corresponding probabilities, but only by the mask A, made differentiable through the Gumbel-softmax trick.
The training process unfolds the experts' sequencing in a manner similar to a recurrent neural network, taking into account the temporal dependence in backpropagation. The authors found that the results are robust with respect to the temperature parameter of the Gumbel-softmax, with a slight preference for higher, exploration-promoting values.
Experimental Results and Analysis
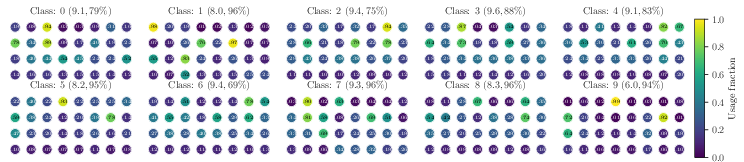
Experimental results demonstrate that MRE consistently outperforms other MoE architectures on image classification tasks. Figure 5 illustrates how the routing network effectively routes samples of different classes to different experts, while samples of similar classes are processed by similar experts.
Figure 5: Samples of different classes activate different sets of experts (Fashion MNIST).
Figure 6 shows the validation accuracy over time, indicating that MRE reaches higher values in fewer epochs compared to the baselines. The model uses a relatively small number of experts, which increases with the difficulty of the dataset.
Figure 6: Validation accuracy over training epochs for the dataset considered.
Furthermore, Figure 7 provides a difficulty analysis for a trained model on Fashion-MNIST, demonstrating a clear clustering in terms of used resources.
Figure 7: Example of difficulty analysis for a trained model on Fashion-MNIST.
Conclusion
The MRE model presents a novel approach to MoEs, utilizing a Poisson process to activate a sequence of gates corresponding to the experts' mask. This architecture achieves a balanced use of experts without requiring a load-balancing mechanism and trains with fewer epochs than comparable top-k approaches. The authors suggest that this may be due to the homogeneity of the derivatives within an MRE expert, driven by the correct formulation of the training process. Future research directions include scaling the approach to larger datasets with computationally expensive experts and further investigating the reasons for the shorter training cycle.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.