- The paper demonstrates that pre-trained LLMs can infer HMMs in-context with prediction accuracies near theoretical optima, comparable to Viterbi algorithm results.
- It employs synthetic experiments varying entropy and mixing rates to examine convergence behaviors and the impact on sequence prediction.
- LLMs show competitive performance in real-world applications such as mouse decision-making, highlighting their potential in neuroscience research.
LLMs for Hidden Markov Models In-Context Learning
Introduction
The paper "Pre-trained LLMs Learn Hidden Markov Models In-context" introduces a unique application of pre-trained LLMs for learning Hidden Markov Models (HMMs) through in-context learning (ICL). The study demonstrates that LLMs can infer patterns in sequences generated by HMMs without altering model parameters, achieving prediction accuracies near the theoretical optima. This capability extends to real-world applications, such as animal decision-making tasks, where LLMs perform competitively with domain-specific models.
Synthetic Experiments and Convergence
The paper highlights experiments on synthetic HMMs to evaluate the convergence of LLMs during ICL. HMMs, noted for their latent state-dependent sequences, serve as a challenging testbed due to their computational demands in traditional probabilistic modeling.
HMM Foundations
HMMs involve states and observations, with transitions characterized by a Markov chain and emissions dependent on the hidden states:
Experimental Setup
The experimental protocol involves generating sequences from HMMs by varying several parameters, such as mixing rates and entropy levels. Notably, LLMs are applied without explicit retraining, leveraging pre-trained capabilities for sequence prediction based on context length.
In-Context Learning Convergence
The experiments reveal that pre-trained LLMs achieve superior prediction accuracy, approaching the theoretical maximum determined by the Viterbi algorithm. This illustrates the potential of LLMs in modeling sequences with substantial latent complexity.
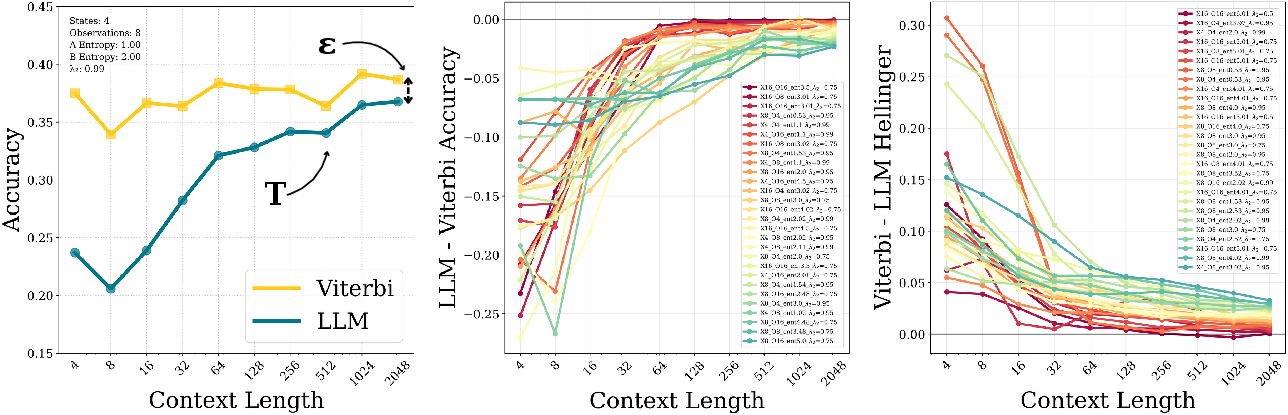
Figure 2: (Left) We define T as when LLM converges, and ε as the final accuracy gap at sequence length 2048. (Middle) Examples when LLM accuracy converges to Viterbi. Each curve represents a different HMM parameter setting. LLM ICL shows consistent convergence behavior. (Right) Examples of convergence in Hellinger distance (distance between two probability distributions).
Impact of HMM Properties on In-Context Learning
Scaling Trends
The convergence pattern is influenced by core HMM characteristics such as entropy and mixing rates:
- Context Window Length: LLM performance typically improves with longer sequences, stabilizing as the window length increases. This is crucial for capturing sufficient state information.
- Entropy: Higher entropy levels in transitions and emissions extend convergence times. LLMs display sensitivity to randomness within data, a factor that influences their learning trajectory.
- Mixing Rate: Fast-mixing settings, denoted by lower λ2, support more rapid convergence, highlighting the role of state transition dynamics.
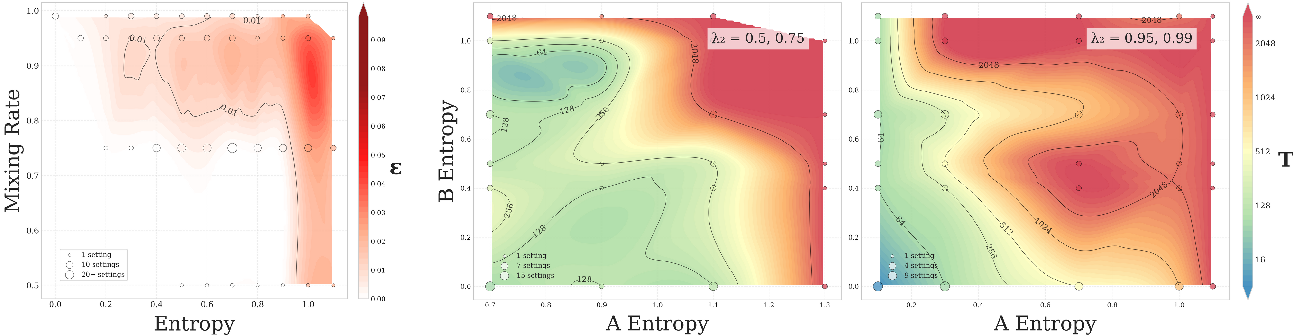
Figure 3: (Left) Convergence gap ε increases with higher mixing rate (slower mixing) and higher entropy. This plot is showing results averaged across all HMM configurations we tested. (Right) Slower mixing (λ2=0.5,0.75) shows delayed convergence compared to (Middle) fast mixing (λ2=0.95,0.99) at similar entropy levels.
Application to Real-World Tasks
Decision-Making in Neuroscience
The study's practical application involves analyzing mouse decision-making tasks, where LLMs are tested against specialized models such as GLM-HMM:
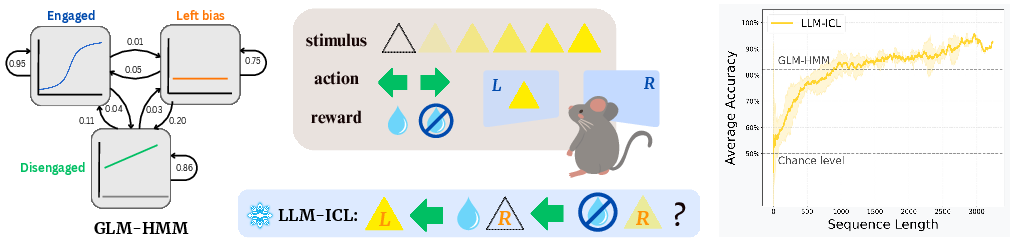
Figure 4: IBL dataset mice decision-making task. (Left) GLM-HMM model developed by neuroscientists. (Middle) A cartoon illustration of the task. A mouse observes a visual stimulus presented on one side of a screen, with one of six possible intensity levels. It then chooses a side, receiving a water reward if the choice matches the stimulus location. (Right) LLM ICL performance curve averaged across all animals, with 1-sigma error bar. Its prediction accuracy steadily increases with longer context window, exceeding the domain-specific model performance.
LLMs demonstrate competitive in-context prediction accuracy, often surpassing models engineered specifically for these tasks.
Conclusion
The research establishes LLMs as potent tools for handling complex sequential data characterized by latent stochastic processes. Their ability to learn without task-specific tuning offers a promising avenue for rapid assessments in diverse scientific fields. However, challenges persist in contexts of high entropy and slow mixing rates, which constrain predictability even for optimal methods such as Viterbi. Future work could explore extending these methods to continuous data domains and improving interpretability to foster wider application in scientific discovery.
