- The paper demonstrates that reinforcement learning finetuning inherently updates only 5%-30% of LLM parameters, revealing an intrinsic sparsity in parameter changes.
- It categorizes varying sparsity patterns across RL algorithms like PPO, GRPO, and DPO, showing consistency across layers and settings except for layer normalization.
- Empirical results confirm that fine-tuning a sparse subnetwork yields performance on par with full model finetuning, offering potential efficiency gains in RL training.
Reinforcement Learning Finetunes Small Subnetworks in LLMs
Introduction
The paper under discussion presents an in-depth study of reinforcement learning (RL) techniques applied to LLMs, specifically examining the parameter update sparsity phenomenon. The authors provide substantial evidence that RL, when used to fine-tune LLMs, predominantly updates a small subnetwork, comprising merely 5\%-30\% of the total model parameters, leaving the majority of the parameters effectively unchanged. This intrinsic sparsity has been observed across various RL algorithms and different LLM families, challenging the conventional belief that RL induces widespread parameter updates.
Parameter Update Sparsity Induced by RL
The authors demonstrate that RL-induced parameter sparsity naturally emerges without needing any explicit sparsity-promoting regularizations. They categorize and quantify the sparsity levels across different RL methodologies, notably including popular algorithms like PPO, GRPO, and DPO. The sparseness is particularly apparent when compared to supervised fine-tuning (SFT), which exhibits denser parameter updates. This sparsity is not isolated to specific layers within the model but is manifest across almost all transform layers, with the exception of layer normalization parameters which are rarely updated.
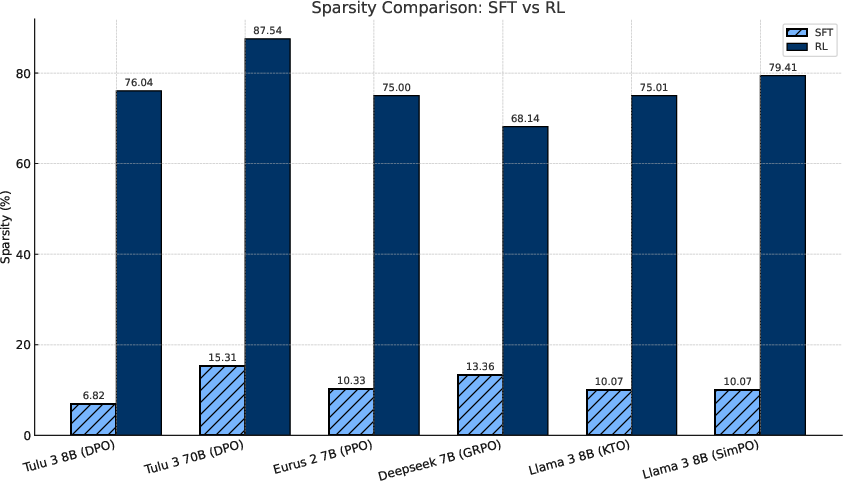
Figure 1: Comparison in accumulated gradients in the SFT stage vs RL stage for popular released checkpoints. SFT stage has accumulated much denser updates, while RL is mostly sparse.
Consistency of Subnetworks Across Different RL Settings
The research highlights the consistency of the sparsity pattern despite variations in random seeds, training datasets, and even RL algorithms. Such consistency implies the presence of transferrable structures within the pretrained networks, suggesting that the identified sparse subnetworks are not mere artifacts of specific training conditions. This insight fosters the understanding that fundamental components of pretrained models are consistently activated for specific tasks regardless of initialization and training path divergences.
A critical proposition of this study is that the subnetwork in question is not just a piece of the model but is nearly as performant as the full model post-finetuning. The authors conjecture that fine-tuning only the subnetwork, while freezing other parameters, can produce a model nearly identical to the one obtained via a full finetuning process. Empirical results show that models fine-tuned in this manner not only match but sometimes outperform their fully fine-tuned counterparts across several benchmark tests, suggesting efficiency improvements in RL training strategies.
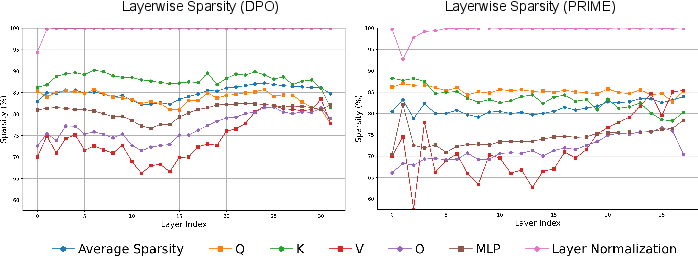
Figure 2: Layerwise and per-parameter-matrix update sparsity for DPO (left) and PRIME (right). All layers are similarly sparsely updated, with the only exception of the layer normalization layers, which receive little to no updates.
Analysis of the Causes of Sparsity
To understand the underlying causes of this sparsity, the study dissects various aspects of the RL training process. The primary reason suggested is the training on data that is near the policy distribution, reducing the necessity for substantial updates. Techniques like KL regularization and gradient clipping that keep the model parameters close to initial states were found to have a limited effect on inducing this sparsity. Additionally, the study touches upon the influence of training duration and its diminishing returns concerning update density over extended learning periods.
Implications and Future Directions
The findings of this paper open new avenues for developing more efficient RL algorithms by capitalizing on the observed update sparsity. It suggests that future research could focus on optimizing RL methods to explicitly target these sparse subnetworks, potentially reducing empirical training costs substantially while preserving or even enhancing performance metrics.
Conclusion
This work presents a significant investigation into the parameter update dynamics of LLMs during RL finetuning, revealing intrinsic sparsity in parameter updates and the sufficiency of subnetworks. Such insights fundamentally shift the understanding of RL interactions with LLMs, providing both a new understanding of the existing paradigms and directions for future research to enable more efficient and effective finetuning processes.