- The paper presents a unified autoregressive framework that predicts skeleton structures and skin weights using transformer-based tokenization.
- It leverages a novel skeleton tree tokenization with a 27-30% reduction in sequence length, preserving topological constraints for diverse 3D assets.
- Empirical results demonstrate over 215% improvement in rigging accuracy and 194% in motion accuracy compared to existing academic and commercial systems.
A Unified Rigging Pipeline for Diverse 3D Assets: Insights into UniRig
Introduction and Context
The increasing complexity and heterogeneity of 3D models—driven by both generative methods and traditional content creation—poses substantial challenges for automated rigging pipelines. Existing methods predominantly fall into template-based or template-free frameworks. Template-based methods offer stable results on standard topologies but lack generality, while template-free approaches have greater expressive capacity but often generate topologically inconsistent skeletons. Furthermore, a significant segment of production workflows demand explicitly defined skeletons and skinning for subsequent animation, effectively limiting the applicability of skeleton-free mesh deformation techniques.
UniRig addresses these challenges by introducing a unified, autoregressive framework for skeleton (bone) prediction and skin weight assignment, leveraging both a novel skeleton tree tokenization mechanism and a large diverse dataset (Rig-XL). The approach substantially outperforms both academic and commercial rigging systems, supporting generalization across categories including humanoids, quadrupeds, organic, and non-organic forms.
Rig-XL and VRoid: Dataset Foundation
The curation and enrichment of dataset resources is instrumental to UniRig's performance and generality. The Rig-XL dataset contains over 14,000 rigged models, meticulously filtered, deduplicated, and categorized into eight object types. Both algorithmic and manual interventions were employed to ensure topological correctness and diverse representation, while VRoid provides a high-quality, human-centric corpus for learning fine-grained anatomy and spring bone behavior.

Figure 1: Examples from Rig-XL, demonstrating well-defined skeleton structures.
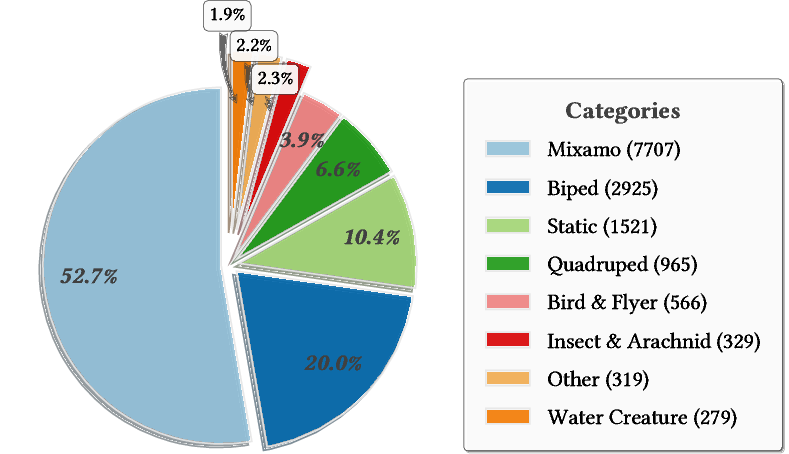
Figure 2: Category distribution of Rig-XL. The percentages indicate the proportion of models belonging to each category.
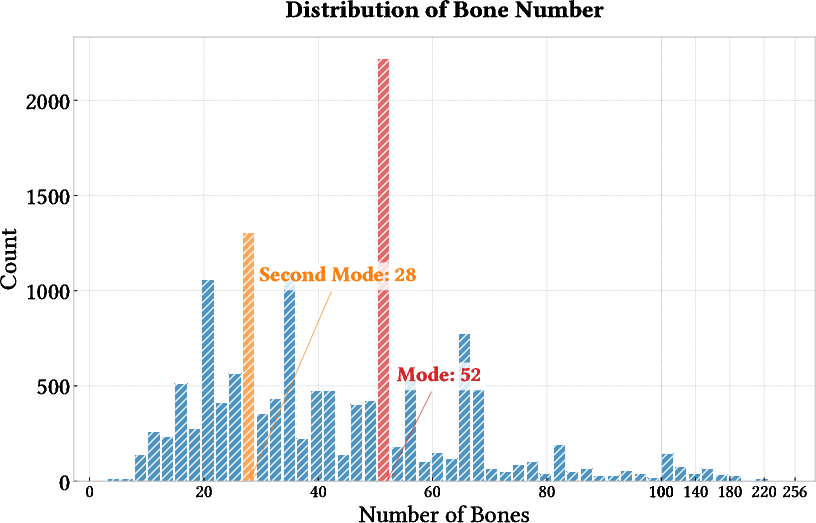
Figure 3: Distribution of bone numbers in Rig-XL. The histogram shows the frequency of different bone counts across all models in the dataset.
Rig-XL's diversity in both the semantic and structural attributes of skeletal configurations is critical for training a model capable of performing well on non-canonical, highly articulated, or fragmented topologies.
UniRig Framework and Skeleton Tree Tokenization
The UniRig architecture consists of two principal modules: (1) an autoregressive transformer-based skeleton generator, and (2) a cross-attention skin weight estimator. The skeleton predictor operates on point clouds derived from mesh surfaces, exploiting a purpose-built tokenization scheme to serialize tree-structured skeletons as sequences amenable to transformer training.
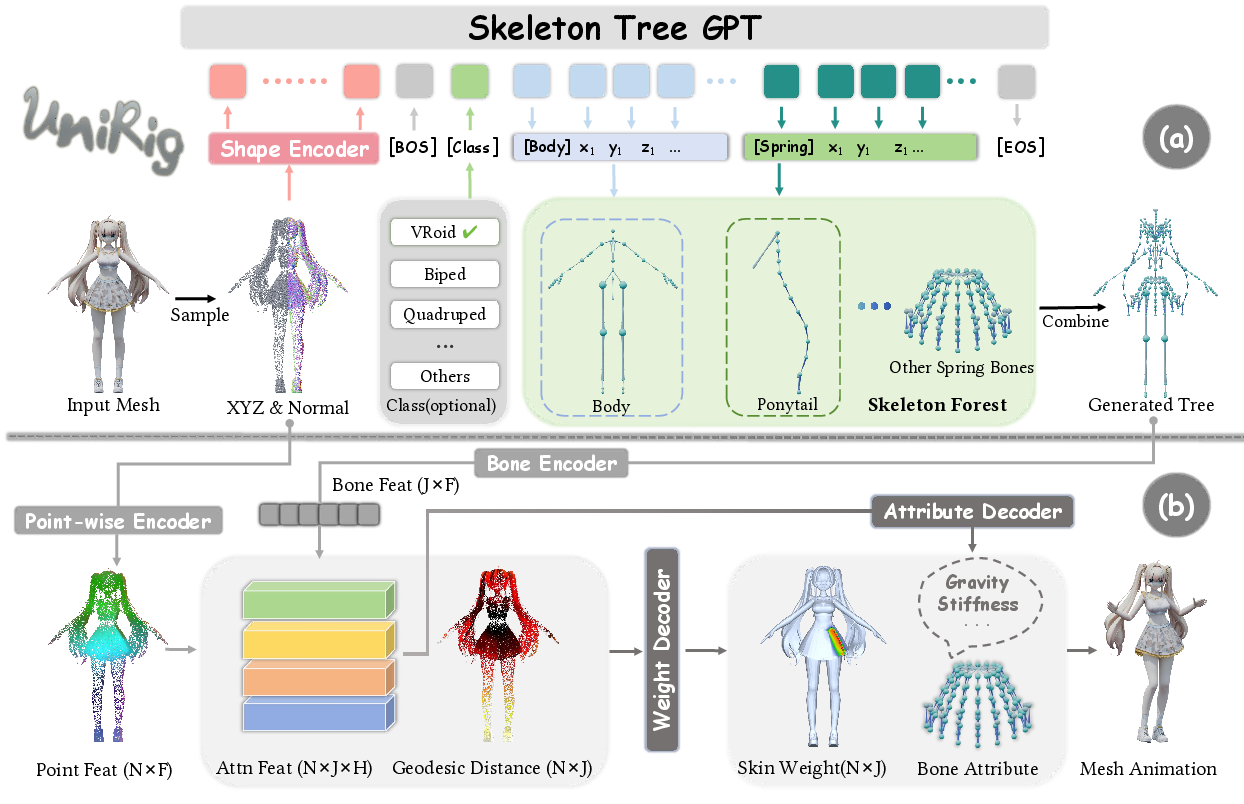
Figure 4: Overview of the UniRig framework.
A compact tokenization is achieved by introducing special tokens to encode parent-child, spring, and template (e.g., Mixamo) relationships, combined with coordinate discretization. Ablation studies show over 27–30% reduction in sequence length and marked gains in skeleton prediction accuracy and inference speed. This approach not only preserves topological constraints but also provides explicit hooks for downstream tasks such as retargeting and user-guided editing.
Skinning Weight Generation via Bone-Point Cross-Attention
Skinning weights are generated through a hybrid pipeline that uses pretrained point encoders and MLP-encoded bone descriptors, fused with a bone-point cross-attention mechanism. Geodesic distance priors are injected to inform the model of spatial relationships between bones and mesh vertices, addressing issues encountered in previous methods that rely on purely geometric proximity or local features.
The system incorporates indirect supervision derived from physically-based simulation (Verlet integrators for spring bones and LBS for core skeletons). This enables the model to optimize not only for direct weight matching (KL and L2 losses), but also for downstream fidelity in motion—a critical practical requirement in animation pipelines.

Figure 5: Comparison of model animation with and without spring bones. The model on the left utilizes spring bones, resulting in more natural and dynamic movement of the hair and skirt.
Empirical Results and Analysis
Skeleton and Skin Weight Accuracy
Quantitative and qualitative evaluations on Mixamo, VRoid, and Rig-XL datasets demonstrate that UniRig achieves an order-of-magnitude reduction in J2J joint error and L1 skin error relative to RigNet, NBS, and commercial platforms (Tripo, Meshy, Accurig):
- Rigging accuracy improvements exceed 215% and motion accuracy improvements top 194% compared to prior systems, especially on challenging or out-of-distribution instances.
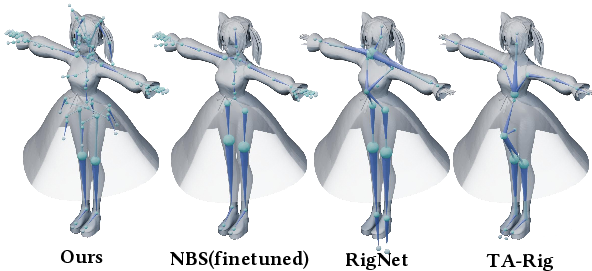
Figure 6: Comparison of predicted skeletons between NBS (fine-tuned), RigNet, and TA-Rig on the VRoid dataset. UniRig generates skeletons that are more detailed and accurate.
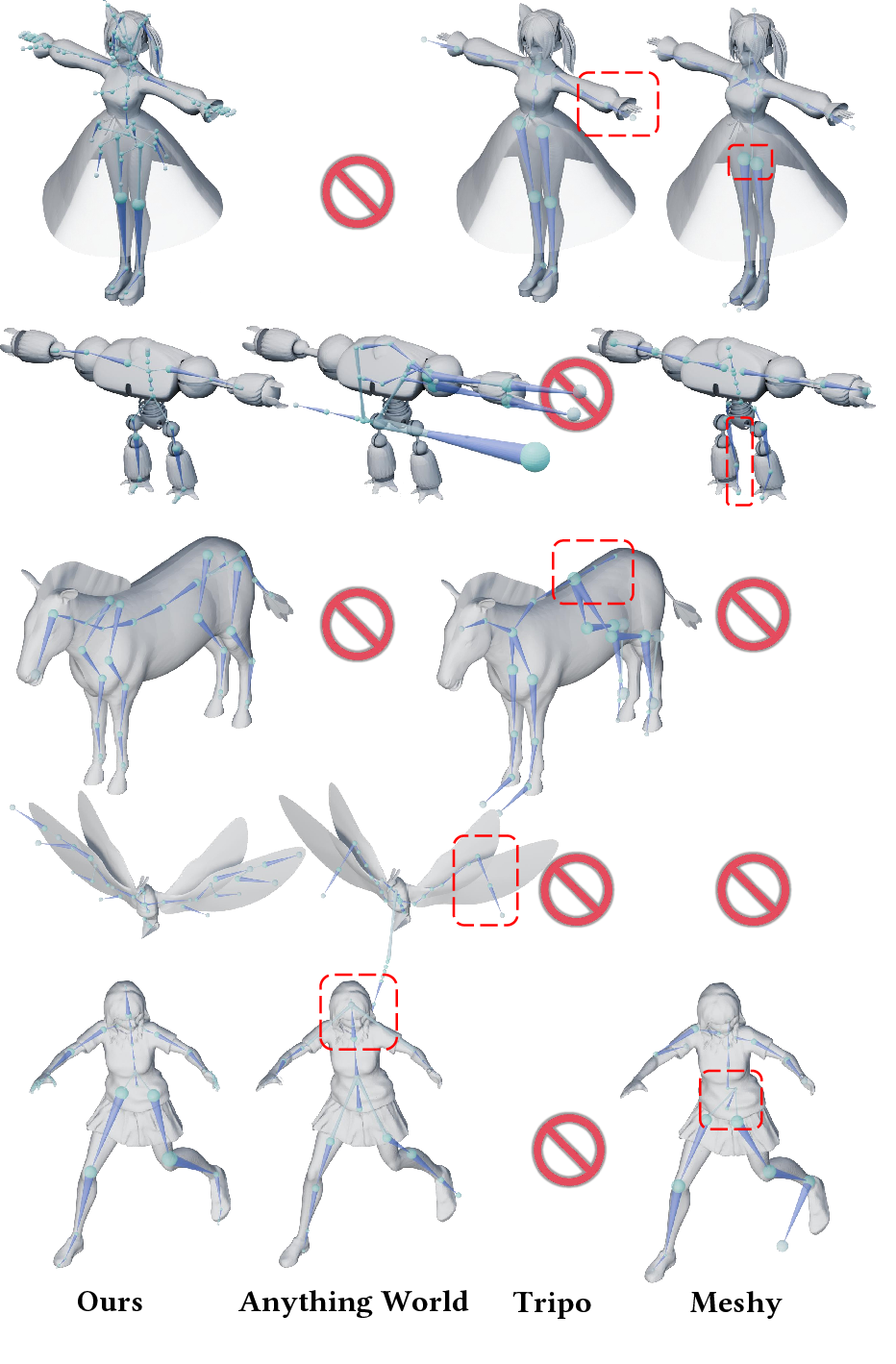
Figure 7: Qualitative comparison of predicted skeletons against commercial tools. UniRig outperforms Tripo and others in terms of accuracy and detail.
UniRig not only recovers detailed hand or appendage weights but also generates spring bone parameters that under physical simulation yield visually realistic, dynamic deformations critical for hair, clothing, and secondary motion.
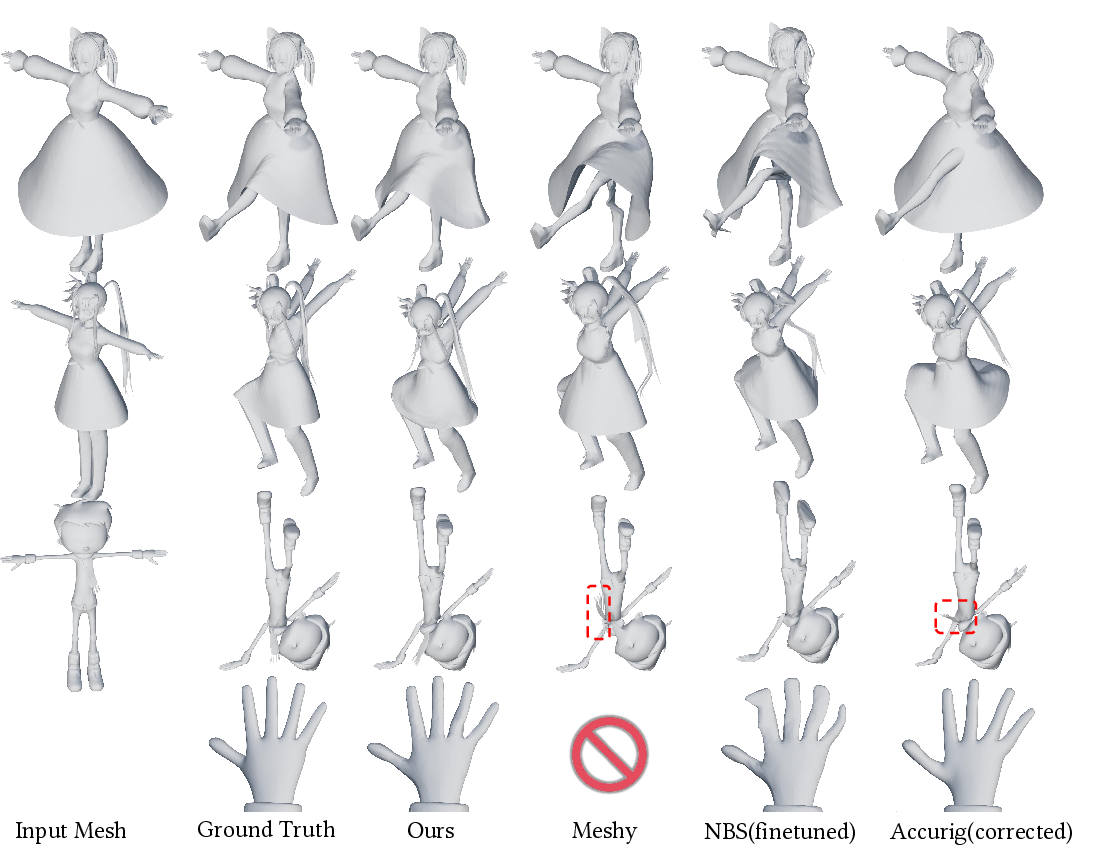
Figure 8: Qualitative comparison of mesh deformation under motion. UniRig is compared with Meshy, Accurig, and NBS on multiple models, showing robust behavior in hands and hair simulation.
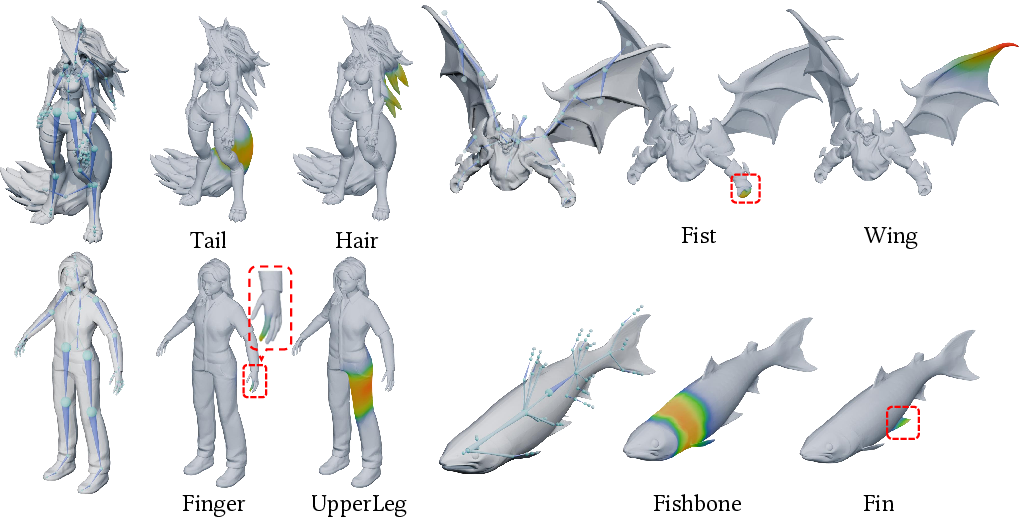
Figure 9: Qualitative results of UniRig on various object categories, demonstrating both detailed skeletons and accurate skin weight mappings.
Detailed ablations confirm the effect of the physical simulation for training supervision and the critical role of balanced, skeleton-aware sampling strategies in improving weight generalization—particularly for sparsely influencing bones.
Editability and Human-in-the-Loop Interactive Rigging
A salient feature of UniRig is the seamless integration of user edits: predicted skeletons can be interactively edited and then regenerated in a manner consistent with both template and free-form structures. This supports production workflows where artists refine baseline auto-rigs for specialized animation needs.
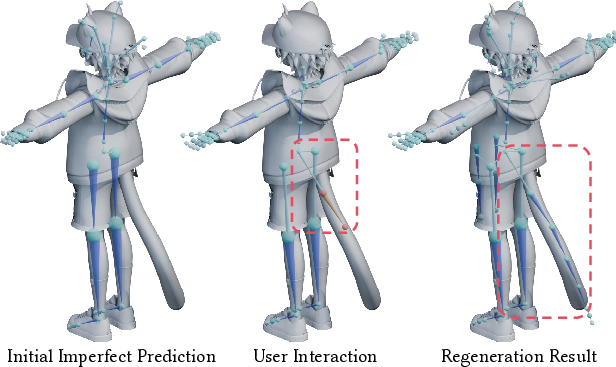
Figure 10: Human-assisted skeleton editing and regeneration—initial prediction is edited by removing spring bones and prompting for a tail; regeneration yields the modified skeleton.
Deployment and Practical Impact
UniRig directly enables end-to-end, scriptable auto-rigging workflows for 3D content creators, real-time avatars, and VTuber applications. The framework's ability to automatically configure both canonical and secondary (spring) structures—coupled with VRM compatibility—alleviates significant labor costs in 3D pipeline production and allows for rapid prototyping across character, animal, robotic, and abstract assets.

Figure 11: VTuber live streaming with a UniRig-generated model in Warudo, showcasing dynamic spring bone-driven animation.
Limitations and Future Directions
Despite generalization across a broad range of categories, UniRig exhibits the same inductive biases as its training data. Performance on radically out-of-domain or highly stylized models is expected to degrade unless the dataset and fine-tuning strategies are further expanded. Another limitation is the reliance on explicit mesh input—incorporating visual (image/video) or textual conditionings for rig prediction remains an open avenue.
Potential future extensions include:
- Direct conditioning on multi-modal cues (image/video-driven rigging or annotation-free mesh-to-rig pipelines)
- Incorporation of advanced simulation paradigms for enhanced physically-based animation
- Continuously learning from user corrections, creating active learning feedback loops
Conclusion
UniRig represents a scalable, template-agnostic solution for automatic 3D rigging, grounded in robust transformer-based skeleton parsing, efficient tokenization, and physically informed cross-modal weight generation. Its empirical superiority over existing academic and commercial systems demonstrates both the strength of the learning pipeline and the foundational impact of the Rig-XL dataset. This work sets a benchmark for auto-rigging research and provides essential infrastructure for accelerating animation, virtual character, and 3D content production across domains.
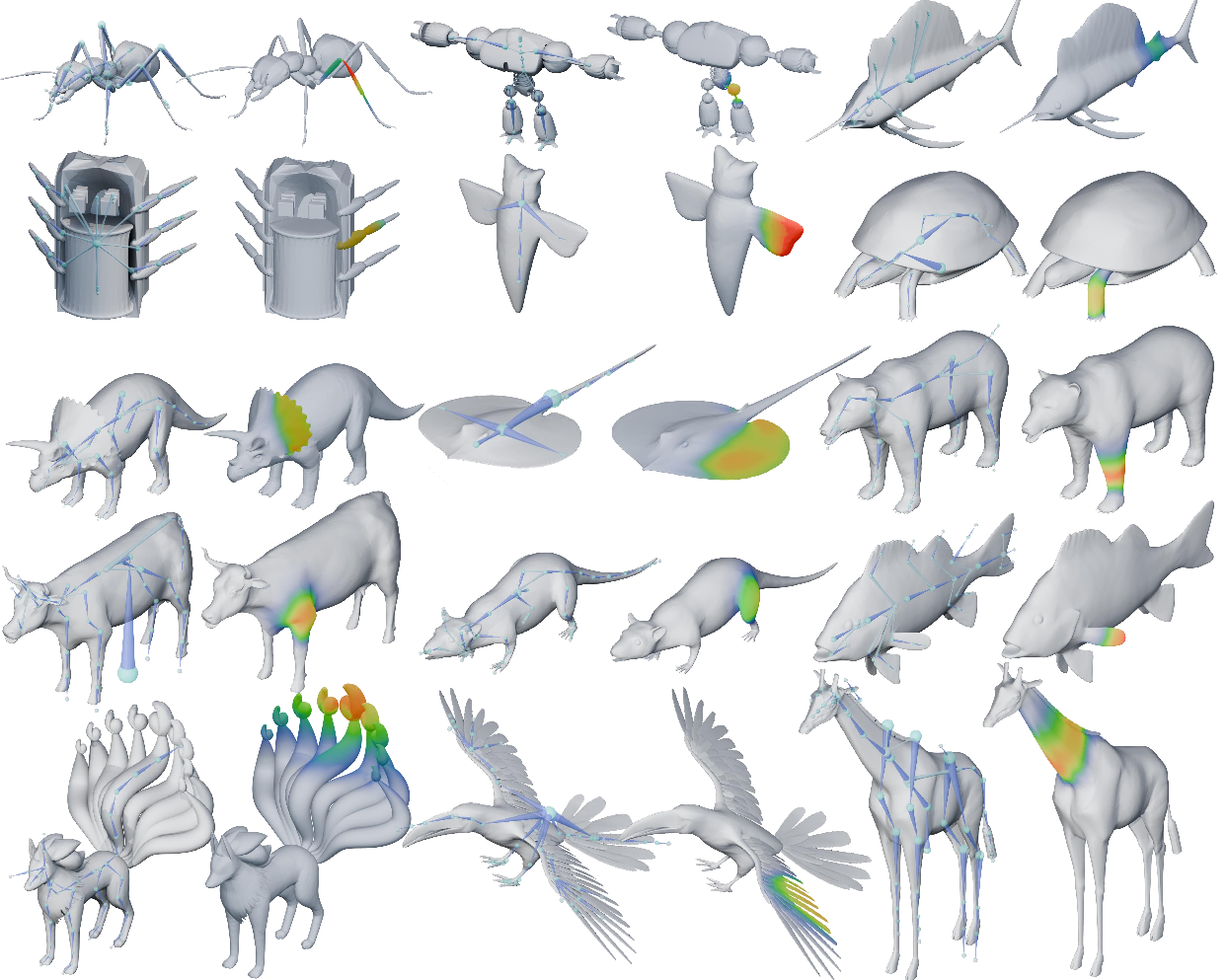
Figure 12: Additional examples illustrating detailed and accurate skeleton rigging and skin weight estimation by UniRig._

