- The paper presents a multilingual QA dataset of 96M Q&A pairs across 75 languages, advancing dense retrieval with innovative filtering and duplicate detection methods.
- It leverages schema.org annotations along with fastText and XLM-RoBERTa for effective language detection and question type classification.
- Experiments demonstrate that fine-tuning retrieval models on WebFAQ leads to substantial improvements over baselines like BM25 in zero-shot settings.
WebFAQ: A Multilingual Collection of Natural Q&A Datasets for Dense Retrieval
Introduction
The paper "WebFAQ: A Multilingual Collection of Natural Q&A Datasets for Dense Retrieval" presents a large-scale, open-domain dataset collection of question-answer pairs. Derived from schema.org annotations, WebFAQ comprises 96 million QA pairs across 75 languages, with a significant portion representing non-English samples. The dataset is designed to advance research in multilingual dense retrieval models, offering refined benchmarks through extensive filtering and duplicate detection.
Dataset Construction and Structure
WebFAQ capitalizes on structured § org annotations prevalent in FAQ-style datasets, facilitating the extraction of natural QA pairs from Common Crawl snapshots. By leveraging schema.org annotations, which embed rich metadata, WebFAQ not only catalogues several languages but also categorizes them based on topics and question types, providing a multidimensional dataset for diverse retrieval tasks.

Figure 1: Exemplary FAQ entries across languages.
Processing and Challenges
The dataset encompasses a wide array of topics, requiring sophisticated preprocessing techniques to manage near-duplicate questions and generic answers. Language detection employs fastText to classify the extracted pairs into 75 languages, while the question type classification utilizes XLM-RoBERTa to ensure robustness across multilingual domains.
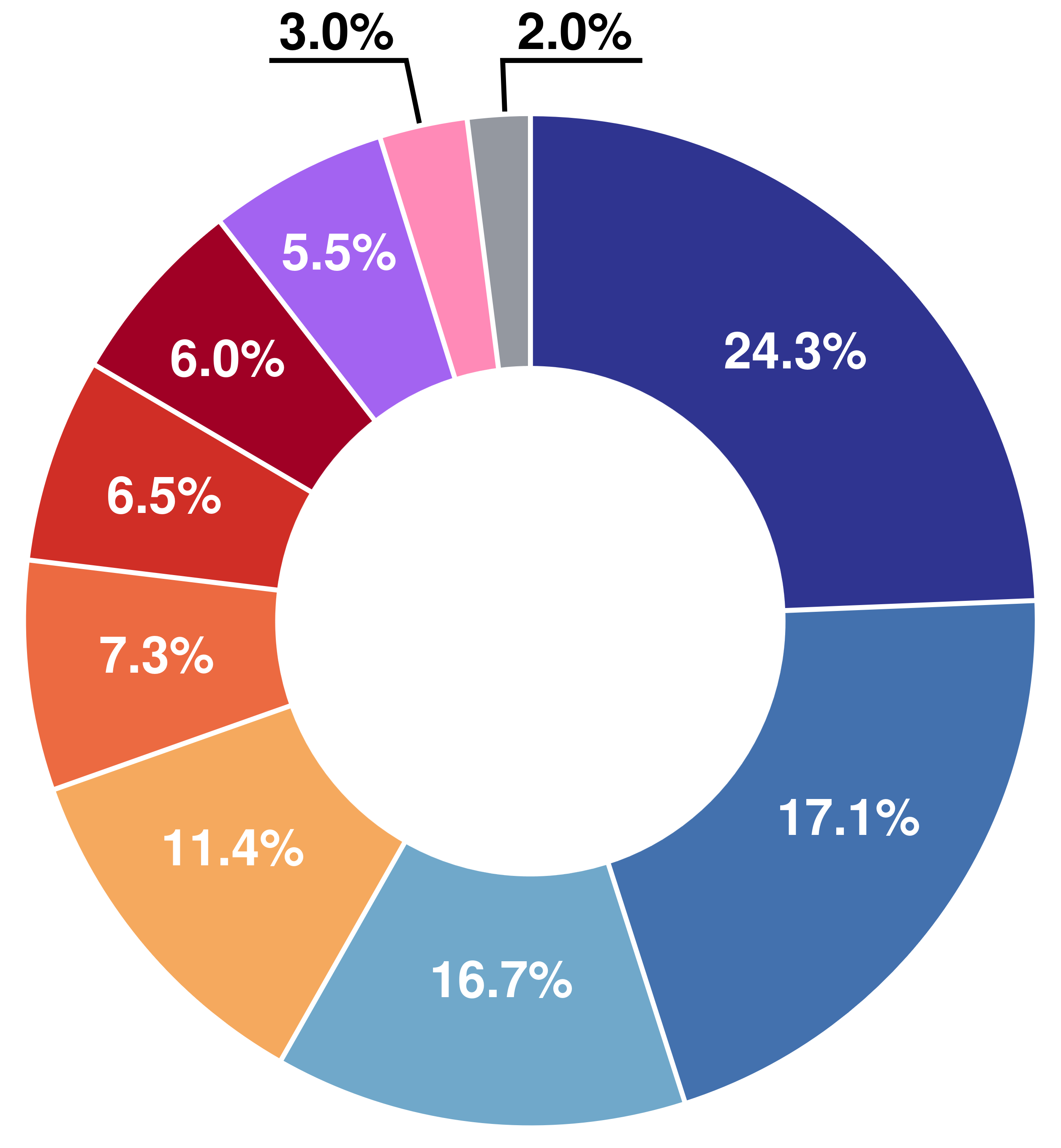
Figure 2: Distribution of Question types with examples.
The application of rigorous filtering mechanisms, such as semantic consistency checks and near-duplicate detection, significantly refines the dataset, ensuring high-quality QA pairs suitable for dense retrieval models.
Evaluation of Dense Retrieval Models
Fine-tuning experiments demonstrate WebFAQ's utility in enhancing retrieval performance across languages. Pretraining XLM-RoBERTa models on MS MARCO followed by WebFAQ fine-tuning yields notable performance improvements on zero-shot retrieval benchmarks.
The experiments reveal substantial gains over established baselines like BM25 in monolingual contexts and underscore the diversity and richness of WebFAQ as a resource for multilingual retrieval tasks.
Bilingual QA Alignment
The paper introduces a novel bilingual corpus through advanced bitext mining leveraging LaBSE and GEMBA. The approach aligns QA pairs across languages, capitalizing on FAQs' inherent multilingual nature, which frequently presents congruent information across language versions.
This bilingual dataset not only surpasses existing resources in translation quality but also extends the applicability of WebFAQ by offering a robust basis for cross-lingual retrieval tasks.
Implications and Future Directions
WebFAQ addresses critical gaps in multilingual dense retrieval by offering a comprehensive, open-access dataset that encourages innovation in cross-lingual NLP research. The introduction of bilingual QA corpora enables a suite of applications from language modeling to machine translation evaluation.
Future research may expand the languages involved, explore enhanced bitext mining techniques, and refine retrieval performance further by integrating emergent models in NLP. The resources of WebFAQ set the stage for significant advancements in multilingual information retrieval, transcending traditional language barriers to achieve more inclusive, diverse AI systems.
Conclusion
WebFAQ is a valuable contribution to open-domain QA retrieval, facilitating improvements in multilingual dense retrieval systems through large-scale, high-quality data. Its open availability on platforms like GitHub allows for broad accessibility and subsequent advancements in the NLP community. The initiative paves the way for more sophisticated and inclusive AI models capable of handling the intricacies of multilingual question answering in real-world scenarios.