- The paper introduces a novel framework where causality emerges from data compression using Conditional Feature-Mechanism Programs and UFCCs, bypassing identifiability constraints.
- It demonstrates how CFMPs compute probabilistic models and capture sparse mechanism shifts to reveal regularities in complex datasets.
- The study leverages Kolmogorov and finite codebook complexity to operationalize causality, offering new insights for large-scale machine learning applications.
Algorithmic Causal Structure Emerging Through Compression
Introduction
This paper explores the intersection of causality, symmetry, and compression within algorithmic frameworks, proposing an innovative approach to algorithmic causality. The traditional causal discovery methods rely on strong identifiability assumptions that may not always hold true, leading to the necessity of new frameworks when these assumptions fail. The authors propose a methodology where causality is derived as a regularity bias by compressing data across multiple environments.
Framework and Implementation
Algorithmic Causality in the Absence of Identifiability:
The paper introduces algorithmic causality, a concept that does not rely on the identifiability of causal models. This approach is beneficial when traditional assumptions of causality do not hold. The authors define Conditional Feature-Mechanism Programs (CFMP) to compute probabilistic models through Turing machines. A CFMP proceeds through three steps:
- Mechanism Generation: Without input, it generates a set of probabilistic mechanisms (PM) and feature mechanisms (FM).
- Featurization: These mechanisms are then featurized for specific input types.
- Joint Probability Computation: Finally, it computes the probability of the input data using the featurized mechanisms.
This process (Figure 1) allows capturing regularities from data, aligning with the concept that compression inherently involves learning such regularities.
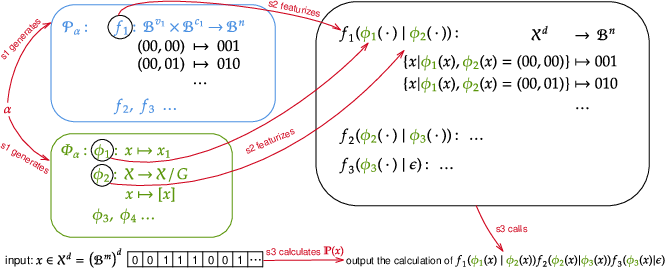
Figure 1: Illustration of a CFMP showing the sequential steps with probabilistic and feature mechanisms.
Kolmogorov Complexity and Finite Codebook Complexity
Kolmogorov Complexity:
The conceptual foundation for the compression-based approach involves Kolmogorov complexity, which measures the shortest binary program capable of outputting a given dataset. It is generally impractical due to its incomputability; thus, the paper uses upper bounds for practical implementation.
Finite Codebook Complexity (FC Complexity):
To circumvent the infeasibility of directly calculating Kolmogorov complexity, the paper introduces finite codebook complexity. This is an operational method to calculate the length of a message set including the codebook needed to losslessly reconstruct given datasets, specifically tailored to the CFMP setup.
Application and Evaluation
Sparse Mechanism Shifts with UFCCs:
The authors introduce Universal Finite Codebook Computers (UFCCs) which simulate finite codebooks and can compute any distribution with sufficient precision. By minimizing the FC complexity, CFMP configurations that align with simple causal structures or sparse mechanism shifts are preferred, demonstrating the emergence of "algorithmic causality."
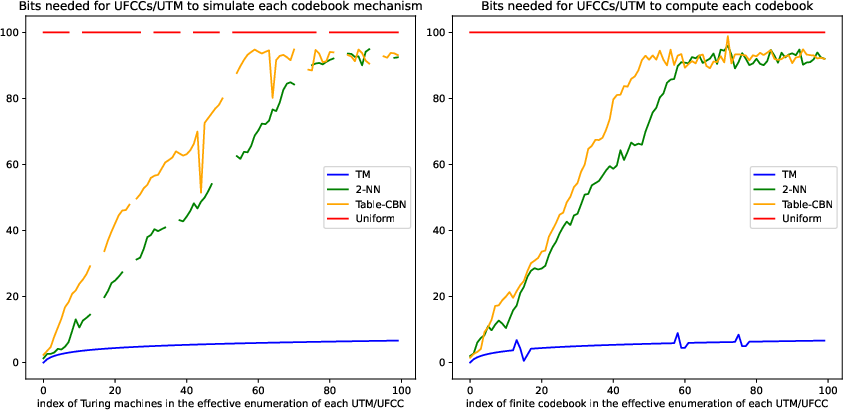
Figure 2: Simulation results using UFCCs showing the computational benefits of sparse mechanism models.
Implications and Conclusion
Practical Implications:
This framework presents significant implications for machine learning, particularly for models like LLMs where causal relationships are not easily identifiable. The ability to extract actionable causality from compression provides a nuanced understanding of how models achieve generalization across disparate datasets.
Conclusion:
The paper effectively demonstrates that through the lens of compression, causality can be redefined and practically approximated without reliance on stringent identifiability assumptions. The assumptions and conditions for algorithmic causality outlined in this study provide a potent tool for exploring causal questions in complex and large-scale data systems. This framework has the potential to redefine understandings within AI systems where causality and learning intersect deeply with compression.