- The paper demonstrates that integrating sparse autoencoders as a zero-shot classifier enables selective and non-destructive concept erasure.
- It utilizes contrastive feature selection and MSE thresholds to isolate and deactivate unique concept features efficiently.
- Empirical results show improved safety, scalability, and preservation of visual quality across diverse concepts compared to prior methods.
Sparse Autoencoder as a Zero-Shot Classifier for Concept Erasing in Text-to-Image Diffusion Models
Introduction and Motivation
Text-to-image diffusion models achieve high-fidelity correspondence between complex text prompts and image generation, but their capability to synthesize content related to harmful, copyrighted, or unwanted concepts has led to significant concerns. Standard approaches for concept erasure in diffusion models either involve fine-tuning—leading to catastrophic forgetting or unintended degradation (especially on out-of-distribution concepts)—or modular additions, which lack generalizability and scalability. The paper proposes Interpret-then-Deactivate (ItD), advancing beyond these prior paradigms by leveraging Sparse Autoencoders (SAEs) integrated into the text encoder for precise, non-destructive, and extendable concept erasure without the need for model retraining or parameter modification.
Methodology: Integration of SAEs into the Erasure Pipeline
The ItD framework operates on the hypothesis that the semantic space learned by transformers in the text encoder can be decomposed into sparse, monosemantic features associated with concepts potentially overlapping in the feature space. SAEs are trained in an unsupervised manner to extract these sparse features from intermediate residual streams of the text encoder.
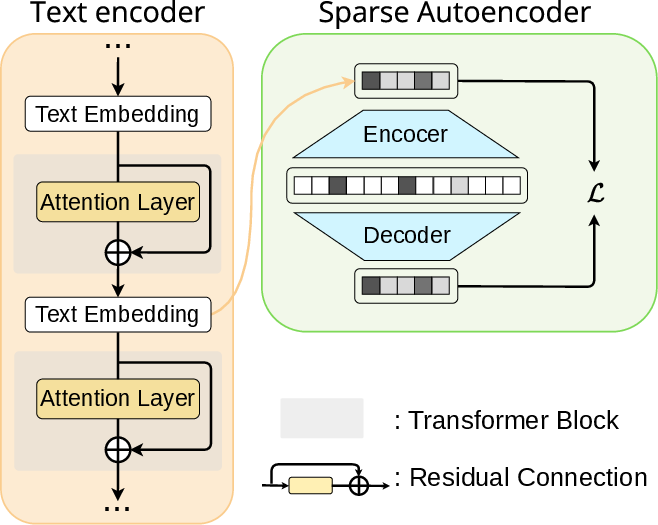
Figure 1: Unsupervised training of SAE, which takes a token embedding obtained from the residual streamer in text encoder as an input and aims to reconstruct it with sparse features.
Given the residual stream at a specified encoder layer, SAE learns a K-sparse representation, i.e., selecting only the top-K latent features per token. SAEs are optimized not just for reconstruction but also for robustness against dead features, using auxiliary loss terms on a larger set of activations (Kaux>K). This yields sparse features that are interpretable and highly selective for specific concepts.
A crucial improvement over prior work is that concept erasure occurs by zeroing out only those features identified, via contrastive selection, as unique to the target concept (e.g., “nudity,” “Bill Clinton”), avoiding the shared polysemantic features whose deactivation would impact normal generation ability.
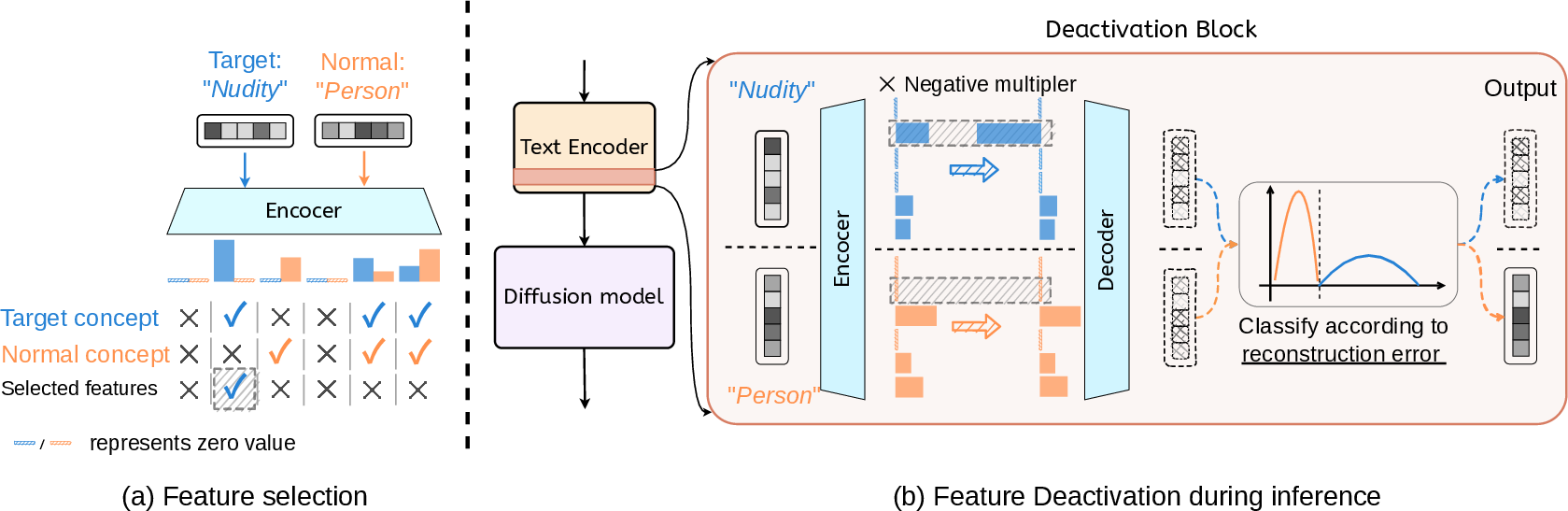
Figure 2: (a) With a well-trained SAE, unique features of target concepts are identified via contrast with normal concepts; (b) the SAE is wrapped as a deactivation block and inserted in the text encoder for concept eraser.
Zero-Shot Classification and Selective Deactivation
A key insight demonstrated is that the SAE's reconstruction error serves as a zero-shot discriminator for target concept activation in a prompt. The histogram of reconstruction MSE loss shows a clear separation between target concepts and the broad distribution of normal ones.
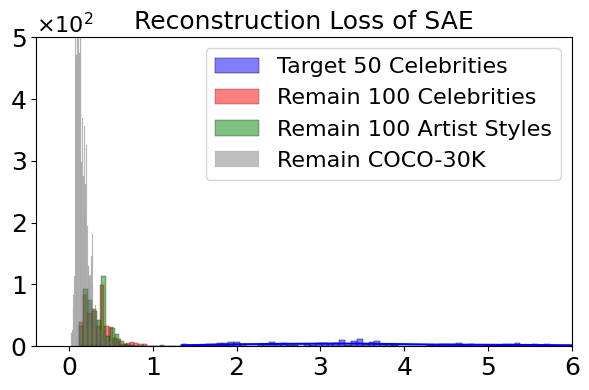
Figure 3: Histogram of reconstruction MSE loss on target concepts and remaining concepts.
This property is exploited to construct a selective deactivation block: if the MSE loss exceeds a threshold τ, the SAE output is substituted for the original embedding, otherwise the embedding is left unchanged. This integration minimizes accidental erasure of non-target concepts and preserves generation quality on out-of-distribution data.
Empirical Results: Multi-Concept and Robust Concept Erasure
Qualitative and quantitative results validate the selectivity and robustness of ItD. In scenarios such as erasing 50 celebrities or 100 artistic styles, ItD eradicates target concepts while maintaining the visual fidelity and diversity of other concepts—surpassing fine-tuning and existing module-insertion baselines across multiple evaluation domains (celebrity faces, artistic styles, COCO-30K, DiffusionDB-10K).

Figure 4: Qualitative results of ItD and baselines on multiple concepts erasing (50 celebrities simultaneously).

Figure 5: Qualitative results for erasing 100 artist styles at once, showing minimal degradation on non-target concepts.
The SAE-based approach, with feature selection as the union of unique target-concept features, generalizes effortlessly to the multi-concept setting. Unlike LoRA- or gate-based modular approaches, ItD requires no independent training per concept and displays consistent image quality across diverse prompts.
ItD also demonstrates pronounced robustness to adversarial prompts crafted to bypass safety filters—a persistent vulnerability for parameter-editing or regularization-based schemes.
Analysis and Ablations: Sensitivity, Layer Placement, and Efficiency
Detailed ablation studies reveal:
Ablating the deactivation strength parameter λ reveals that the erasure is robust over a range of λ values, with perfect or near-perfect discrimination between target and non-target concepts when λ<−2.
Applying the SAE at different residual stream layers shows best specificity and minimal interference when inserted in intermediate transformer blocks (layers 6–10), aligning with findings on where concept abstraction is concentrated.
Larger hidden sizes (e.g., 219) yield better feature granularity and separation, with smaller sizes increasing overlap and reconstruction confusion.
The SAE block (two matrix multiplications and a Top-K activation) incurs negligible (<1%) overhead on total generation time and is independent of the number of erased concepts.
Practical and Theoretical Implications
Practically, ItD enables modular, plug-and-play, and non-destructive concept removal on deployed T2I diffusion models, with no need to retrain or fine-tune the underlying networks. The zero-shot discriminative capacity of the SAE provides a mechanism for online, scalable moderation including unforeseen or new concepts, strictly improving safety and compliance for open-ended generative systems.
Theoretically, this work reinforces the viability of post hoc, feature-level interpretability tools (i.e., sparse autoencoders) for semantic steering in high-capacity generative models. The empirical finding that selectivity and completeness of concept removal are maximized via contrastive feature selection, rather than coarse-grained parameter surgery, challenges previously dominant views in model unlearning for generative architectures.
This direction could motivate further research into integrating sparse representations for more granular and dynamic content steering, prompt-time concept manipulation, and fine-resolution bias correction in diffusion models.
Conclusion
This paper presents ItD, a framework embedding sparse autoencoders into the text encoder of T2I diffusion models for efficient, zero-shot, and highly selective concept erasure. By interpreting and deactivating only those features unique to a target concept, ItD prevents generation of unwanted imagery with minimal or no damage to the expressive power and quality on legitimate content. Its scalability, robustness to adversarial attacks, and computational efficiency establish a new benchmark for responsible and practical large-scale concept unlearning in neural generative models.