- The paper presents a causal reward modeling framework that isolates non-causal features to mitigate biases such as length preference and demographic discrimination.
- It employs an MMD-based regularizer with binning strategies to ensure reward predictions remain invariant under irrelevant input interventions, preserving model performance.
- Empirical evaluations show reduced sycophancy, concept bias, and discrimination, while maintaining high winrates and robust overall model utility.
Causal Reward Modeling for Robust LLM Alignment
The paper "Beyond Reward Hacking: Causal Rewards for LLM Alignment" (2501.09620) addresses the vulnerabilities present in standard RLHF pipelines, particularly the emergence of reward hacking due to spurious correlations in reward modeling. Traditional reward models, trained on pairwise human preferences, often conflate superficial or non-causal features—such as response length, sycophancy, or demographic cues—with actual task quality. This misalignment not only leads to undesired behaviors (reward hacking), but also manifests in systematic biases, undermining both reliability and fairness of LLM outputs, especially in high-stakes or socially sensitive applications.
Causal Reward Modeling Framework
The authors formalize counterfactual invariance as the desideratum for reward models: reward predictions should remain stable under interventions on irrelevant input factors (Z), for example, response length or demographic attributes. They introduce a causal decomposition, identifying TZ,⊥—the components of the prompt-response input not causally affected by Z—and construct a reward model constrained to depend only on these invariant components.
Due to the inaccessibility of true counterfactual examples in RLHF settings, the authors turn to measurable statistical independence, introducing an MMD-based regularizer. The reward model is trained to minimize standard preference loss, augmented with an MMD penalty enforcing that model representations are invariant over Z. Binning strategies are employed for Z to make this regularization practical in high-cardinality or continuous-factor scenarios.
Empirical Evaluation: Spurious Correlation Mitigation
Length Bias Analysis
The model is evaluated on the Alpaca dataset with respect to length bias. Traditional reward models frequently reward verbosity due to data imbalances, leading policies to over-produce long but low-quality outputs. The causal reward model (CRM), with MMD regularization applied to response length, demonstrates consistent mitigation of length preference without sacrificing overall model winrate.
After generating 50 responses per prompt and re-ranking by reward value, CRM variants systematically assign higher ranks (i.e., indicate higher preference) to shorter responses when the causal regularization coefficient is increased, breaking the correlation between length and perceived reward.
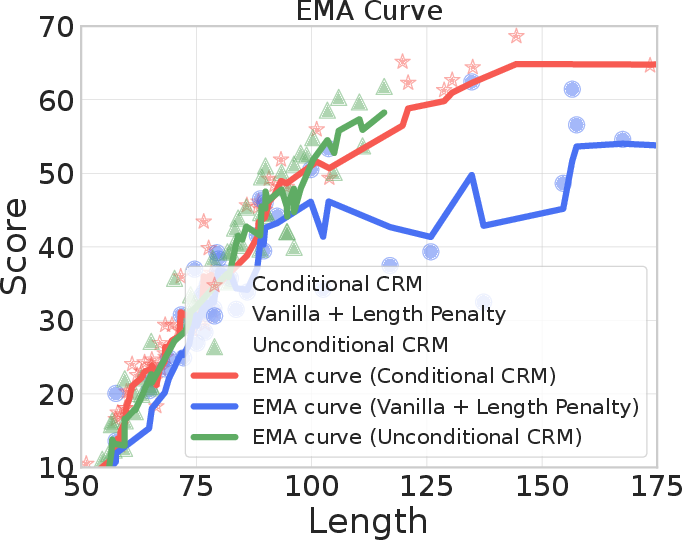
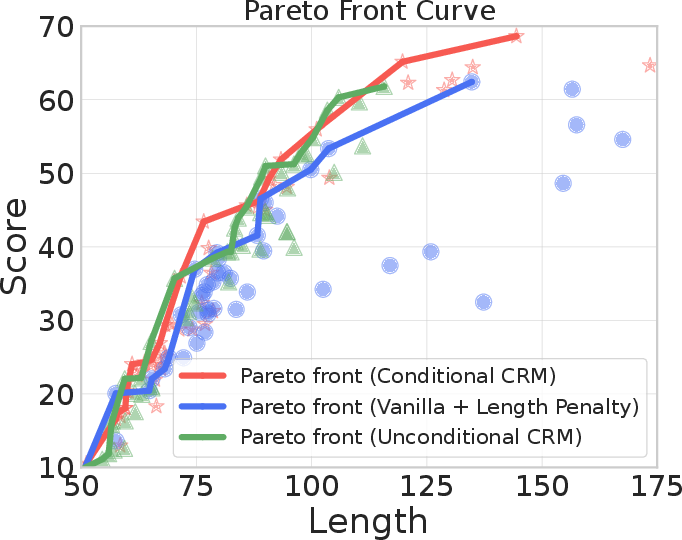
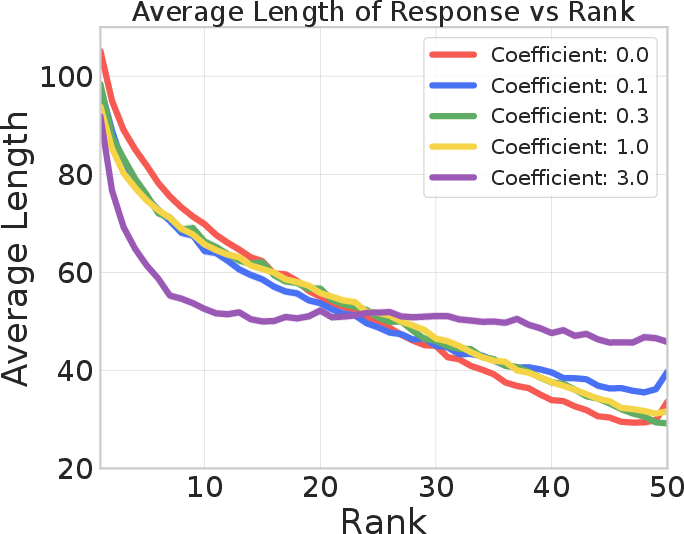
Figure 1: CRM mitigates length bias, as indicated by superior EMA winrate curves, a more favorable Pareto front, and diminished correlation between response length and reward ranking.
Discrimination Bias and Model Utility
Using HH-RLHF and the Discrm-eval benchmark, the authors examine both explicit and implicit discrimination along demographic axes (age, gender, race). CRM-trained models, particularly the unconditional variant, display marked reductions in discrimination coefficients compared to both SFT and vanilla PPO-finetuned baselines. Notably, this substantial reduction in discriminatory behavior does not come at the expense of general model utility, as measured by GPT-4o winrate.
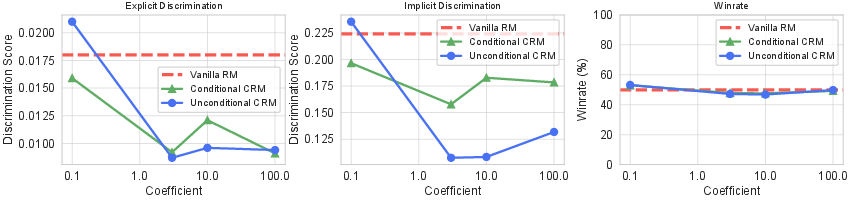
Figure 2: Scaling the MMD coefficient sharply reduces both explicit and implicit discrimination, while leaving head-to-head model winrates against vanilla PPO effectively unchanged.
Sycophancy, Concept Bias, and Generalization
The CRM framework is further evaluated on semi-synthetic sycophancy tasks and real-world concept bias using modified sentiment datasets (Yelp, IMDB, Amazon). CRM models drastically reduce sycophantic behavior, as measured by the elimination of templates such as "Yes, you are right" from outputs, despite strong presence in training signals. In concept-biased datasets, CRM significantly suppresses spurious associations between irrelevant concepts (e.g., 'food' and positive sentiment), with conditional CRM providing the strongest bias mitigation (some Bias@C metrics reduced to near zero).
Theoretical and Practical Implications
By formalizing the distinction between reducible and irreducible error in reward modeling, the paper demonstrates that traditional data scaling and model capacity increases cannot redress biases grounded in structural spurious correlations. The CRM approach, grounded in causal inference, directly targets this irreducible error by enforcing invariance to non-causal variables at the representation level.
The practical impact is twofold. First, the CRM framework is compatible as a drop-in enhancement for any PPO-based RLHF pipeline, as it merely augments the reward model's training loss. Second, CRM provides robust debiasing not just for a single known failure mode (e.g., length), but is extensible to any measurable input variable that might induce spurious reward correlations—including demographic categories, allowing for explicit fairness controls.
Outlook and Future Directions
This work highlights that robust LLM alignment necessitates moving beyond observational preference fitting, toward approaches that explicitly engage with the underlying causal structure of human preferences and annotator behavior. Potential extensions include integrating richer, domain-specific causal graphs, dynamic binning for high-dimensional spurious factors, and applying similar invariance regularization techniques to direct preference or DPO-style optimization.
As LLMs are increasingly deployed in critical applications, frameworks such as CRM will be key to ensuring reliable and equitable model behavior, particularly as data sources and user populations diversify. This causal approach provides a scalable yet theoretically grounded pathway for addressing reward hacking and operationalizing trustworthy alignment at scale.
Conclusion
The causal reward modeling paradigm represents a principled advancement in LLM alignment research, enabling significant mitigation of reward hacking from multiple bias sources—length, sycophancy, concept association, and demographic discrimination—while preserving model utility and adaptability. By providing a practical, modular, and theoretically motivated design for integrating causal invariance, this approach stands as a substantive contribution to both the practice and understanding of reliable AI alignment.