- The paper presents a novel framework that empowers AI agents with domain-specific SOPs to improve task execution efficiency.
- It employs structured prompt generation and selective depth-first search to guide decision-making and reduce computational overhead.
- Experimental results on benchmarks like ALFWorld and HotpotQA demonstrate significant performance gains over general-purpose agents.
Introduction to "SOP-Agent: Empower General Purpose AI Agent with Domain-Specific SOPs"
The paper "SOP-Agent: Empower General Purpose AI Agent with Domain-Specific SOPs" explores a novel framework to augment general-purpose AI agents with domain-specific Standard Operational Procedures (SOPs) to enhance their efficiency and applicability in real-world tasks. By translating complex workflows into pseudocode-style SOPs, this framework aims to overcome limitations in planning capabilities characteristic of current LLM-based agents, enabling more robust and domain-oriented task execution.
SOP-Agent Framework
The SOP-Agent framework formalizes SOPs as decision graphs that an agent can traverse. Each node in the graph represents a potential action that impacts the environment and gathers additional evidence for subsequent decisions. Edges of the graph define conditions under which transitions occur, incorporating both conditional ("IF") and unconditional ("ALWAYS") transitions. This design supports cascading execution, branching, and looping, endowing agents with the flexibility to handle sophisticated workflows.
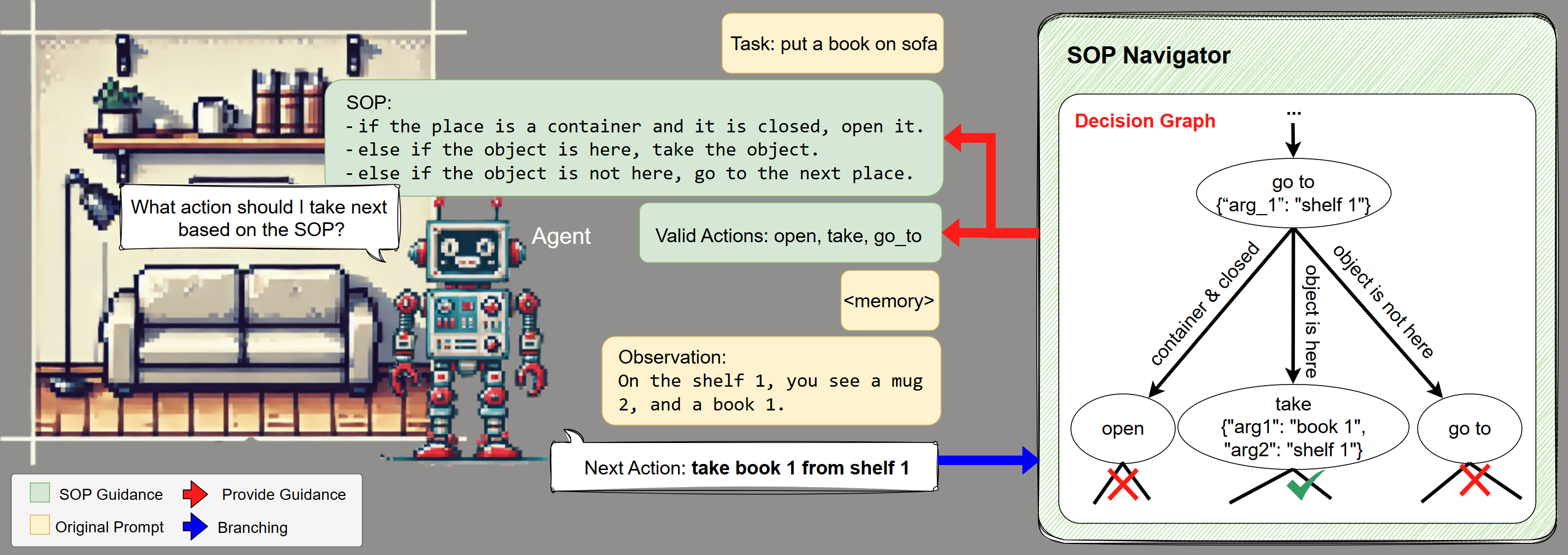
Figure 1: Left: The SOP-Agent framework. During each step, the SOP-Navigator formats a textual SOP and provides a filtered set of valid actions to guide the base agent's behavior. The agent needs to generate the next action, which is used to traverse the decision graph and update the state of the SOP-Navigator. Right: The Decision Graph. The figure shows a segment from a decision graph.
SOP Guidance and Decision Graph Traversal
The system guides agent behavior utilizing two pivotal components: structured prompt generation and filtered function calls. The structured prompts are derived from SOPs, guiding the agent's actions, while the filtered set of valid function calls constrains the action space, bolstering decision-making robustness. The framework employs a selective depth-first search (DFS) traversal for executing the SOPs, optimizing branching via function call distinctions whenever possible, reducing computational overhead.
Experiments and Results
ALFWorld Benchmark
In the ALFWorld benchmark, the SOP-agent significantly outperformed general-purpose agents like AutoGPT. The SOP-agent, leveraging human-crafted SOPs, achieved a remarkable 66.2% improvement over AutoGPT and showed strong results across diverse task categories. However, the system's robustness was limited in tasks involving manual decision-making errors.
HotpotQA Benchmark
For the HotpotQA benchmark, the SOP-agent exhibited marginal improvements over ReAct, particularly in action pattern efficiency, demonstrating a reduction in unnecessary repetitive actions and enhanced exploration capabilities through deeper lookup levels.
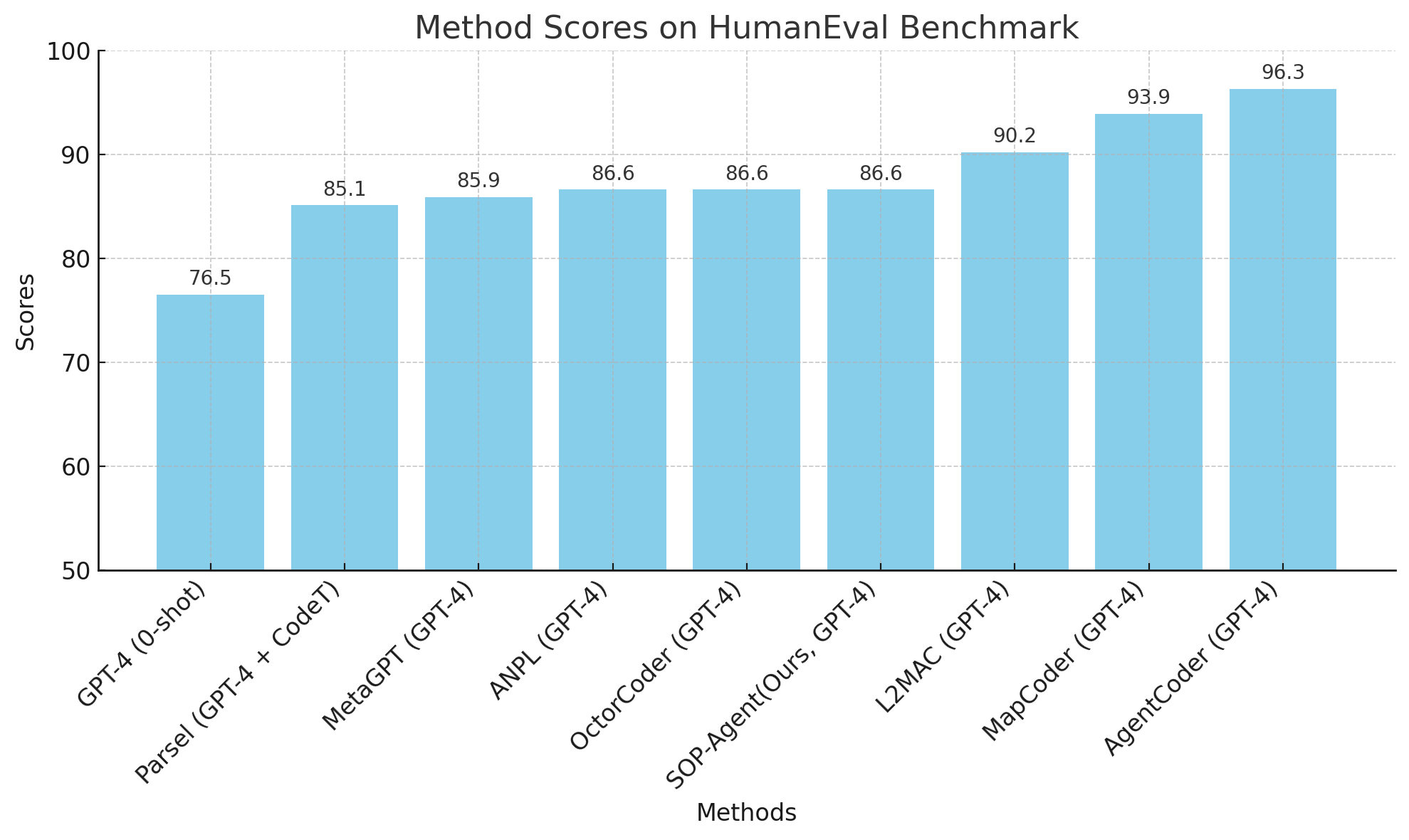
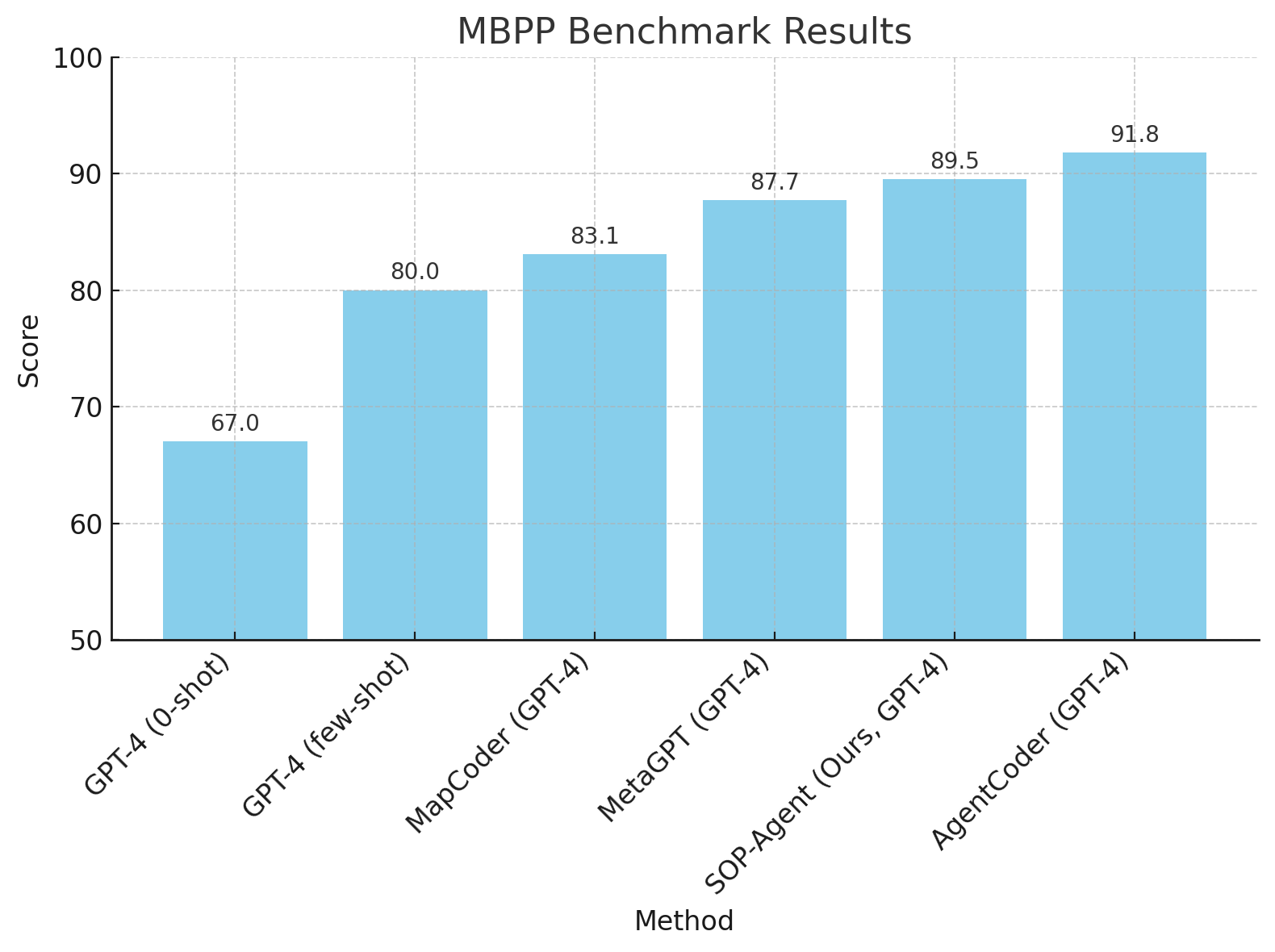
Figure 2: HumanEval benchmark results
Code Generation
In code generation tasks using the HumanEval and MBPP benchmarks, SOP-agent's structured approach led to superior performance, matching or surpassing state-of-the-art domain-specific agents like MetaGPT. The integration of a debugging process and self-reflection through SOPs enabled the agent to achieve high Pass@1 scores.
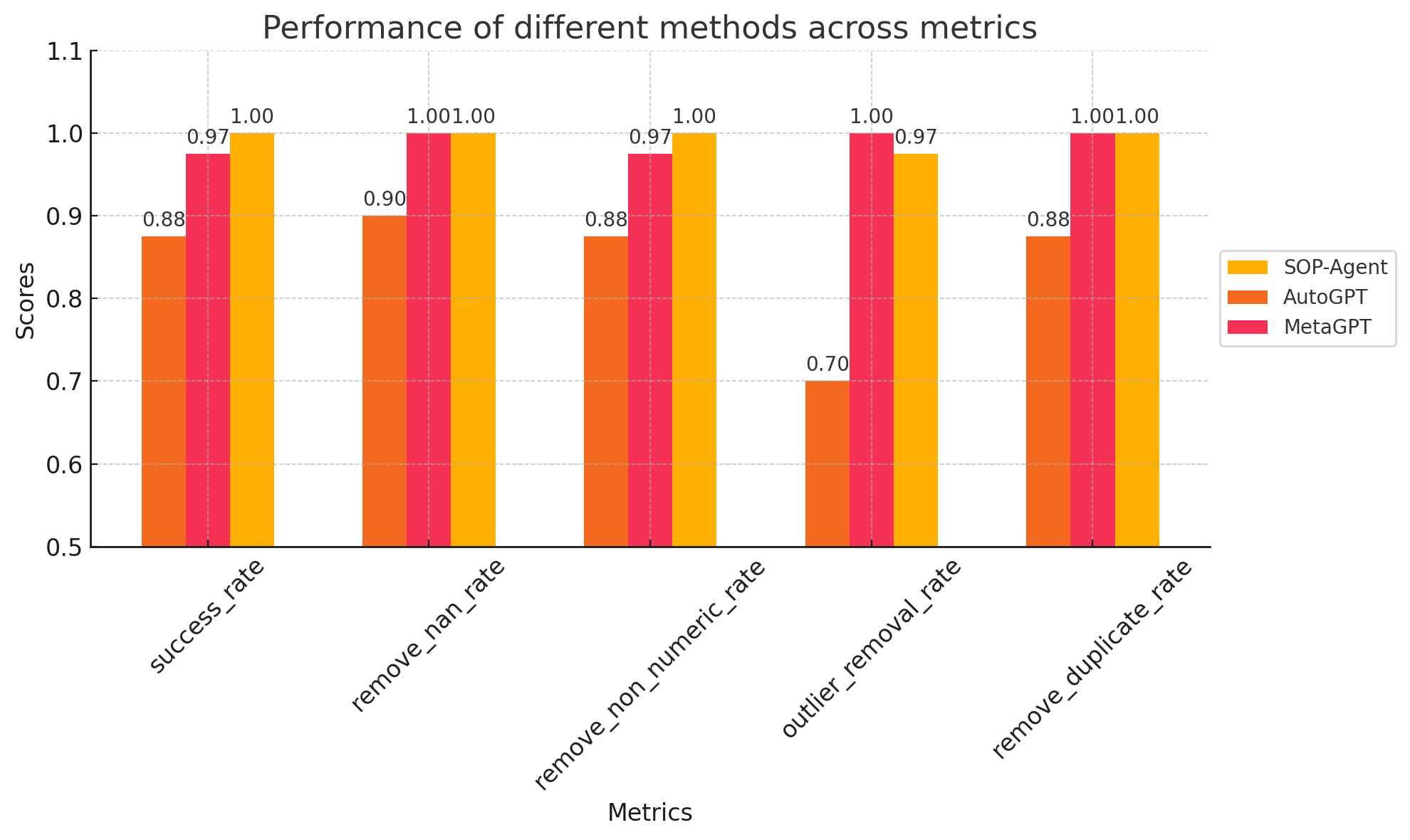
Figure 3: Results on the data-cleaning task
Data Cleaning
In data cleaning tasks, the SOP agent demonstrated its capacity to apply complex domain-specific knowledge effectively, achieving a 100% success rate and rivaling domain-specific agents such as MetaGPT's Data Interpreter.
SOP Engineering and Grounded Customer Service Benchmark
The concept of SOP engineering, inspired by prompt engineering, was introduced to refine and enhance the robustness of SOP-based agents. The development of the Grounded Customer Service Benchmark to test SOP-agent showed promising results, with the SOP-agent achieving near-perfect accuracy in executing SOPs related to customer service scenarios.
Conclusion
The SOP-agent framework marks a significant step in enhancing AI agents' abilities to manage domain-specific tasks. By integrating SOPs into agent workflows, this methodology offers an adaptable approach to leveraging human expertise in AI systems. While successful, the framework's dependency on manually crafted SOPs and its susceptibility to LLM hallucinations suggest areas for further research to increase autonomy and resilience against errors.