Multiagent Finetuning: Self Improvement with Diverse Reasoning Chains
Abstract: LLMs have achieved remarkable performance in recent years but are fundamentally limited by the underlying training data. To improve models beyond the training data, recent works have explored how LLMs can be used to generate synthetic data for autonomous self-improvement. However, successive steps of self-improvement can reach a point of diminishing returns. In this work, we propose a complementary approach towards self-improvement where finetuning is applied to a multiagent society of LLMs. A group of LLMs, all starting from the same base model, are independently specialized by updating each one using data generated through multiagent interactions among the models. By training each model on independent sets of data, we illustrate how this approach enables specialization across models and diversification over the set of models. As a result, our overall system is able to preserve diverse reasoning chains and autonomously improve over many more rounds of fine-tuning than single-agent self-improvement methods. We quantitatively illustrate the efficacy of the approach across a wide suite of reasoning tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Multiagent Finetuning: A Simple, Teen-Friendly Explanation
What is this paper about?
This paper is about teaching AI LLMs (like smart chatbots) to get better at hard reasoning tasks—especially math—by working as a team. Instead of training just one model over and over (which often stops helping after a while), the authors train a group of models that play different roles, learn from each other, and keep improving for many rounds.
What questions are the researchers trying to answer?
- Can a team of AI models improve itself using its own generated practice problems and answers?
- If the models take on different roles (like “writer” and “editor”), will they keep a variety of problem-solving styles instead of all sounding the same?
- Will this teamwork help the AI get better for more rounds of training than usual?
- Can the improved models solve new problems they haven’t practiced on?
How does their method work?
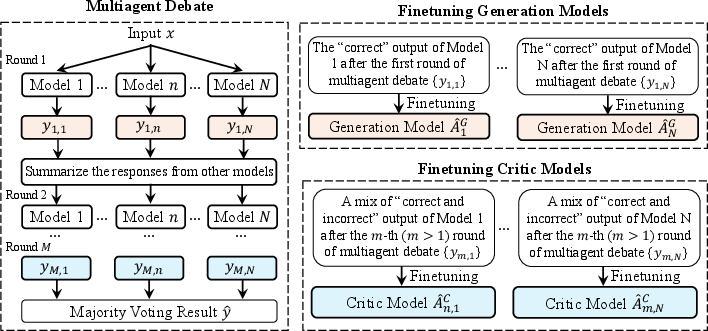
Think of it like a study group with writers and editors:
- The team starts as several copies of the same base model.
- Some copies are “generation agents” (the writers) who produce first-draft answers to questions.
- Other copies are “critic agents” (the editors) who read what the writers said, compare different answers, explain what’s wrong or right, and suggest improvements.
- The group has a short “debate”: writers answer, critics review and revise, and at the end the team picks the final answer by majority vote (the answer most agents agree on).
How they train the team:
- Each writer model is trained on the specific correct answers it personally produced. This helps different writers develop their own strengths and styles, instead of all copying the same solution.
- Each critic model is trained on examples that show:
- How to fix a wrong first answer into a right final answer (learning to correct mistakes).
- How to keep a right answer right throughout the debate (learning to stay accurate).
- They repeat this process for multiple rounds. Each round produces new training data from the group’s debates, which then helps the models improve again.
Why this helps (in everyday terms):
- If you only train one student and make them study their own old answers, they can get stuck in a rut. But if you train a team where each person practices their own best methods and also learns from editing others, the group can keep getting smarter without collapsing into one “style.”
- The team keeps a diversity of reasoning paths—different ways to get to the right answer—which prevents the model from becoming narrow and repetitive.
What did they test and find?
They tested on:
- Arithmetic (basic math expressions).
- GSM (Grade School Math): step-by-step word problems.
- MATH: harder, competition-style math problems.
Key findings:
- The multiagent team method beat several strong baselines, including:
- A single model answering alone.
- Simple majority vote across models without training.
- Multiagent debate without this special training.
- Popular self-training methods like STaR.
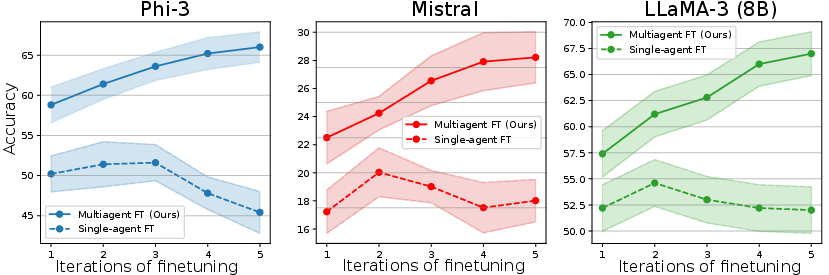
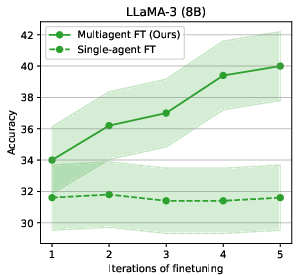
- It keeps improving over multiple training rounds, while standard self-improvement often plateaus or declines.
- For example, on the tough MATH dataset, one model (Phi-3) improved from about 58.8% to 66.0% accuracy over several rounds; another (Mistral) improved from about 22.5% to 28.2%.
- The models stayed diverse in how they reasoned. That diversity helped avoid “model collapse” (when answers all start looking the same and progress stalls).
- They also showed zero-shot generalization: a team trained on one math dataset (MATH) did very well on a different one (GSM) it hadn’t seen, even beating baselines trained directly on GSM.
Why is this important?
- It shows a way for AI to keep getting better using its own generated data, without always needing expensive human labels or access to the most powerful (and costly) models.
- The teamwork setup (writers + editors + debate) helps the system not only get answers right, but also learn multiple ways of thinking—useful for complicated problems.
- It works across different base models, including open-source ones, meaning it could help many AI systems become more capable.
What are the limits and future directions?
- Cost: Training and running several models at once is more expensive and slower than using just one. The authors suggest future tricks like sharing weights, distillation (compressing the team’s knowledge into one model), or quantization (making models smaller/faster).
- Integration: This teamwork idea could be combined with other alignment methods (like RLHF or DPO) for even better results.
Bottom line
Treating AI models like a study team—with writers who propose solutions and critics who improve them—lets the system learn diverse, smarter reasoning paths and keep improving for many rounds. This teamwork makes the AI better at challenging tasks, especially math, and helps it generalize to new problems without extra help.
Collections
Sign up for free to add this paper to one or more collections.

