- The paper introduces the SYKI-SVC system, advancing singing voice conversion with innovative post-processing to enhance high-frequency audio fidelity.
- The system integrates ContentVec and Whisper for robust feature extraction, preserving vocal expressiveness and technique.
- Experimental evaluations demonstrate superior naturalness and tone similarity up to 48kHz, confirming its professional-grade application.
Advancing Singing Voice Conversion with SYKI-SVC
Introduction
The paper "SYKI-SVC: Advancing Singing Voice Conversion with Post-Processing Innovations and an Open-Source Professional Testset" introduces an advanced singing voice conversion (SVC) system. SVC involves transforming a source singer's voice to a target singer's voice while preserving the original lyrics, melody, and vocal techniques. The challenge of SVC over general voice conversion (VC) arises from the requirement to preserve the expressiveness and techniques intrinsic to singing. The authors propose a high-fidelity SVC system built upon the SVCC T02 framework, defining a model that consists of feature extraction, voice conversion, and post-processing components.
System Architecture
The SYKI-SVC system enhances the SVCC2023 top-performing model through the adoption of a recognition-synthesis paradigm, leveraging SSL models and ASR models for better feature extraction. Utilizing ContentVec and Whisper as the foundation, the system extracts speaker-independent features that capture linguistic details while preserving the prosody through fundamental frequency (F0) analysis. During voice synthesis, the converter employs these features to reproduce the target singer’s timbre and synthesize high-quality waveform outputs.
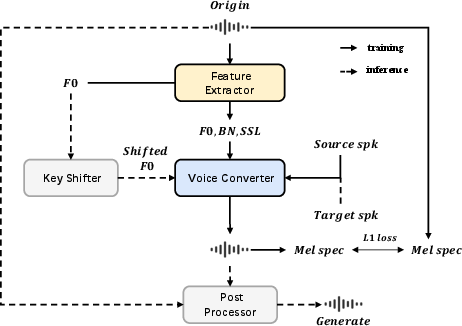
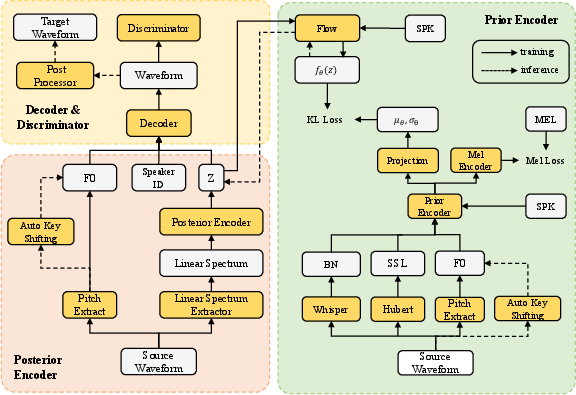
Figure 1: Illustration of the overall structure of the SYKI-SVC system and detailed architecture.
The post-processing module addresses the challenge of synthesizing high-frequency components by introducing a method to enhance audio quality using high-frequency information from the source. This innovative approach supplements the synthesized voice with high-frequency elements directly extracted from the source voice.
Proposed Methods
Feature Extraction
The feature extraction module combines SSL model ContentVec and ASR model Whisper for deriving robust linguistic feature sets and timbre-independent bottleneck features (BNFs). Speaker identity is encoded through speaker embedding via a lookup mechanism. Fundamental frequency estimation, essential for melody retention, is performed through RMVPE.
Singing Voice Converter
The conversion module is based on VITS and comprises multiple components: posterior encoder, prior encoder, decoder, and discriminator. Incorporating an F0-based sinusoidal signal within the HiFi-GAN decoder, it utilizes normalizing flows for better timbre and pitch rendition. Supervisory loss is introduced to ensure enhanced mel spectrogram reconstruction, compelling the latent space to retain ample audio information.
Post-Processing
To address high-frequency synthesis difficulties, the system supplements high-frequency components directly from the source audio, achieving improved audio quality. Signal processing methods combine high-pass and low-pass filtering techniques to blend source and synthesized audio components.
Experimental Results
Design and Evaluation
The system's efficacy was empirically validated using a novel evaluation framework. A specialized dataset featuring various singing techniques was created to benchmark professional rendition fidelity. Objective measures like cosine similarity, combined with subjective evaluations focusing on vocal naturalness, bite, and technique reproduction, were conducted.
Results and Comparisons
SYKI-SVC surpassed existing systems in terms of naturalness, technique reproduction, and tone similarity, while innovative post-processing enhanced audio fidelity at higher sampling rates up to 48kHz. Results affirm the model's superior ability to maintain naturalness and capture the singer's unique vocal characteristics.
Conclusion
The paper successfully introduces key innovations in Singing Voice Conversion through the SYKI-SVC system, effectively addressing high-frequency synthesis challenges and validating system performance with new evaluation frameworks and datasets. Future research in the SVC domain can leverage these post-processing strategies combined with robust feature extraction for enhanced audio fidelity. The authors have provided significant advancements that pave the way for professional-grade SVC applications, while ensuring accessibility through open-source datasets for the research community's growth.

