- The paper introduces GenHMR, a novel generative framework that reformulates human mesh recovery as an image-conditioned task, addressing depth ambiguity and occlusion.
- The model employs a pose tokenizer with VQ-VAE and an image-conditioned masked transformer to iteratively refine pose predictions using uncertainty-guided sampling and 2D pose-guided refinement.
- Experimental results show significant error reduction in MPJPE and PA-MPJPE metrics, outperforming state-of-the-art methods on datasets like Human3.6M, 3DPW, and EMDB.
GenHMR: Generative Human Mesh Recovery
Introduction
The paper presents GenHMR, a novel approach to human mesh recovery from monocular images, reformulated as an image-conditioned generative task. The technique aims to address the inherent challenges of depth ambiguity and occlusion in 2D-to-3D mapping. GenHMR incorporates a pose tokenizer and an image-conditional masked transformer to model the probabilistic distributions of pose tokens, improving the accuracy of 3D human mesh reconstruction from single images.
Model Architecture
GenHMR uses two key components:
- Pose Tokenizer: Utilizes Vector Quantized Variational Autoencoders (VQ-VAE) to convert continuous human pose parameters into a sequence of discrete tokens. This enables discretization of the pose space, capturing the essential features needed for accurate human mesh reconstruction.
- Image-Conditioned Masked Transformer: Trains on sequences with randomly masked tokens, learning the conditional categorical distribution of pose tokens. This transformer effectively models probabilistic mappings, aiding in refining pose estimations by leveraging image cues.
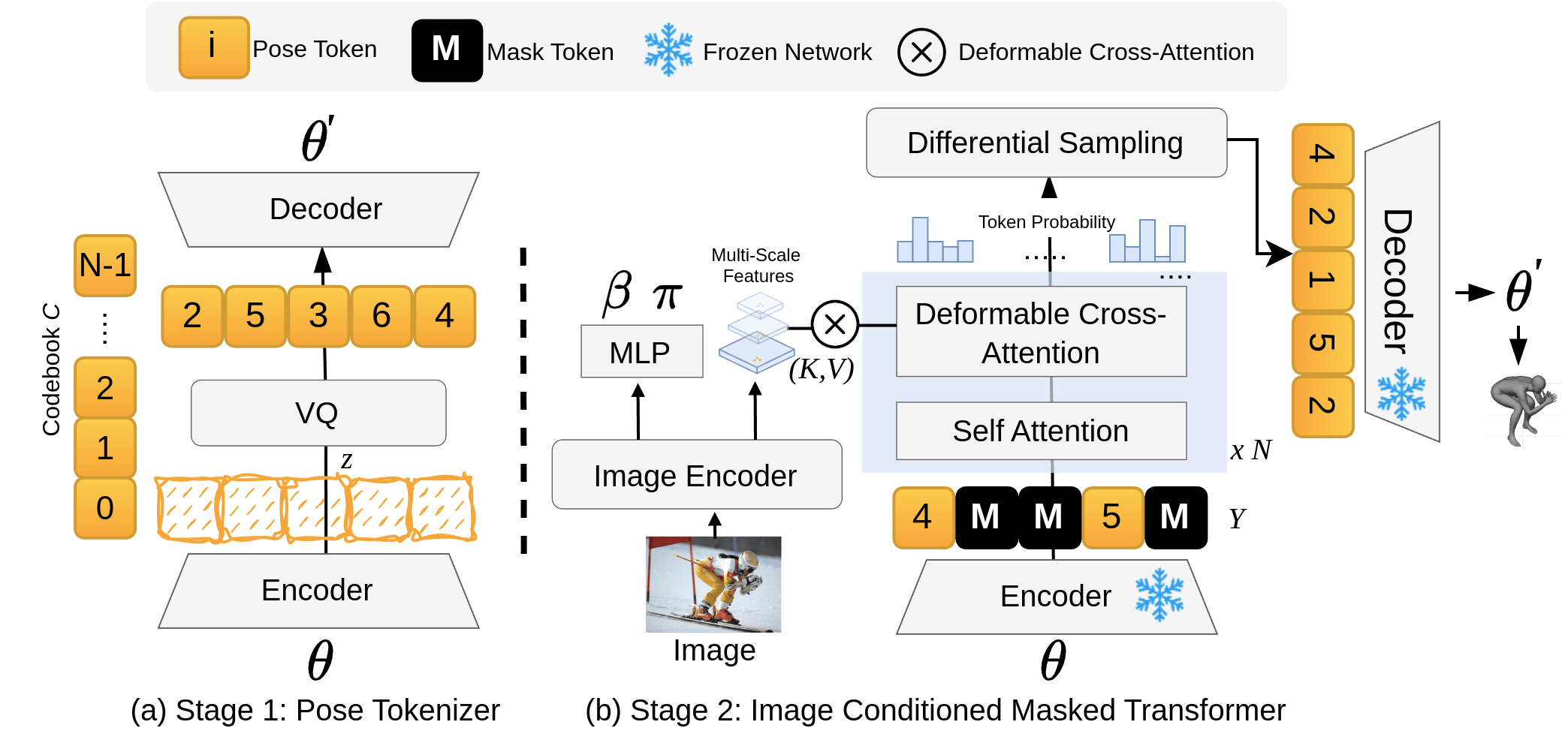
Figure 1: GenHMR Training Phase. GenHMR consists of two key components: (1) a Pose Tokenizer that encodes 3D human poses into a sequence of discrete tokens within a latent space, and (2) an Image-Conditioned Masked Transformer that models the probabilistic distributions of these tokens, conditioned on the input image and a partially masked token sequence.
Inference Strategy
The inference process consists of two main stages:
- Uncertainty-Guided Sampling: Iteratively decodes high-confidence pose tokens by sampling from learned distributions. Uncertain tokens are re-masked and refined over successive iterations, facilitating the generation of robust 3D reconstructions.
- 2D Pose-Guided Refinement: Further optimizes the pose tokens by ensuring consistency between the 3D body mesh and 2D pose estimates. This step significantly reduces reconstruction uncertainty and ensures alignment with detected 2D features.
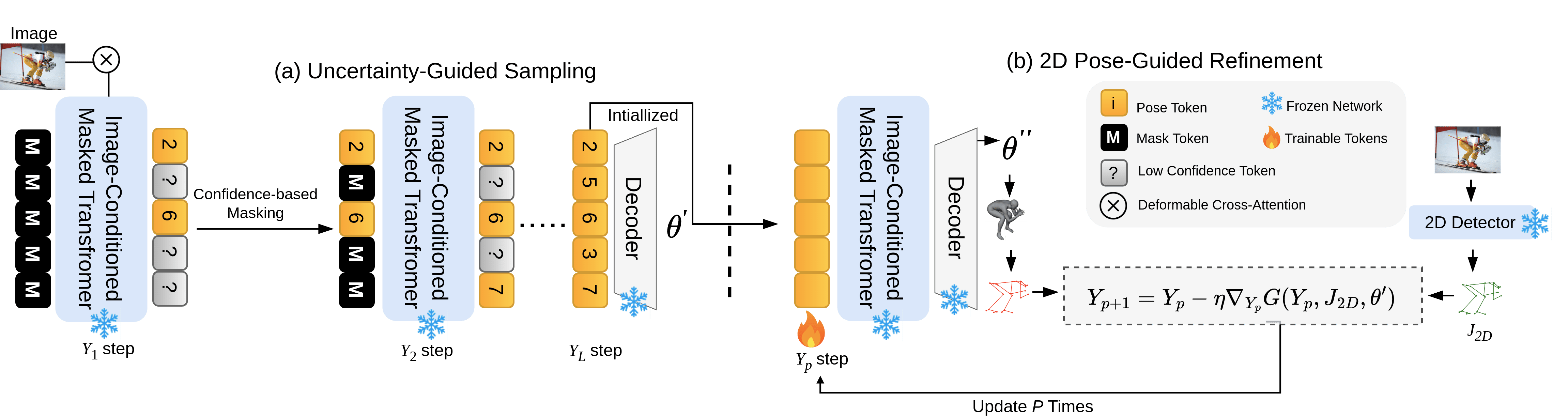
Figure 2: Our inference strategy comprises two key stages: (1) Uncertainty-Guided Sampling, which iteratively samples high-confidence pose tokens based on their probabilistic distributions, and (2) 2D Pose-Guided Refinement, which fine-tunes the sampled pose tokens to further minimize 3D reconstruction uncertainty by ensuring consistency between the 3D body mesh and 2D pose estimates.
Experimental Results
Experiments demonstrate GenHMR's superiority in 3D reconstruction accuracy compared to state-of-the-art methods on datasets like Human3.6M, 3DPW, and EMDB. Notably, it achieves significant error reduction in terms of MPJPE and PA-MPJPE, showcasing its effectiveness in handling complex poses and ambiguous scenarios.
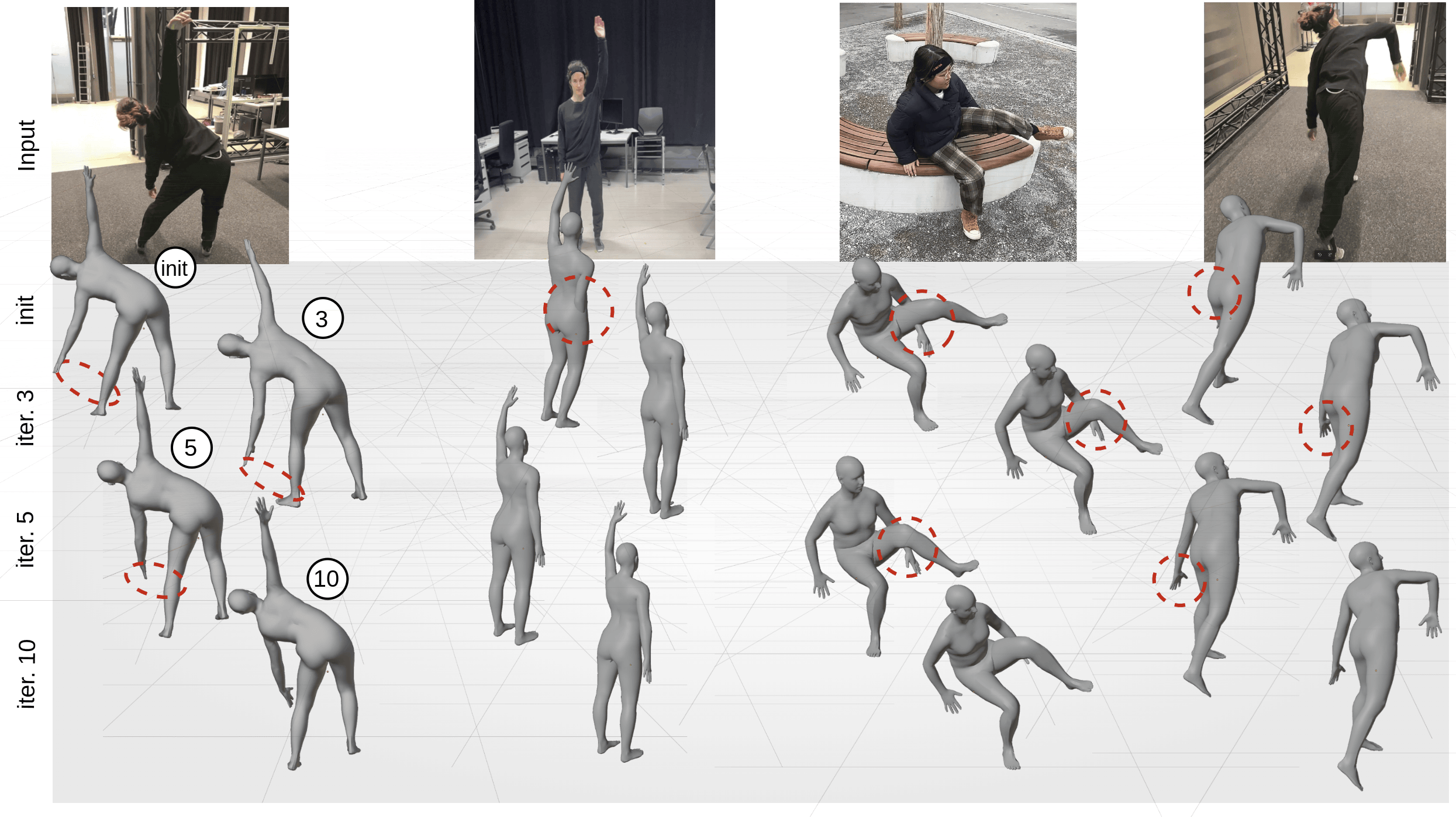
Figure 3: Impact of 2D Pose-Guided Refinement on 3D pose reconstruction. Red circles highlight areas of errors after each refinement iteration, which showcases how the method progressively refines these poses. By fine-tuning pose tokens to align the 3D pose with 2D detections, our method iteratively reduces uncertainties and improves accuracy. Significant improvements are seen in the early iterations, with errors largely minimized at the 10th iteration. Note that the initial mesh comes from UGS.
Ablation Studies
GenHMR's architecture was subjected to extensive ablation studies, evaluating the effects of token quantity, codebook size, and inference iterations on performance. Findings underscore the importance of generative masking and iterative refinement techniques in driving the improvements observed in human mesh reconstructions.
Conclusion
GenHMR marks a departure from traditional deterministic and probabilistic approaches to human mesh recovery, offering a sophisticated generative framework that excels in both controlled and in-the-wild conditions. The model's ability to iteratively refine pose estimations, combined with innovative inference strategies, ensures a high degree of accuracy and robustness in complex scenarios. The advancements seen with GenHMR imply promising directions for further exploration and application in AI-driven human pose analysis.