Reinforcement Learning: An Overview
Abstract: This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based methods, policy-based methods, model-based methods, multi-agent RL, LLMs and RL, and various other topics (e.g., offline RL, hierarchical RL, intrinsic reward).
- Deep Reinforcement Learning (2018)
- Deep Reinforcement Learning: An Overview (2017)
- A Brief Survey of Deep Reinforcement Learning (2017)
- Reinforcement Learning and Control as Probabilistic Inference: Tutorial and Review (2018)
- Reinforcement Learning (2020)
- Understanding Reinforcement Learning Algorithms: The Progress from Basic Q-learning to Proximal Policy Optimization (2023)
- An Introduction to Deep Reinforcement Learning (2018)
- Distribution Parameter Actor-Critic: Shifting the Agent-Environment Boundary for Diverse Action Spaces (2025)
- Towards a Unified View of Large Language Model Post-Training (2025)
- A Survey of Reinforcement Learning for Large Reasoning Models (2025)
Summary
- The paper clarifies the formal foundations of reinforcement learning by detailing its mathematical modeling in MDP, POMDP, and belief state frameworks.
- It systematically categorizes canonical problem settings and compares algorithmic paradigms including value-based, policy-based, and model-based methods.
- It discusses practical challenges such as sample efficiency, robust representation learning, and exploration-exploitation trade-offs, outlining open research directions.
Reinforcement Learning: An Authoritative Overview
This essay provides a comprehensive technical summary of "Reinforcement Learning: An Overview" (2412.05265), focusing on the formal foundations, canonical problem settings, algorithmic paradigms, and the theoretical and practical implications of modern RL research. The discussion is organized to reflect the structure and depth of the monograph, with emphasis on the mathematical formalism, algorithmic trade-offs, and the landscape of open challenges.
Formal Foundations of Reinforcement Learning
Reinforcement learning (RL) is formalized as a sequential decision-making problem, where an agent interacts with an environment to maximize cumulative expected reward. The agent maintains an internal state st and selects actions at according to a policy π(at∣st). The environment, typically modeled as a (partially observable) Markov process, transitions to a new state and emits observations and rewards in response to the agent's actions.
The agent's objective is to find a policy π∗ that maximizes the expected sum of discounted rewards:
Vπ(s0)=E[t=0∑TγtR(st,at)∣s0,π]
where γ∈[0,1] is the discount factor, and R(st,at) is the reward function. The optimal policy is defined as:
π∗=argπmaxEs0∼p0[Vπ(s0)]
The agent-environment interaction is depicted as a feedback loop, with the agent as a small controller embedded in a large, possibly stochastic, external world.
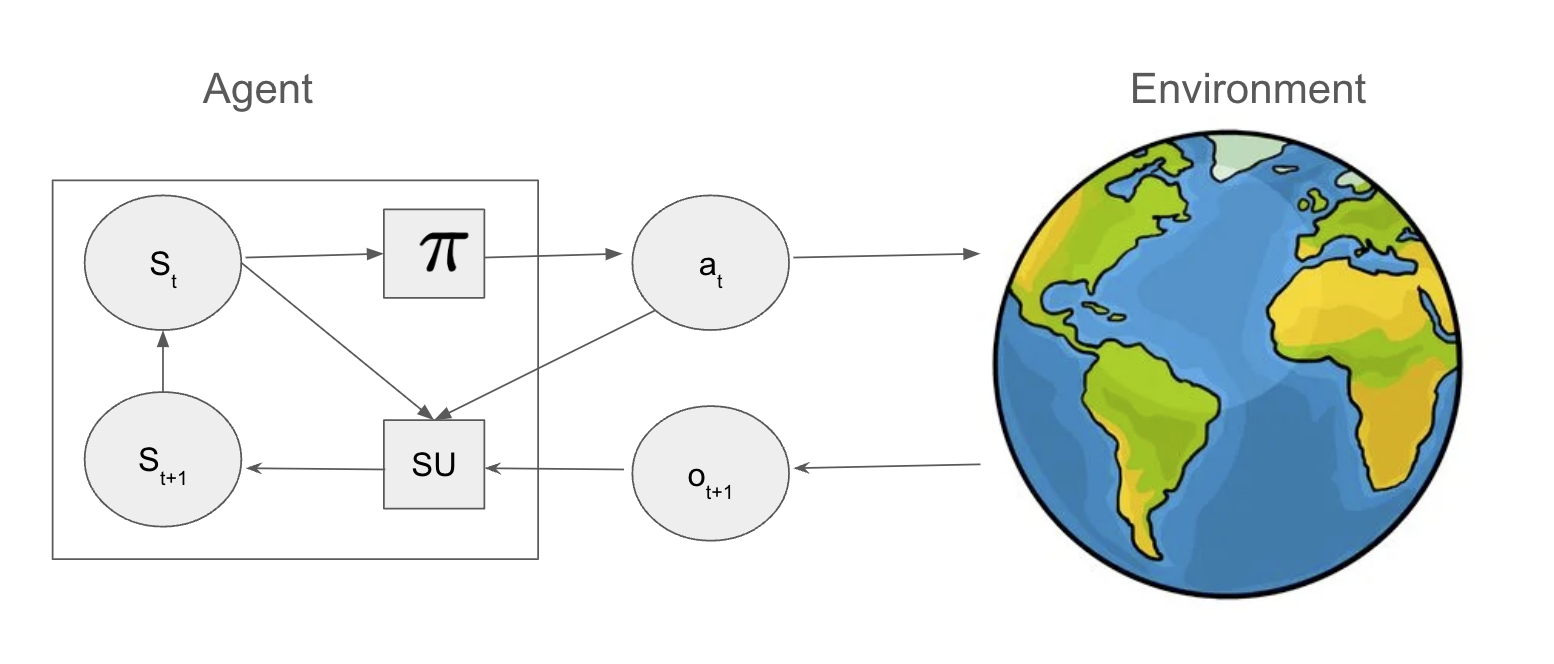
Figure 2: A small agent interacting with a big external world.
The universal modeling framework extends to partially observable Markov decision processes (POMDPs), where the agent must maintain a belief state over latent world states due to partial observability and perceptual aliasing. The agent's internal state update is decomposed into prediction and correction steps, often leveraging learned encoders and decoders for high-dimensional observations.
Canonical Problem Settings
The monograph systematically categorizes RL problem settings:
- POMDPs: The agent receives partial, noisy observations and must maintain a belief state, updated via Bayesian inference. Exact solutions are intractable for large state spaces.
- MDPs: The agent observes the full state; the environment is modeled as a finite state machine with known or unknown transition and reward functions.
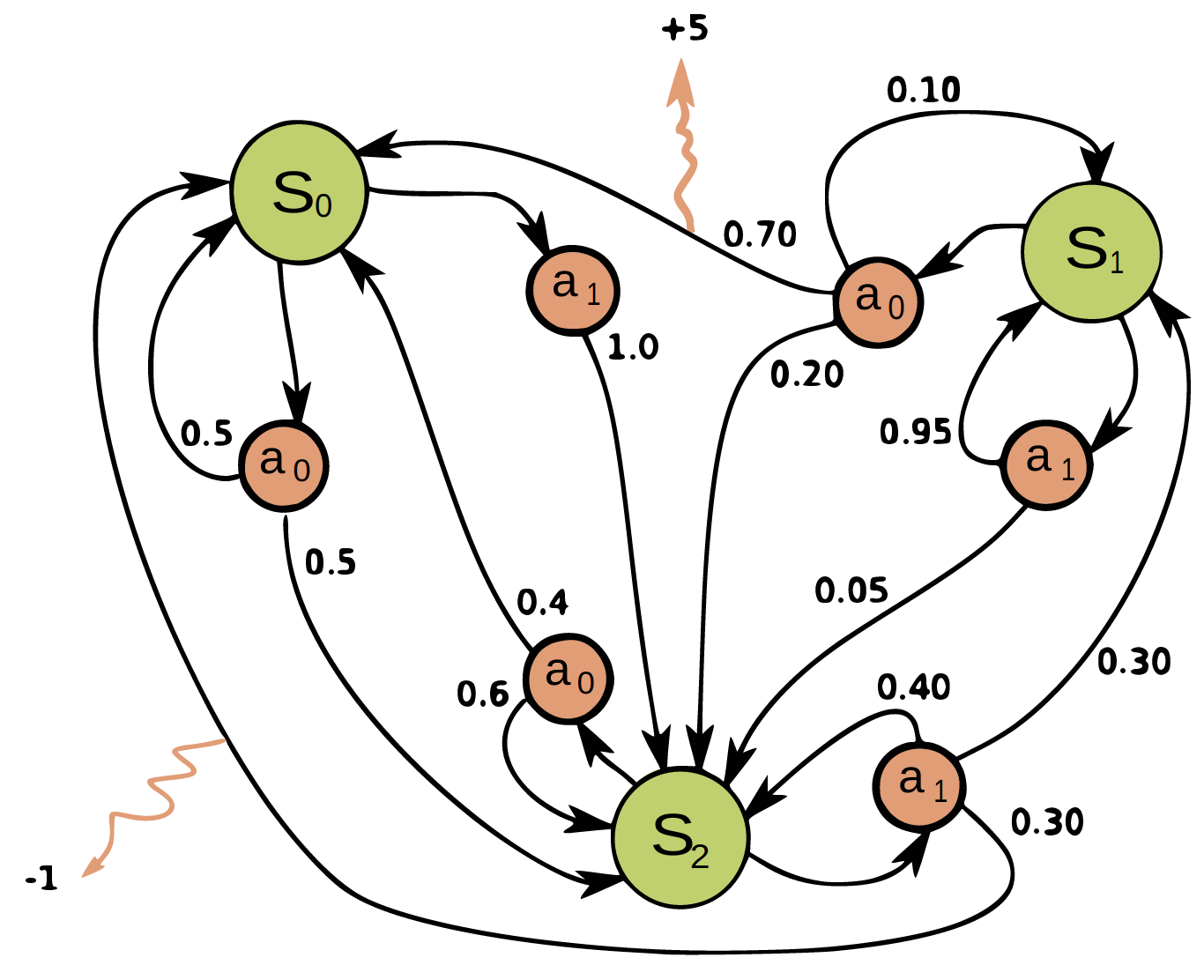
Figure 4: Illustration of an MDP as a finite state machine (FSM) with discrete states, actions, and sparse rewards.
- Contextual MDPs: The environment dynamics depend on a hidden static context, requiring generalization across related MDPs.
- Contextual Bandits: The agent observes a context, selects an action, and receives a reward, but actions do not affect future contexts.
- Belief State MDPs: The agent's state is a posterior over unknown parameters, updated via Bayes' rule, enabling optimal exploration-exploitation via methods like UCB and Thompson sampling.
The monograph also discusses optimization-centric settings such as best-arm identification, Bayesian optimization, and active learning, highlighting the connections between RL and black-box optimization.
Algorithmic Paradigms
Value-Based Methods
Value-based RL, or approximate dynamic programming, centers on learning value functions V(s) or action-value functions Q(s,a), which satisfy Bellman's equations:
V∗(s)=amax[R(s,a)+γEs′[V∗(s′)]]
Q∗(s,a)=R(s,a)+γEs′[a′maxQ∗(s′,a′)]
These recursive equations underpin dynamic programming algorithms such as value iteration and policy iteration. In the model-free setting, temporal difference (TD) learning and Q-learning are used to estimate value functions from sampled transitions, with off-policy Q-learning enabling the use of experience replay and function approximation.
Policy-Based Methods
Policy-based RL directly optimizes the expected return with respect to parameterized policies, using the policy gradient theorem:
∇θJ(πθ)=Es∼dπ,a∼πθ[Qπ(s,a)∇θlogπθ(a∣s)]
Variance reduction is achieved via baselines (e.g., value functions), leading to actor-critic architectures. Advanced methods such as natural policy gradient, trust region policy optimization (TRPO), and proximal policy optimization (PPO) enforce monotonic policy improvement via KL or TV constraints.
Model-Based Methods
Model-based RL (MBRL) interleaves learning a world model (dynamics and reward) with planning or policy optimization. Two main approaches are:
- Decision-time planning: Model predictive control (MPC) and Monte Carlo tree search (MCTS) use the learned model to plan actions at each step.
- Background planning: Synthetic rollouts from the model are used to train policies or value functions, as in Dyna and MBPO.
MBRL is essential for sample efficiency, but is sensitive to model errors and objective mismatch between model learning and policy optimization.
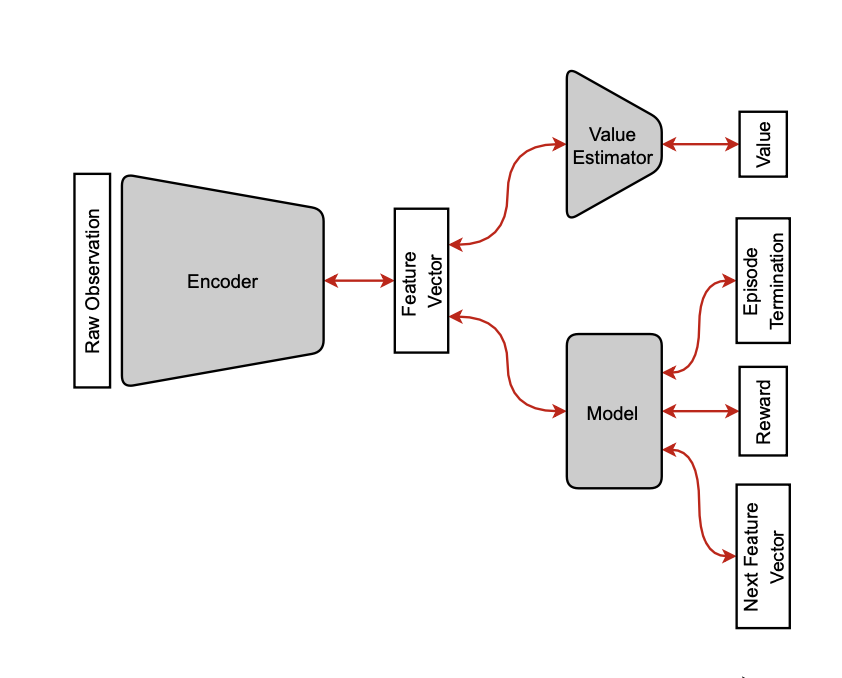
Figure 6: Illustration of an encoder zt=E(ot), passed to a value estimator vt=V(zt) and a world model predicting the next latent state z^t+1=M(zt,at).
Exploration-Exploitation and Regret
The exploration-exploitation dilemma is formalized via regret, defined as the difference between the expected reward of the agent's policy and that of an oracle. The monograph reviews:
- Heuristics: ϵ-greedy, Boltzmann exploration, and intrinsic reward bonuses.
- Optimal Bayesian methods: Gittins indices for bandits, Bayes-Adaptive MDPs (BAMDPs) for MDPs.
- Upper Confidence Bounds (UCB): Optimism in the face of uncertainty, with theoretical guarantees for bandits and extensions to MDPs.
- Thompson Sampling: Posterior sampling for exploration, with strong empirical and theoretical performance.
RL as Probabilistic Inference
A unifying perspective is presented by casting RL as probabilistic inference, where optimality is encoded as a binary variable and the posterior over trajectories is proportional to the exponentiated sum of rewards. This leads to the maximum entropy RL objective:
J(π)=E[t∑R(st,at)+αH(π(⋅∣st))]
This framework underlies algorithms such as soft actor-critic (SAC) and connects to active inference in neuroscience, where agents minimize variational free energy to achieve homeostasis.
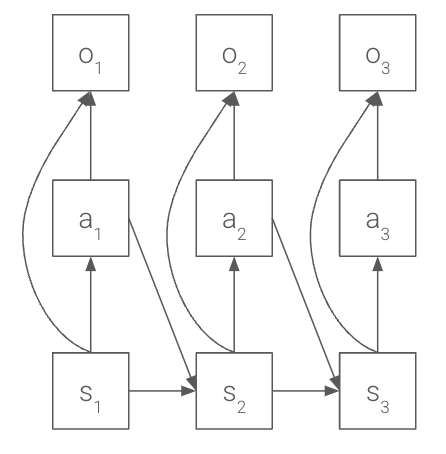
Figure 8: A graphical model for optimal control, illustrating the probabilistic structure of RL as inference.
Partial Observability and Representation Learning
The monograph addresses partial observability via:
- Belief state MDPs: Bayesian filtering to maintain sufficient statistics.
- Finite history and frame stacking: Approximating the belief state with recent observations.
- Recurrent policies: RNNs to encode observation-action histories.
- Predictive state representations (PSRs): Learning to predict future observations directly.
Representation learning is critical for high-dimensional observations. The text discusses value equivalence, bisimulation metrics, and self-predictive representations (SPR) as criteria for learning latent state abstractions that are sufficient for control.
Practical Considerations and Software
The implementation of RL algorithms is non-trivial due to instability from the "deadly triad" (function approximation, bootstrapping, off-policy learning), high variance in empirical results, and the need for careful experimental design. The monograph provides a curated list of open-source RL libraries in JAX and PyTorch, and recommends robust evaluation metrics such as the interquartile mean (IQM).
Implications and Future Directions
The monograph synthesizes the theoretical and practical landscape of RL, highlighting several key implications:
- Sample efficiency: Model-based and Bayesian methods are essential for real-world applications where data is expensive.
- Scalability: Deep RL methods have enabled progress in high-dimensional domains, but stability and generalization remain open challenges.
- Representation learning: Advances in latent state abstraction, bisimulation, and self-predictive models are critical for scaling RL to complex, partially observed environments.
- Unified frameworks: The probabilistic inference view provides a principled foundation for integrating control, exploration, and representation learning.
- Robustness and generalization: Distributional robustness, uncertainty quantification, and transfer across tasks and environments are active areas of research.
The field is converging towards architectures that combine model-based planning, deep representation learning, and principled exploration, with applications ranging from robotics to large-scale multi-agent systems.
Conclusion
"Reinforcement Learning: An Overview" offers a rigorous, comprehensive treatment of RL, bridging foundational theory, algorithmic design, and practical implementation. The monograph's formalism and breadth make it a valuable reference for researchers seeking to understand the state-of-the-art and the open challenges in RL. Future developments are likely to focus on scalable, robust, and sample-efficient algorithms that unify model-based and model-free paradigms, leverage advances in representation learning, and are grounded in the probabilistic inference framework.
Paper to Video (Beta)
No one has generated a video about this paper yet.
Whiteboard
No one has generated a whiteboard explanation for this paper yet.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Open Problems
We found no open problems mentioned in this paper.
Continue Learning
- How does the paper address the challenges of partial observability in reinforcement learning?
- What are the trade-offs between model-based and model-free approaches highlighted in the monograph?
- In what ways does the probabilistic inference framework unify control and exploration in reinforcement learning?
- How do modern representation learning techniques enhance the performance and scalability of RL algorithms?
- Find recent papers about deep reinforcement learning.
Collections
Sign up for free to add this paper to one or more collections.
Tweets
Sign up for free to view the 66 tweets with 8576 likes about this paper.
YouTube
HackerNews
- Reinforcement Learning: An Overview (82 points, 12 comments)
- Reinforcement Learning: An Overview (6 points, 1 comment)

