- The paper provides a comprehensive framework for combining deep learning with reinforcement learning to tackle complex decision-making processes.
- It details the integration of value-based, policy-based, and actor-critic methods to enhance learning stability and performance.
- The paper underscores the importance of effective state representation, exploration strategies, and hierarchical structuring for robust real-world applications.
Overview of "An Introduction to Deep Reinforcement Learning"
This essay discusses the paper "An Introduction to Deep Reinforcement Learning" which provides an extensive overview of the combination of deep learning and reinforcement learning (RL) methodologies. The primary focus is on utilizing these combined techniques to solve complex decision-making tasks that were previously intractable for machines. The paper is structured as a comprehensive guide covering different models, algorithms, and techniques associated with deep reinforcement learning (DRL), with an emphasis on practical applications and generalization.
Concepts and Technical Insights
Deep Reinforcement Learning
Deep reinforcement learning synergizes the representation capabilities of deep learning with the decision-making capabilities of reinforcement learning. The result is a powerful framework capable of:
- Processing high-dimensional input spaces
- Solving tasks with partial observability
- Learning directly from raw input data such as pixels from video frames
The essence of DRL lies in mapping states of an environment to actions that maximize some notion of cumulative reward.
Value-Based Methods and Policy-Based Methods
The paper elaborates on both value-based methods (such as Deep Q-Networks) and policy-based methods. Value-based methods rely on estimating the value function that defines expected future rewards, whereas policy-based methods focus directly on optimizing the policy function that dictates the agent’s behavior. A popular approach combines aspects of both via actor-critic methods, benefiting from the stability of value-based methods and the direct optimization traits of policy-based methods.
Generalization
In DRL, generalization refers to the capability of an agent to perform well even when faced with unseen states that were not encountered during training. This is critical for applying DRL systems to real-world applications where exhaustive training samples are impractical. Techniques to improve generalization include:
Implementation and Considerations
State Representation
Effective state representation is paramount for efficient DRL. The neural network's architecture plays a significant role, with convolutional and recurrent layers being common choices for handling spatial and temporal patterns, respectively. These architectures can inherently focus on relevant features of the input, improving generalization by facilitating learning abstractions of the environment.
Planning and Exploration
DRL systems often require balancing exploitation—maximizing returns based on current knowledge—and exploration—gathering new information about the environment. Various strategies can be employed, such as epsilon-greedy policies or more advanced model-based planning approaches that use a simulated environment to predict outcomes.

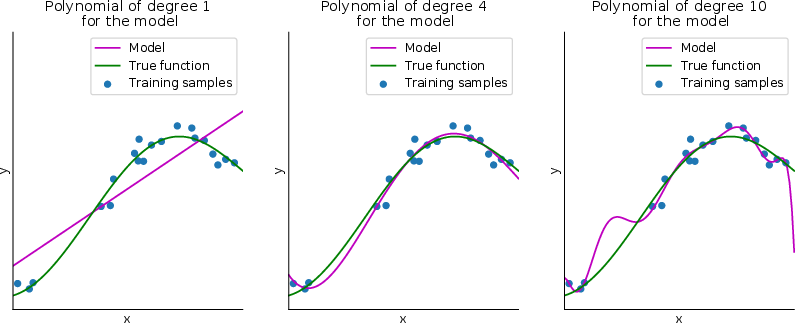
Figure 2: Schematic representation of the bias-overfitting tradeoff.
Hierarchical Reinforcement Learning
Agents can benefit from structuring tasks hierarchically, which involves breaking down complex decision-making processes into simpler, modular sub-tasks. This not only makes the learning process more manageable but also aids in reusability and scalability of learned policies across different tasks.
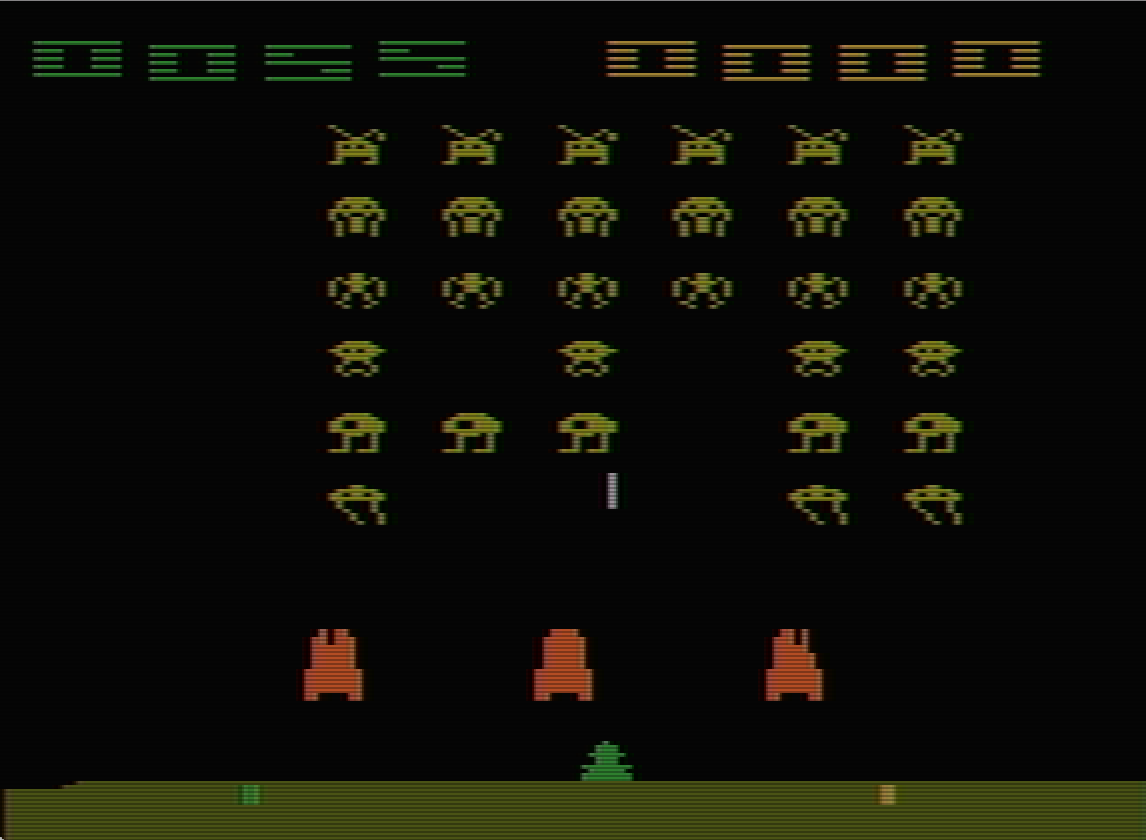

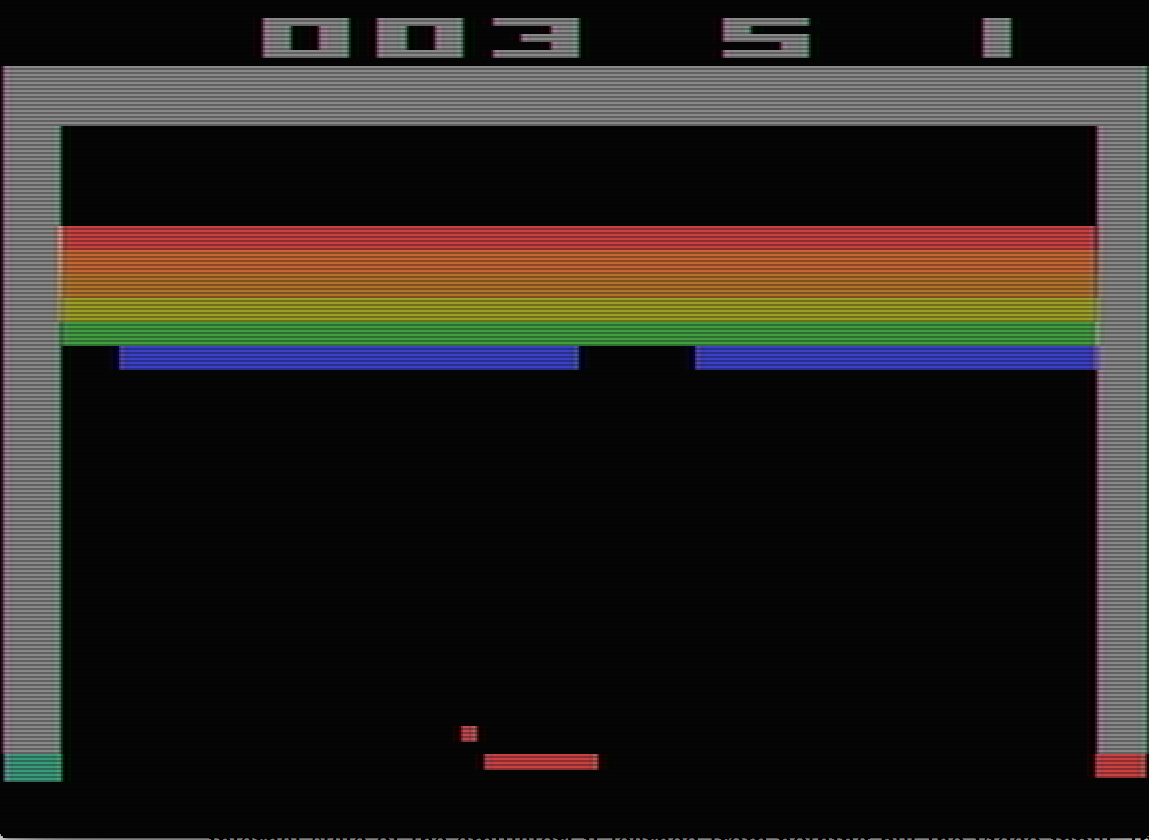
Figure 3: Illustration of three Atari games.
Practical Applications
Robotics and Autonomous Systems
DRL has significant implications in robotics, where agents are required to perform complex manipulation and locomotion tasks. These tasks typically involve continuous action spaces and dynamic environments, demanding robust generalization and real-time decision-making capabilities.
Healthcare and Smart Grids
DRL is also being explored for applications in healthcare for personalized treatment plans and autonomous management of smart grids to optimize energy consumption dynamically.
Conclusion
The adoption of deep reinforcement learning signifies a paradigm shift in how machines learn from interactions with their environments. By leveraging data-driven insights and powerful representation capabilities of deep neural networks, DRL paves the way for sophisticated autonomous agents capable of navigating complex decision landscapes. Future advancements are likely to enhance scalability, generalization, and adaptability of these agents, opening new frontiers in artificial intelligence applications.