- The paper presents a sparse transformer framework that decouples modality-specific parameters, achieving up to 55.8% FLOPs reduction on text-image tasks.
- It demonstrates scalability across text, image, and speech, maintaining competitive performance in both autoregressive and diffusion-based training objectives.
- Experimental evaluations reveal significant training speedups and efficiency gains, positioning MoT as ideal for large-scale multi-modal applications.
Overview
The "Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models" focuses on addressing computational efficiency in training large-scale multi-modal models. This architecture is designed to process and generate text, images, and speech within a unified framework. It achieves significant computational savings over traditional dense transformer models by implementing a sparse architecture that decouples non-embedding parameters for different modalities.
MoT utilizes a sparse architecture where modality-specific neural modules, such as feed-forward networks, attention matrices, and layer normalization, are separated while using a unified transformer backbone for processing text, image, and speech data. This approach enables the model to optimize computation for specific modalities while preserving global self-attention across multi-modal inputs.
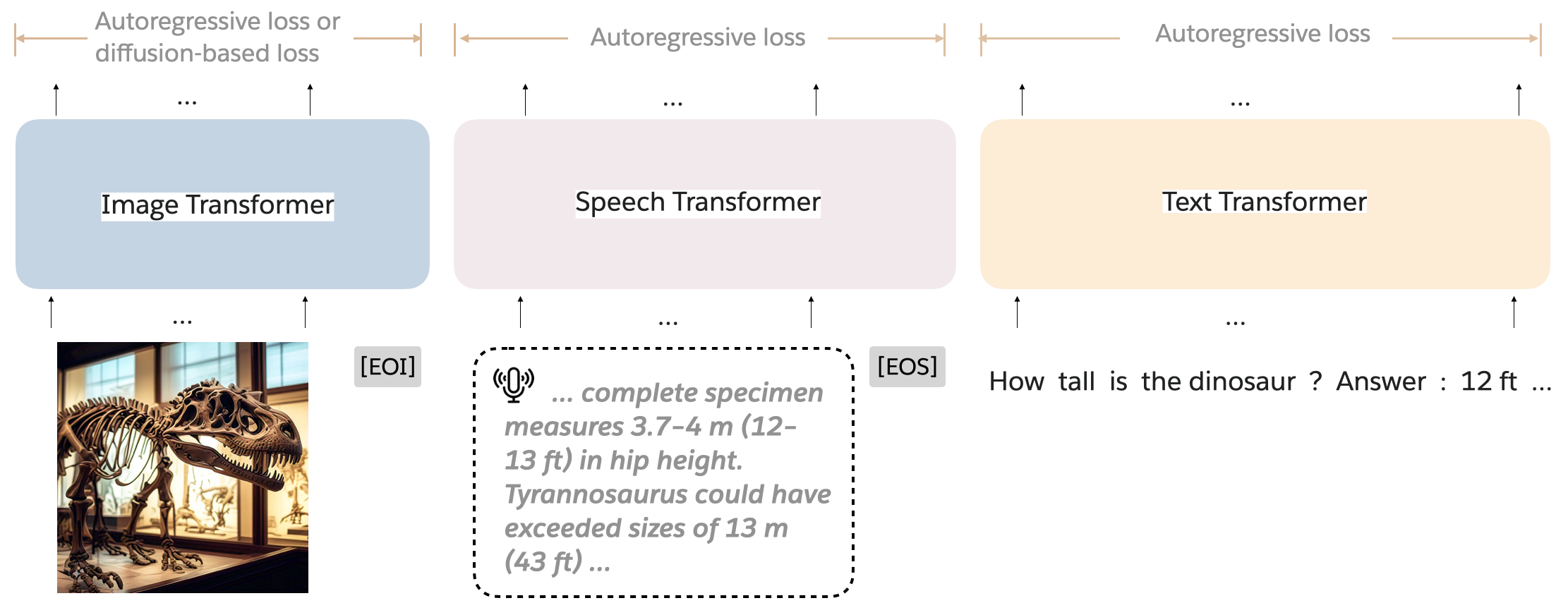
Figure 1: Mixture-of-transformer (MoT) architecture. MoT processes interleaved sequences with detached parameters for each modality.
Key Computational Benefits
- Reduced FLOPs: The MoT architecture requires significantly fewer Floating Point Operations (FLOPs) during training. Specifically, in the Chameleon configuration, MoT achieves comparable performance to a dense baseline while utilizing only 55.8% of the FLOPs for text-and-image tasks.
- Training Efficiency: When extended to incorporate speech, MoT reaches parity with dense models' performance but with only 37.2% of the FLOPs for speech tasks. In multi-objective settings like the Transfusion model, MoT outperforms larger dense baselines using a fraction of their computational budget.
Experiments and Results
Multi-Modal Generative Tasks
MoT was tested under several experimental conditions:
- Chameleon Setting: For autoregressive tasks involving text and images, testing showed MoT reduced training needs by 44.2% without degrading performance.
- Chameleon with Speech: Introducing speech, MoT managed multi-modal tasks effectively with a reduced training footprint.
- Transfusion Setting: Here, MoT worked with autoregressive text and diffusion-based image training objectives, demonstrating improved image generation metrics over dense models.
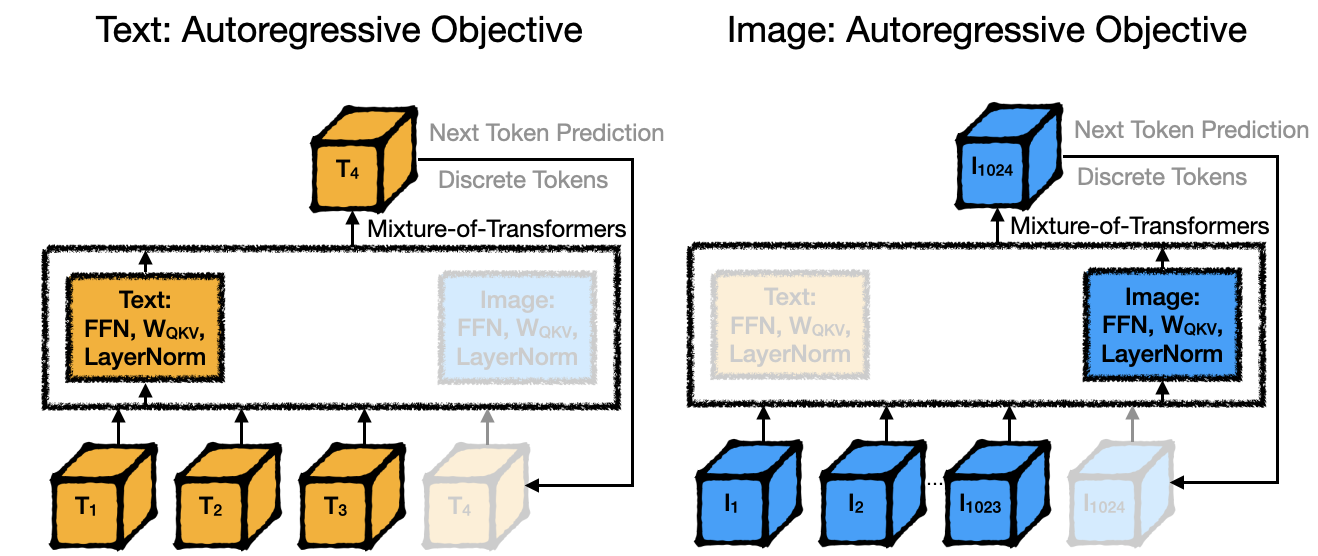
Figure 2: Multi-modal setting with autoregressive text and image objectives.
Comprehensive evaluations reinforced that MoT not only scales efficiently across varied model sizes but also adapts well to other architectures, like Mixture-of-Experts, indicating its versatility. Experiments highlighted MoT’s ability to achieve competitive or superior task performance at substantially reduced computational costs.
Deployment Considerations
System Efficiency: MoT leverages AWS infrastructure for scalability, showcasing reductions in wall-clock training time—MoT achieves significant speedups compared to traditional approaches. For text and image tasks, substantial gains in efficiency and reduced training time without performance loss have practical advantages in large-scale AI deployments.
Conclusion
The Mixture-of-Transformers architecture provides a promising approach for efficiently training multi-modal generative models by intelligently distributing computational loads across modality-specific parameters. The architectural design maximizes performance while minimizing computational demand, making it particularly suitable for extensive AI applications requiring integrated multi-modal capabilities. Future work could further explore architectural scaling and optimization for even larger datasets and additional modalities.