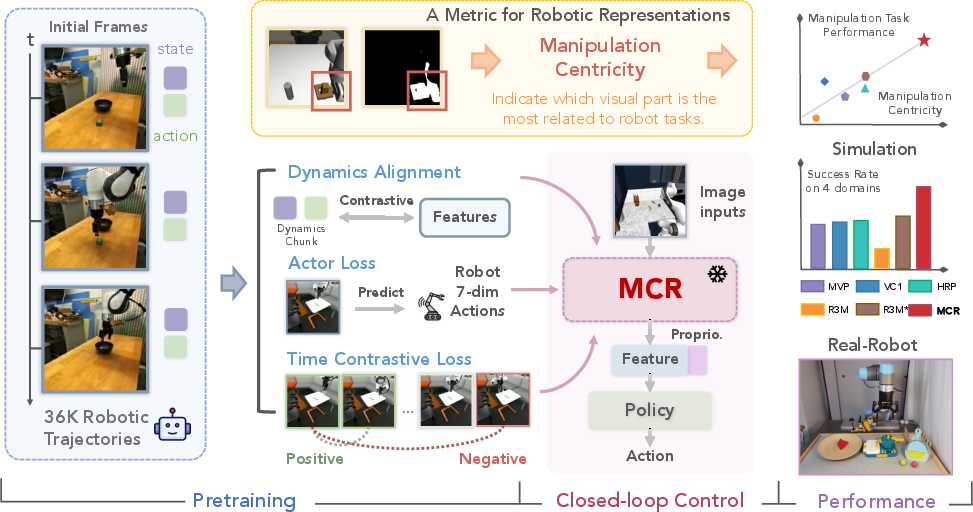
Robots Pre-train Robots: Manipulation-Centric Robotic Representation from Large-Scale Robot Datasets
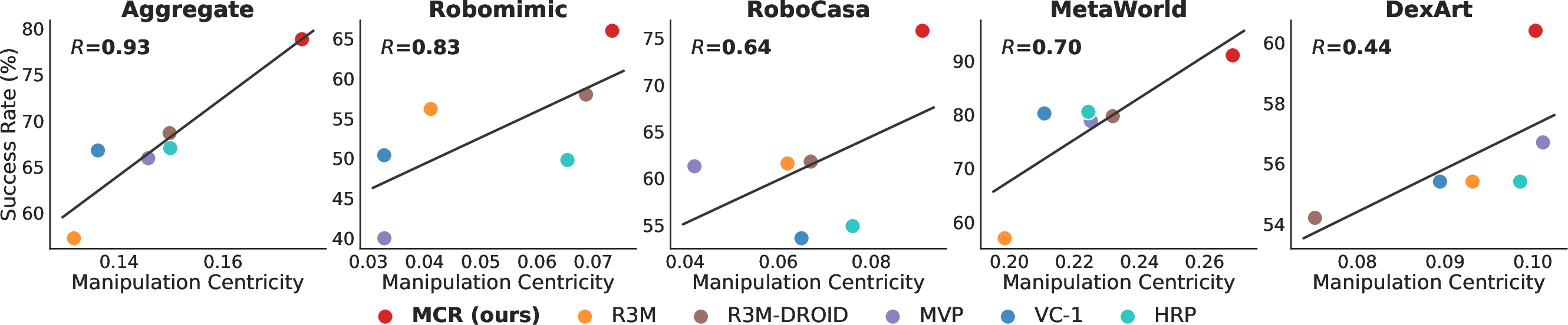
Abstract: The pre-training of visual representations has enhanced the efficiency of robot learning. Due to the lack of large-scale in-domain robotic datasets, prior works utilize in-the-wild human videos to pre-train robotic visual representation. Despite their promising results, representations from human videos are inevitably subject to distribution shifts and lack the dynamics information crucial for task completion. We first evaluate various pre-trained representations in terms of their correlation to the downstream robotic manipulation tasks (i.e., manipulation centricity). Interestingly, we find that the "manipulation centricity" is a strong indicator of success rates when applied to downstream tasks. Drawing from these findings, we propose Manipulation Centric Representation (MCR), a foundation representation learning framework capturing both visual features and the dynamics information such as actions and proprioceptions of manipulation tasks to improve manipulation centricity. Specifically, we pre-train a visual encoder on the DROID robotic dataset and leverage motion-relevant data such as robot proprioceptive states and actions. We introduce a novel contrastive loss that aligns visual observations with the robot's proprioceptive state-action dynamics, combined with a behavior cloning (BC)-like actor loss to predict actions during pre-training, along with a time contrastive loss. Empirical results across 4 simulation domains with 20 tasks verify that MCR outperforms the strongest baseline method by 14.8%. Moreover, MCR boosts the performance of data-efficient learning with a UR5e arm on 3 real-world tasks by 76.9%. Project website: https://robots-pretrain-robots.github.io/.
- A survey of robot learning from demonstration. Robotics and Autonomous Systems, 2009.
- A framework for behavioural cloning. In Machine Intelligence 15, 1995.
- Dexart: Benchmarking generalizable dexterous manipulation with articulated objects. In Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
- Rt-1: Robotics transformer for real-world control at scale. Robotics: Science and Systems (RSS), 2023.
- What makes pre-trained visual representations successful for robust manipulation? arXiv preprint arXiv:2312.12444, 2023.
- Korol: Learning visualizable object feature with koopman operator rollout for manipulation. In Conference on Robot Learning (CoRL), 2024.
- Open X-Embodiment: Robotic learning datasets and RT-X models. In International Conference on Robotics and Automation (ICRA), 2024.
- An unbiased look at datasets for visuo-motor pre-training. In Conference on Robot Learning (CoRL), 2023.
- Imagenet: A large-scale hierarchical image database. In Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
- Bert: Pre-training of deep bidirectional transformers for language understanding. In North American Chapter of the Association for Computational Linguistics (NAACL), 2019.
- An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2021.
- Masked autoencoders as spatiotemporal learners. Advances in neural information processing systems, 35:35946–35958, 2022.
- The” something something” video database for learning and evaluating visual common sense. In International Conference on Computer Vision (ICCV), 2017.
- Ego4d: Around the world in 3,000 hours of egocentric video. In Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
- On pre-training for visuo-motor control: Revisiting a learning-from-scratch baseline. In International Conference on Machine Learning (ICML), 2023.
- Deep residual learning for image recognition. In Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- Masked autoencoders are scalable vision learners. In Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
- Olivier Henaff. Data-efficient image recognition with contrastive predictive coding. In International Conference on Machine Learning (ICML), 2020.
- Diffusion reward: Learning rewards via conditional video diffusion. European Conference on Computer Vision (ECCV), 2024.
- Ace: Off-policy actor-critic with causality-aware entropy regularization. arXiv preprint arXiv:2402.14528, 2024.
- Learning manipulation by predicting interaction. Robotics: Science and Systems (RSS), 2024.
- Droid: A large-scale in-the-wild robot manipulation dataset. Robotics: Science and Systems, 2024.
- Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024.
- Diederik P Kingma. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015.
- CURL: Contrastive unsupervised representations for reinforcement learning. In International Conference on Machine Learning (ICML), 2020.
- Make-an-agent: A generalizable policy network generator with behavior-prompted diffusion. arXiv preprint arXiv:2407.10973, 2024.
- VIP: Towards universal visual reward and representation via value-implicit pre-training. In International Conference on Learning Representations (ICLR), 2023.
- Where are we in the search for an artificial visual cortex for embodied intelligence? In International Conference on Neural Information Processing Systems (NeurIPS), 2023.
- What matters in learning from offline human demonstrations for robot manipulation. In Conference on Robot Learning (CoRL), 2021.
- Deep reinforcement and infomax learning. In Advances in Neural Information Processing Systems, 2020.
- R3m: A universal visual representation for robot manipulation. In Conference on Robot Learning (CoRL), 2022.
- Robocasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems (RSS), 2024.
- The unsurprising effectiveness of pre-trained vision models for control. In International Conference on Machine Learning (ICML), 2022.
- Robot learning with sensorimotor pre-training. In Conference on Robot Learning (CoRL), 2023.
- Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714, 2024.
- Grad-cam: Visual explanations from deep networks via gradient-based localization. In International Conference on Computer Vision (ICCV), 2017.
- Masked world models for visual control. In Conference on Robot Learning (CoRL), 2022.
- Theia: Distilling diverse vision foundation models for robot learning. In Conference on Robot Learning (CoRL), 2024.
- Hrp: Human affordances for robotic pre-training. Robotics: Science and Systems (RSS), 2024.
- Decoupling representation learning from reinforcement learning. In International Conference on Machine Learning (ICML), 2021.
- Octo: An open-source generalist robot policy. Robotics: Science and Systems (RSS), 2024.
- Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2019.
- Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of Machine Learning Research (JMLR), 2008.
- Bridgedata v2: A dataset for robot learning at scale. In Conference on Robot Learning (CoRL), 2023.
- Masked visual pre-training for motor control. In Conference on Robot Learning (CoRL), 2022.
- Drm: Mastering visual reinforcement learning through dormant ratio minimization. In International Conference on Learning Representations (ICLR), 2023.
- Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on Robot Learning (CoRL), 2019.
- Pre-trained image encoder for generalizable visual reinforcement learning. Advances in Neural Information Processing Systems, 35:13022–13037, 2022.
- 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. Robotics: Science and Systems (RSS), 2024.
- Learning fine-grained bimanual manipulation with low-cost hardware. Robotics: Science and Systems (RSS), 2023.
- TACO: Temporal latent action-driven contrastive loss for visual reinforcement learning. In International Conference on Neural Information Processing Systems (NeurIPS), 2023.
- Premier-taco: Pretraining multitask representation via temporal action-driven contrastive loss. In International Conference on Machine Learning (ICML), 2024.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.