- The paper introduces the TRON framework as a two-step method using conformal scores for sampling and nonconformity scores for identification in multimodal LLMs.
- It effectively bounds empirical error rates and adjusts prediction set sizes, demonstrating consistent reliability across both open-ended and closed-ended VideoQA datasets.
- The study confirms TRON's efficiency and stability through extensive experiments, offering a significant advancement for API-only multimodal models.
Sample then Identify: A General Framework for Risk Control and Assessment in Multimodal LLMs
Introduction
This research introduces TRON, a two-step framework for risk management and evaluation in Multimodal LLMs (MLLMs), addressing the need for reliable assessment tools across both open-ended and closed-ended queries. The framework is distinct from previous methodologies by not relying on internal logits or being limited to multiple-choice settings. Instead, it offers a universal approach applicable to any MLLM supporting sampling operations.
TRON Framework
The TRON framework is composed of two primary components:
- Conformal Score for Sampling: This component regulates the minimum number of responses required to sample for each test data point from the calibration set, ensuring that the response set meets a predetermined confidence level.
- Nonconformity Score for Identification: Based on self-consistency theory, this score identifies high-quality responses. It utilizes the frequency of responses as a proxy for confidence, mitigating the limitation of accessing internal model logits.
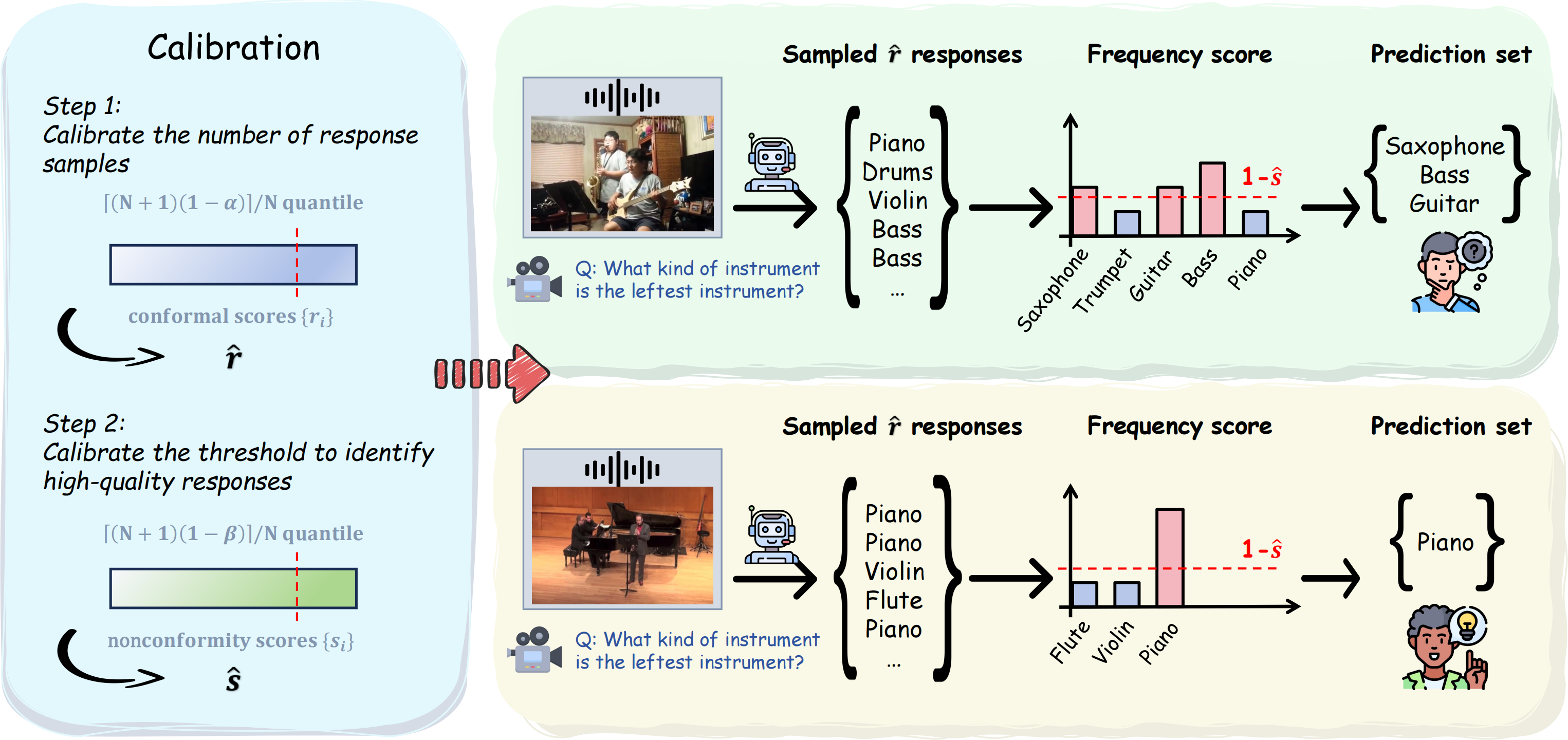
Figure 1: Pipeline of TRON illustrated by two open-ended VideoQA examples. Step 1 calibrates the minimum number of responses required to sample for each test data point on the calibration set; Step 2 calibrates the threshold to identify high-quality responses.
Experiments and Results
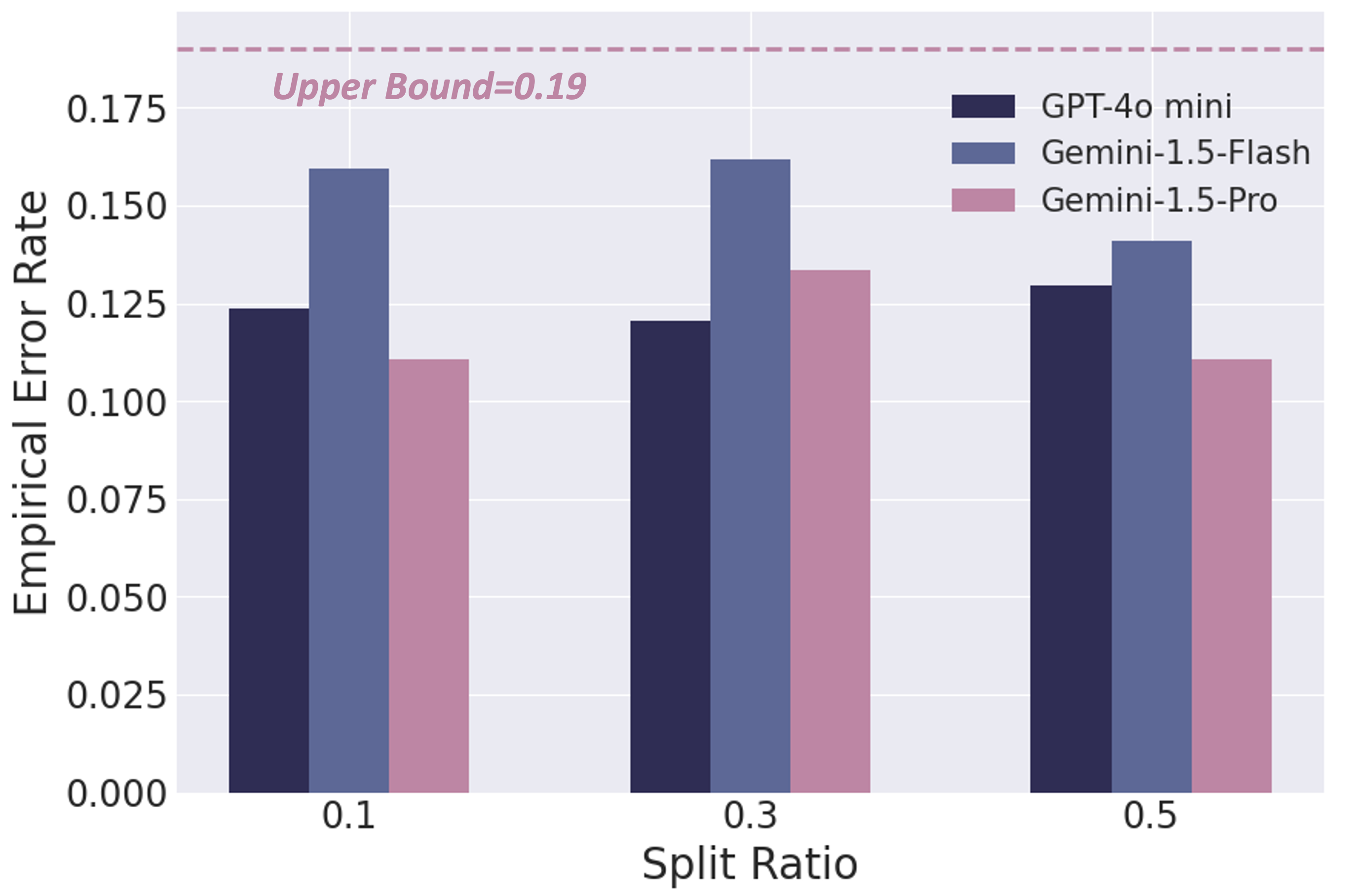
The framework was evaluated across four VideoQA datasets—both open-ended (e.g., MUSIC-AVQA) and closed-ended (e.g., Video-MME)—utilizing eight MLLMs. It effectively bounded the error rates within two user-specified risk levels, confirming the ability to provide statistically rigorous guarantees for error rates. The deduplicated prediction sets were found more stable and efficient under varying risk levels.
Key empirical findings include:
- Empirical Error Rate (EER): Consistently bounded by specified risk levels, demonstrating the reliability of TRON across different datasets and MLLMs (see Figure 2).
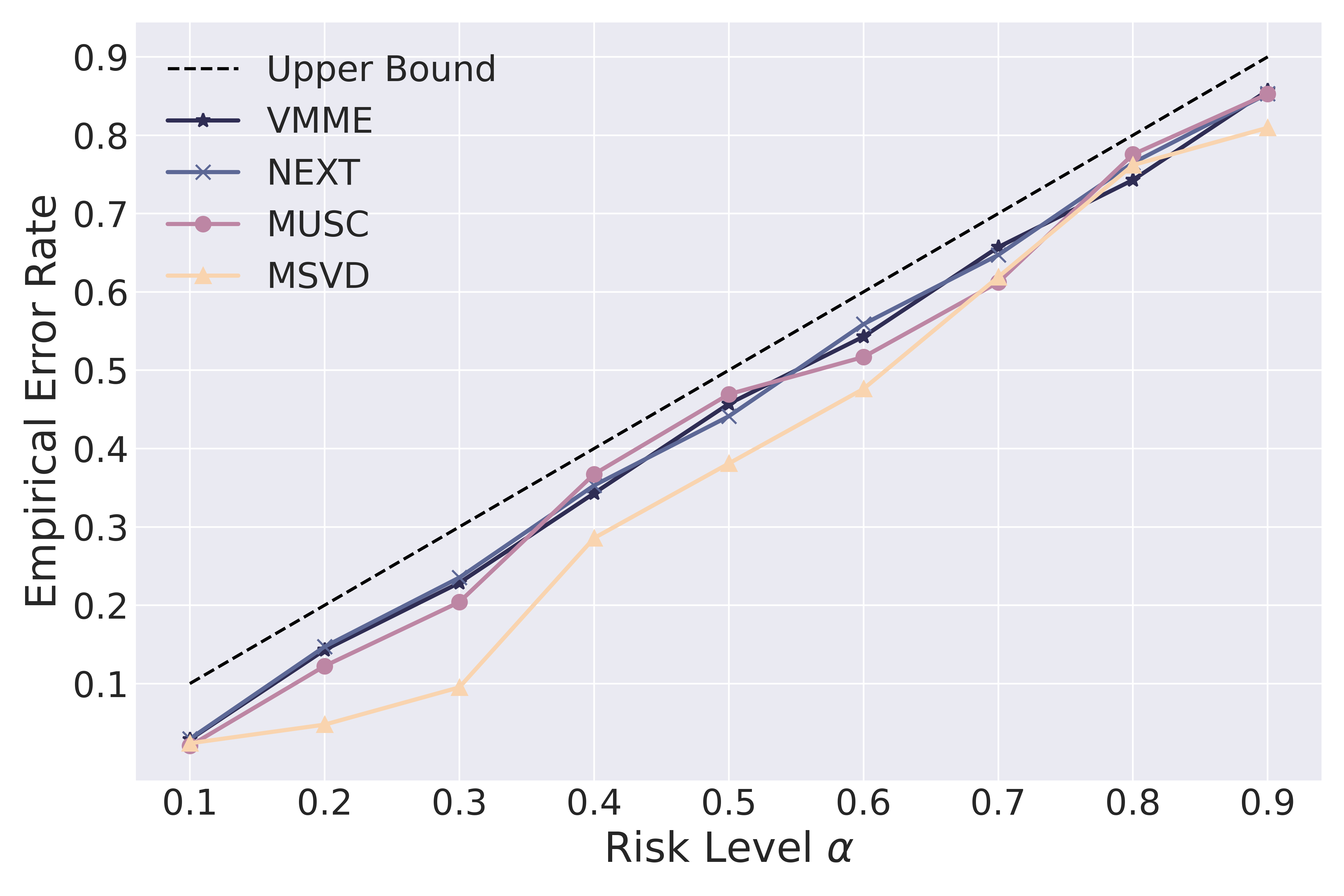
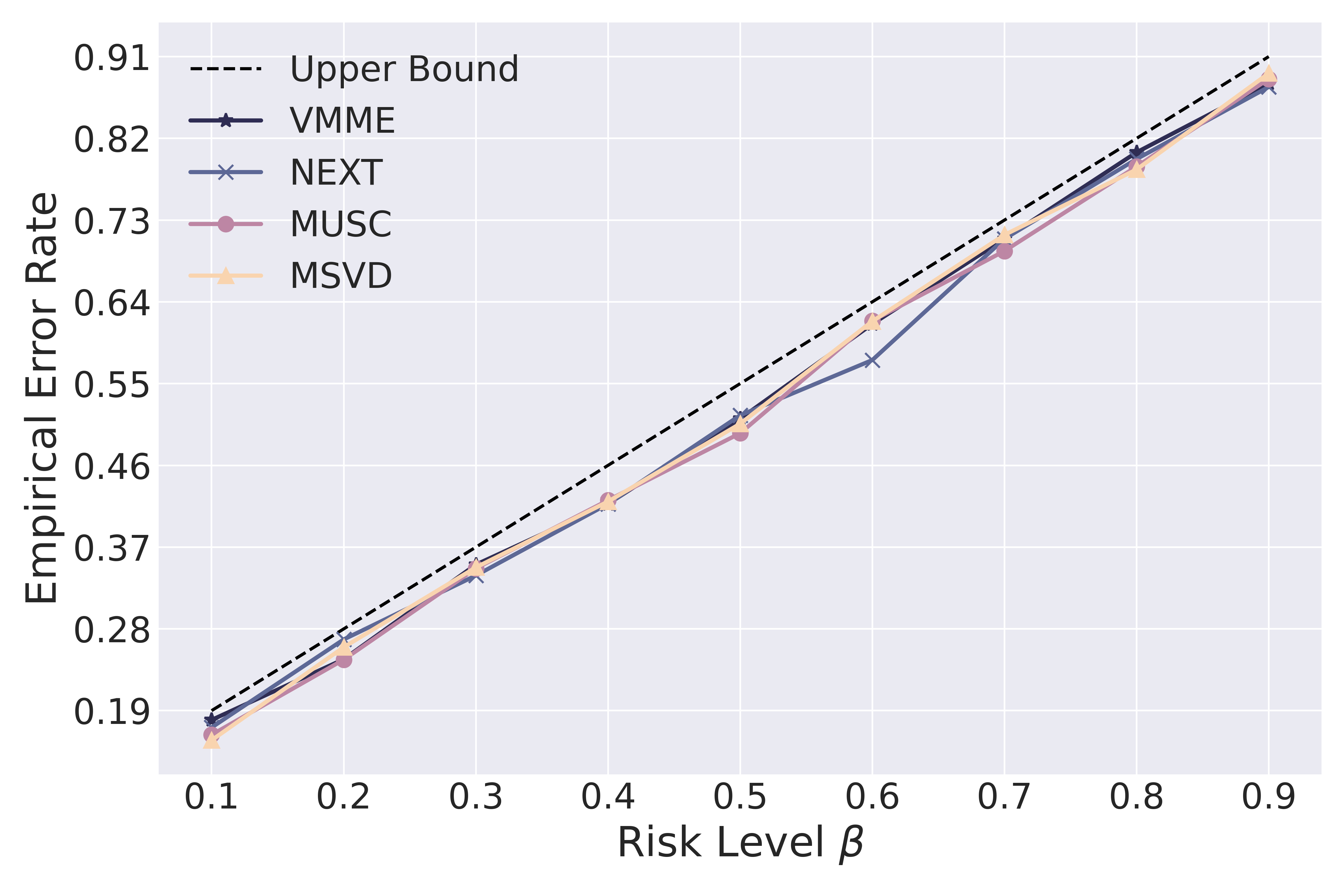
Figure 2: EER vs. risk level alpha.
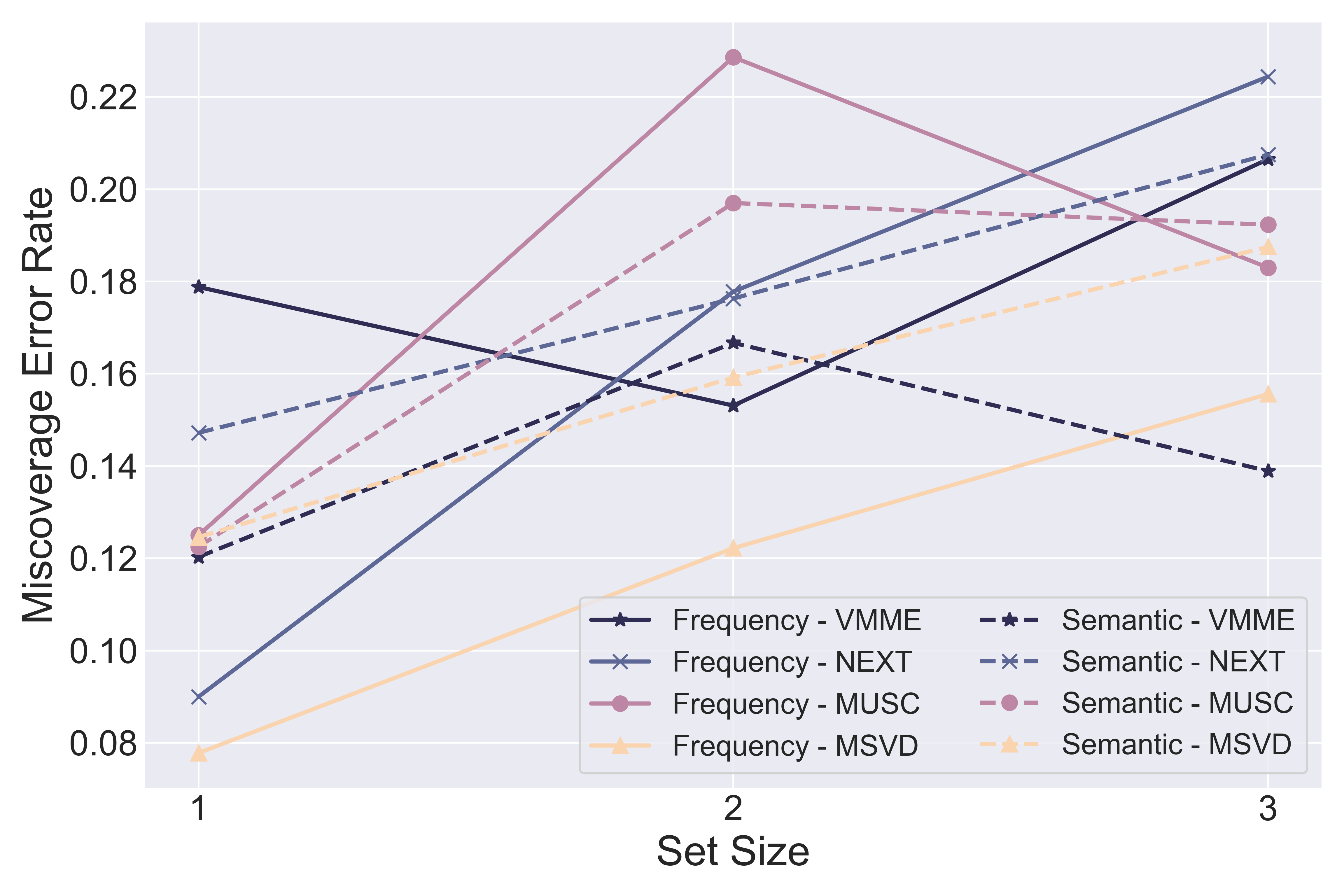
- Average Prediction Set Size (APSS): Adjusted for semantic redundancy, offering a stable metric for uncertainty and enhancing evaluation consistency across risk levels (see Figure 3).
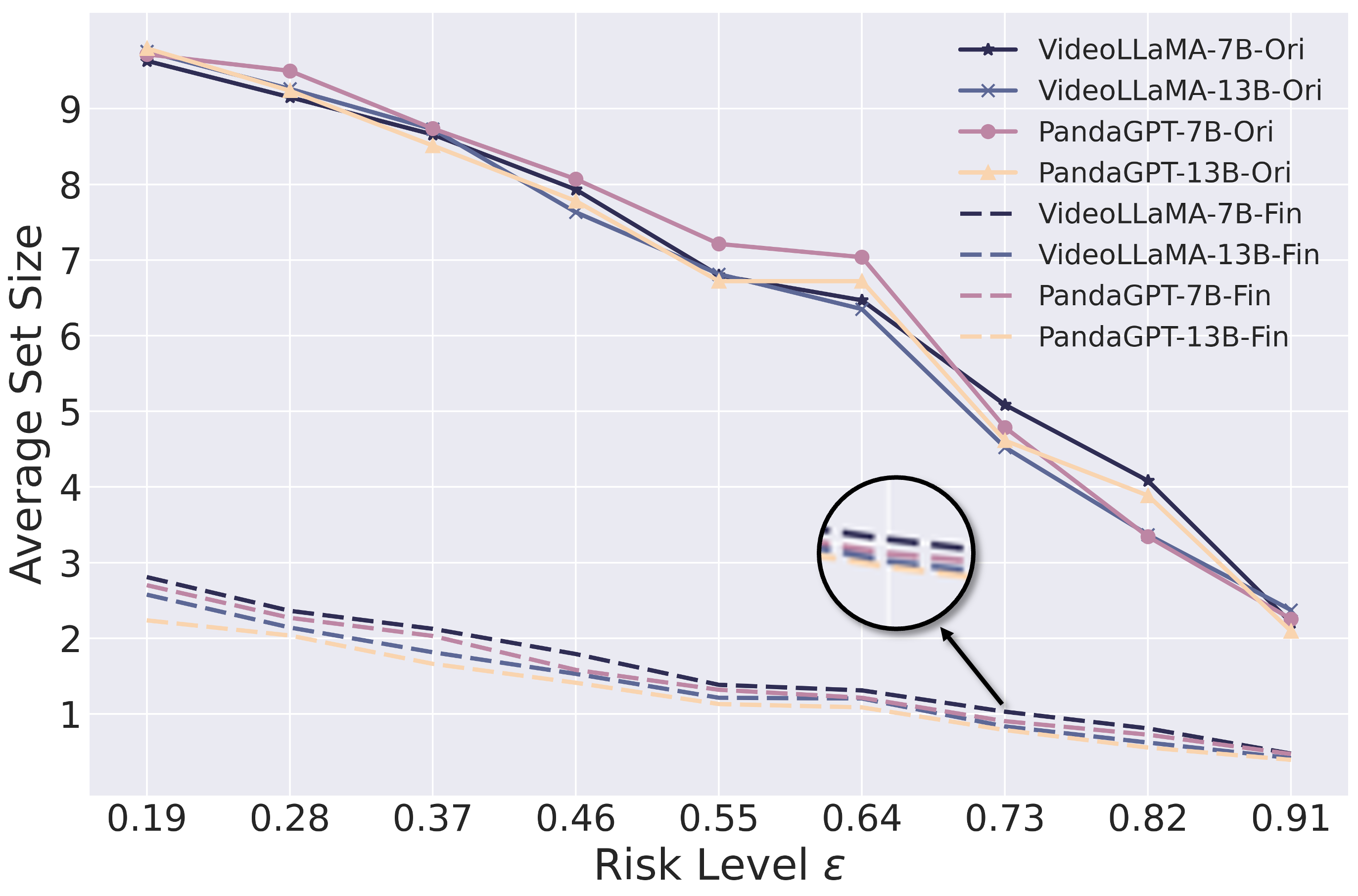
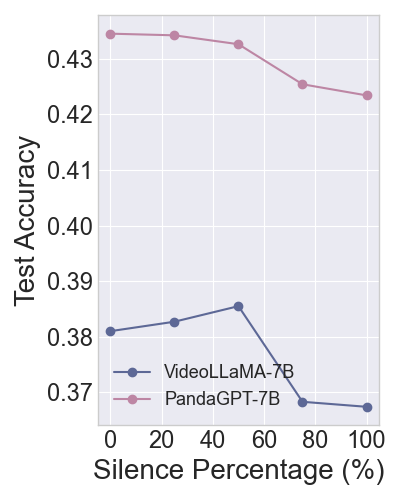
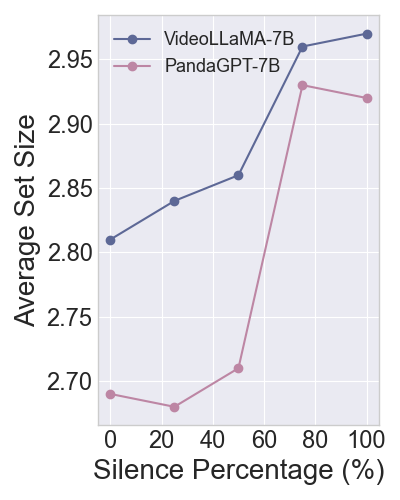
Figure 3: Comparison of APSS before and after duplication at different risk levels (ε) across four open-source MLLMs on the VMME dataset.
Methodological Insights
The TRON framework's reliability is further enhanced by exploring different black-box measures for nonconformity scores, like semantic diversity, which proved effective in reducing APSS and bolstering prediction efficiency without exceeding miscoverage rates.
Conclusion
The TRON framework is a robust, versatile tool for managing risk in MLLMs across diverse applications, from open-ended VideoQA to multiple-choice scenarios. Its adaptability to black-box settings marks a significant advancement for API-only MLLMs. The proposed methodology surpasses previous constraints of SCP methods, delivering reliable risk control and evaluation metrics, thereby facilitating comprehensive assessments of MLLMs in real-world applications.
Future research will extend TRON's capabilities under distribution shift conditions and explore further refinements in the design of nonconformity scores for enhanced efficiency and reliability in complex multimodal contexts.