- The paper presents a comprehensive survey on SpeechLM advancements, highlighting an end-to-end approach that eliminates traditional modality conversion losses.
- It details the integration of speech tokenizers, transformer-based language models, and vocoders for seamless handling of semantic and acoustic information.
- The survey evaluates multi-stage training methodologies and emphasizes challenges such as latency, domain safety, and low-resource language performance.
Recent Advances in Speech LLMs: A Survey
This essay provides a comprehensive analysis of the survey paper titled "Recent Advances in Speech LLMs: A Survey" (2410.03751), exploring the evolution and capabilities of Speech LLMs (SpeechLMs) as an advancement over traditional pipeline approaches involving Automatic Speech Recognition (ASR), LLMs, and Text-to-Speech (TTS) systems.
Introduction to Speech LLMs
The paper begins by outlining the limitations inherent in the traditional ASR + LLM + TTS cascade. These include information loss during modality conversion, latency introduced by sequential processing, and cumulative errors across stages. Speech LLMs (SpeechLMs) present a cohesive end-to-end structure that mitigates these issues by processing speech natively without intermediate text conversion. SpeechLMs encapsulate both semantic and paralinguistic information, offering a more integrated approach to human-computer verbal interaction.

Figure 1: Architectures of the ``ASR + LLM + TTS" framework and a SpeechLM. We emphasize that, for SpeechLM, the same content can be used across both speech and text modalities, meaning that any input modality can yield any output modality of the same results.
Architectural Components of SpeechLMs
SpeechLMs integrate several key architectural elements: speech tokenizers, LLMs, and vocoders. These components collectively allow SpeechLMs to operate seamlessly across speech modalities.
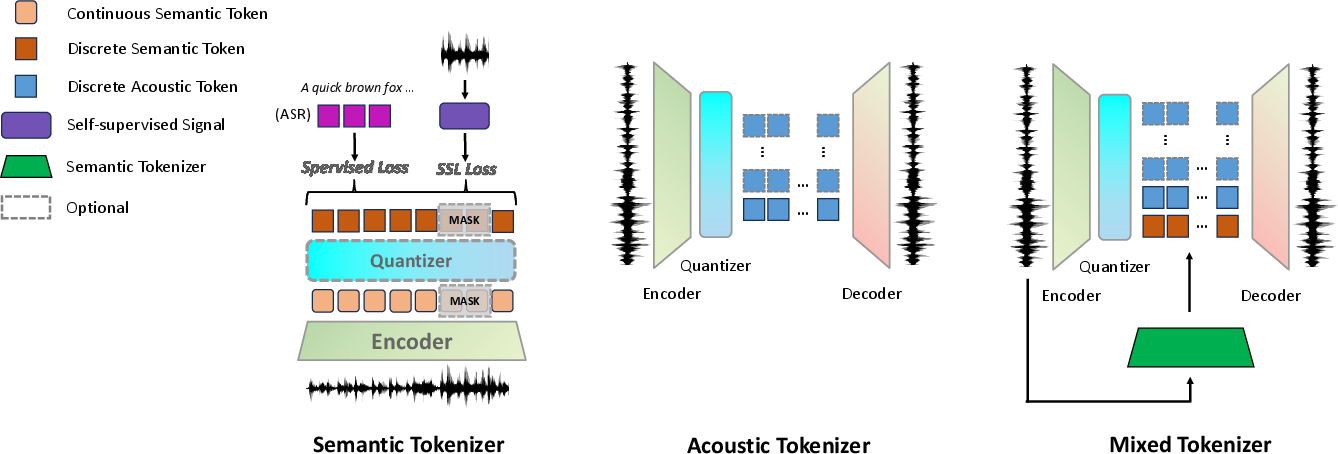
Speech Tokenizers
Speech tokenizers convert continuous speech inputs into quantized representations, categorized into semantic, acoustic, and mixed objectives. Each category targets different aspects of audio processing:
LLMs and Vocoders
SpeechLMs utilize transformer-based LLMs to handle the sequence of speech tokens for autoregressive processing. These models leverage architectures such as decoder-only transformers, modified to integrate speech tokens directly. The vocoders subsequently synthesize the processed tokens back into audio waveforms, closing the input-output loop inherent in speech communication.
Training Methodologies
The training process for SpeechLMs mirrors multi-stage methodologies seen in text-based LMs. It begins with pre-training, advances through instruction-tuning, and concludes with post-alignment.
- Pre-Training: Leverages large-scale speech corpora to adapt transformer architectures to process speech tokens directly, often with cold initialization or continued pre-training from text-based models (2410.03751).
- Instruction-Tuning: Focuses on enhancing model capabilities for following linguistic instructions, thereby broadening the range of interactive applications.
- Post-Alignment: Aligns model outputs with human preferences using techniques like Reinforcement Learning from Human Feedback (RLHF), ensuring the generation model remains contextually and ethically aligned.
Evaluation and Challenges
The survey delineates a comprehensive evaluation landscape, categorizing assessments into automatic and human-evaluated methodologies. Automatic evaluations measure representational fidelity and linguistic competence, while human evaluations focus on perceptual audio quality.
Crucially, the paper identifies several ongoing challenges. These include optimizing end-to-end SpeechLM training to further reduce latency, addressing domain-specific safety issues, and enhancing performance on "low-resource" languages where textual data may be sparse but spoken data is prevalent.
Conclusion
Speech LLMs signify an evolutionary leap in verbal AI, offering the potential for fluid, naturalistic human-machine interaction. They not only simplify the pipeline by eliminating conversion steps but also enhance real-time performance and semantic understanding. As research in this domain progresses, the focus on refining interactive capabilities, enhancing training methodologies, and addressing remaining challenges will be pivotal in advancing the state of speech-based AI systems.