- The paper introduces a dynamic computation allocation method, leveraging TDW and SDT to reduce FLOPs and improve efficiency in diffusion-based image generation.
- It adopts a FLOPs-constrained loss and router training mechanisms (Gumbel-Sigmoid and straight-through estimators) to preserve performance while reducing redundant computation.
- Experimental results show DyDiT-XL achieves 51% FLOPs reduction and 1.73× acceleration, outperforming static pruning methods while maintaining image quality.
Motivation and Problem Analysis
Diffusion Transformer (DiT) architectures have established themselves as state-of-the-art for image generation, but their inference is characterized by substantial computational redundancy. Through loss map and comparative analysis of DiT-S versus DiT-XL (Figure 1), two forms of redundancy are exposed: (1) the prediction task complexity at later timesteps diminishes such that smaller models are sufficient, yet DiT statically allocates full computation across all timesteps; (2) spatial prediction difficulty is heterogeneous—object-containing patches are harder to denoise than background patches—yet computation is uniformly applied. This indicates that a dynamic, context-sensitive computation allocation would avoid wasted FLOPs and improve hardware efficiency.
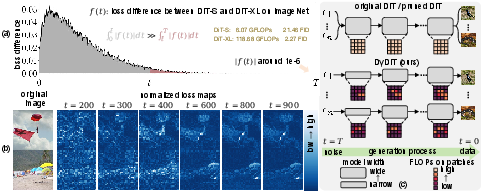
Figure 1: (a) The loss difference between DiT-S and DiT-XL, showing minor differences at most timesteps; (b) loss maps for different timesteps highlight spatial difficulty variation; (c) static inference in DiT versus dynamic inference in DyDiT.
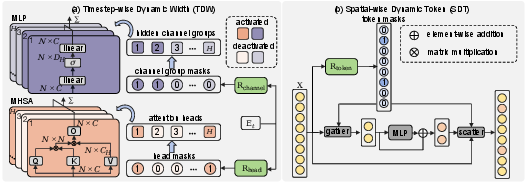
DyDiT Architecture: TDW and SDT Design
To address these inefficiencies, the Dynamic Diffusion Transformer (DyDiT) is introduced, incorporating two mutually orthogonal dynamic mechanisms:
FLOPs-Constrained Training and Stabilization
DyDiT employs an end-to-end training scheme with a bespoke FLOPs-constrained loss. The objective ensures the proportion of dynamic FLOPs to static FLOPs matches a user-defined target λ, using masks aggregated across sampled timesteps in a batch, while standard DiT loss is preserved for performance. To stabilize fine-tuning, DyDiT maintains a full DiT model with the same supervision for a warm-up phase and preselects at least one head and channel group per block, ranking by magnitude. Gumbel-Sigmoid and straight-through estimators are used for router training.
Experimental Evaluation and Results
The DyDiT framework is validated on ImageNet (256×256) and multiple fine-grained datasets, with three model scales: S, B, XL. DyDiT-XL achieves 51% reduction in FLOPs, 1.73× acceleration in generation speed, and a competitive FID score of 2.07 for λ=0.5, using less than 3% additional fine-tuning iterations.
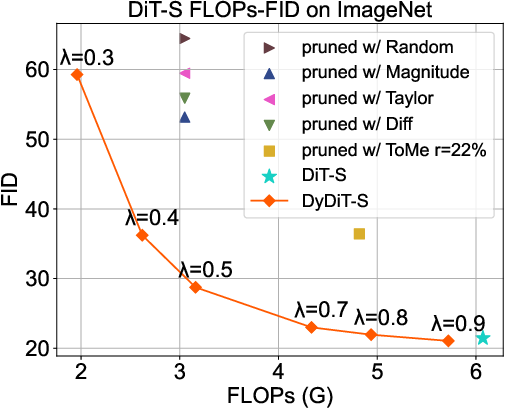
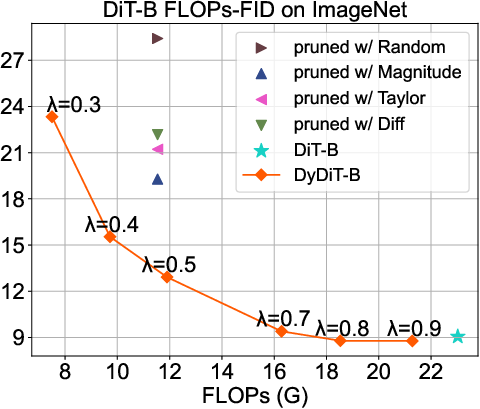
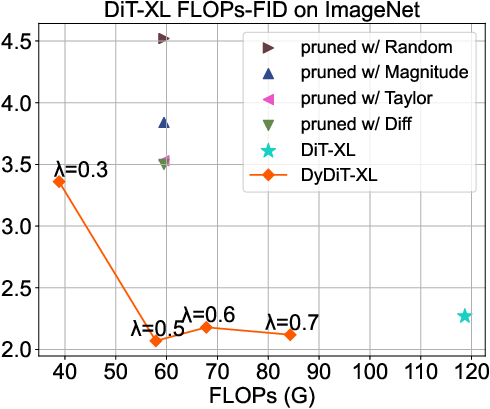
Figure 3: FLOPs-FID trade-off across model sizes; DyDiT demonstrates superior efficiency-performance balance compared to pruning and token merging methods.
DyDiT outperforms all static pruning baselines (Taylor, Magnitude, Diff, Random, ToMe) at matched computational cost. The scaling analysis reveals that larger models (XL) benefit more from DyDiT, as computation redundancy increases with model size.
Ablation Studies
The ablation studies demonstrate that TDW provides most of the FLOPs savings and performance preservation, whereas SDT alone results in significant quality degradation for aggressive FLOPs reduction. The combination realizes near-optimal trade-offs. Routers must be learnable—random or manually designed masks result in severe collapse or suboptimal generation. Token-level bypassing within MLP is superior to layer-skipping, confirming spatial heterogeneity in denoising difficulty.
Visualization of Dynamic Strategies
The learned dynamic architecture manifests as a gradual increase in activated heads and channels as the generation step approaches the clean image, consistent with predicted difficulty at earlier diffusion steps (Figure 4).
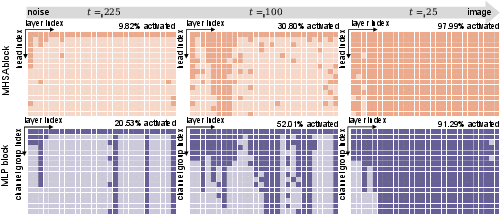
Figure 4: Dynamic architecture visualization; more MHSA heads and MLP channels are activated in early timesteps.
Spatial computation analysis shows SDT allocates higher FLOPs to object-rich patches, reducing MLP computation for background regions (Figure 5).
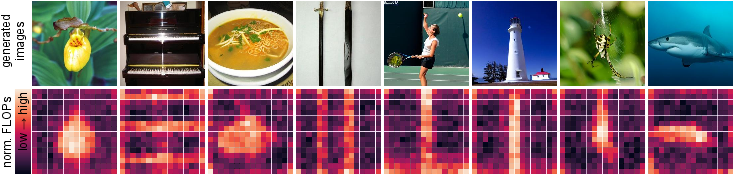
Figure 5: Computational cost heatmaps for image patches; main object regions consume more FLOPs than background regions.
Compatibility and Extension
DyDiT is compatible with efficient samplers (DDIM, DPM Solver++) and global acceleration techniques (DeepCache). Combination experiments show further acceleration and competitive FID even with drastically reduced steps. DyDiT’s architecture can generalize to U-ViT and PixArt-based models, scaling to high-resolution and text-to-image tasks. The framework is robust to limited fine-tuning data and maintains training efficiency.
Qualitative Results
Qualitative image comparisons (Figure 6) indicate that DyDiT generates outputs at similar visual fidelity as full DiT-S, with superior trade-offs to pruned baselines.

Figure 6: Image samples from DiT, DiT pruned with magnitude, and DyDiT; DyDiT matches original generation quality with substantially reduced computation.
Implications and Future Directions
DyDiT introduces a foundational methodological advance for structured dynamic computation in diffusion models. Practically, it enables substantial hardware efficiency gains in image generation—critical for deployment in large-scale and constraint settings. Theoretically, the method opens avenues for learning route-based dynamic architectures that respond to temporal and spatial complexity, prompting future research in (a) video generation models, (b) controllable generation, (c) integration with advanced distillation samplers, and (d) dynamic models for other domains including text and audio.
Conclusion
Dynamic Diffusion Transformer (DyDiT) systematically reduces computational redundancy in Transformer-based diffusion models by leveraging learned timestep and spatial dynamic allocation. The approach attains substantial efficiency improvements while preserving generative quality, outperforming traditional pruning and token reduction techniques. DyDiT advances the state-of-the-art in adaptive inference for diffusion models, with strong implications for future efficient large-scale generative modeling (2410.03456).