- The paper introduces Moshi, a unified speech-to-speech model that significantly reduces dialogue latency by integrating linguistic, semantic, and acoustic cues.
- It leverages a 7-billion-parameter Helium language model, the Mimi neural audio codec, and a hierarchical RQ-Transformer for efficient multi-stream audio processing.
- The model demonstrates state-of-the-art performance in spoken question-answering and real-time dialogue applications, paving the way for next-gen conversational AI.
Moshi: A Speech-Text Foundation Model for Real-Time Dialogue
Abstract
The introduction of Moshi marks a significant advancement in the field of spoken dialogue systems. Moshi is designed as a full-duplex spoken dialogue framework that addresses the inherent limitations of existing systems, such as latency and the loss of non-linguistic information. By casting spoken dialogue as a speech-to-speech generation task, Moshi leverages a bespoke text LLM backbone to generate speech directly from neural audio codec tokens, thus enabling real-time interactions without explicit segmentation into speaker turns.
Introduction
Moshi revolutionizes voice interaction by moving beyond traditional pipelined architectures that rely on independent components like ASR, NLU, and TTS, which introduce latency and information loss. Instead, Moshi treats dialogue as a unified speech-to-speech generation process, integrating non-verbal cues such as emotions and environmental sounds into the interaction model. This capability is crucial for achieving natural conversation flow, handling interruptions, and overlapping speech, which are common in real dialogues but inadequately managed by current systems.
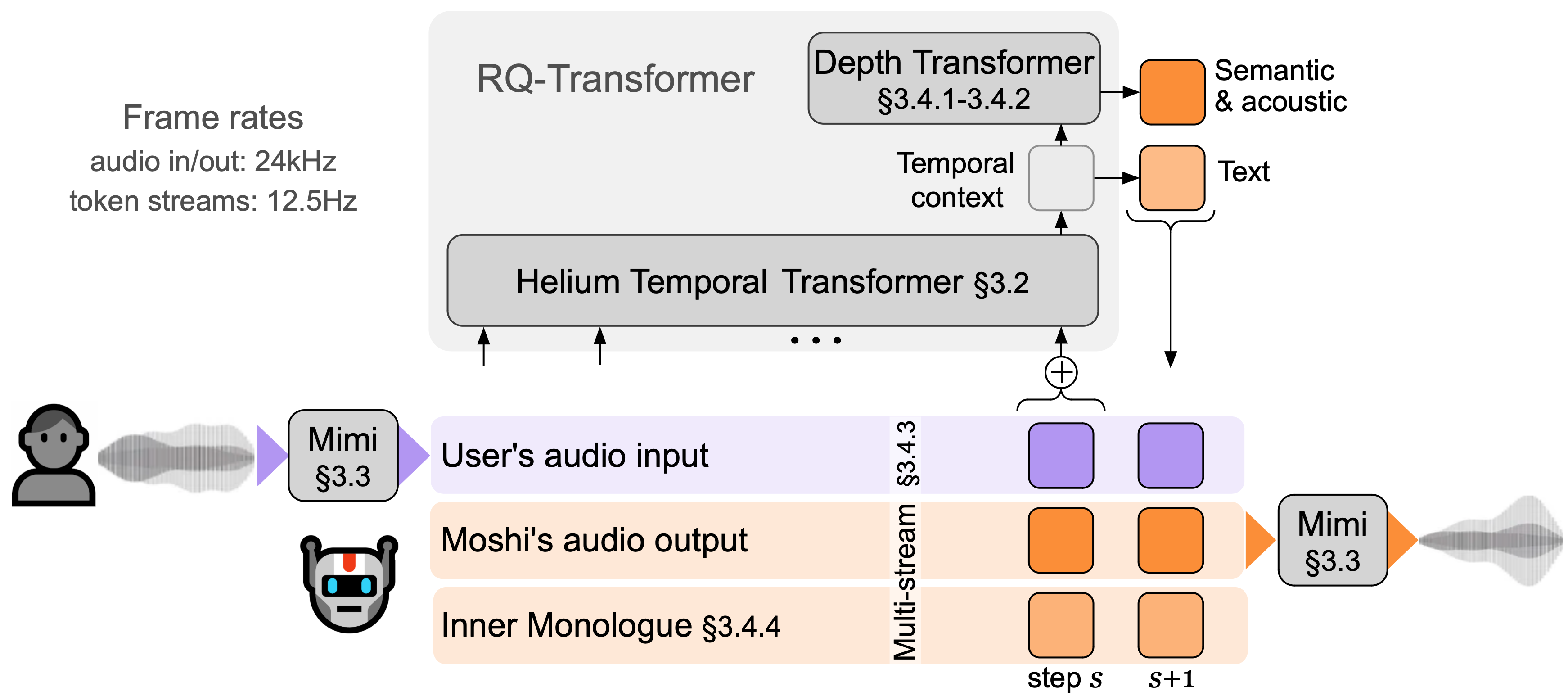
Figure 1: Overview of Moshi. Moshi is a speech-text foundation model which enables real-time spoken dialogue.
Key Components
Helium LLM
The core of Moshi's architecture is the Helium LLM, a 7-billion parameter text LLM pre-trained on a vast corpus of English data. Helium's design emphasizes efficiency and depth, employing RMSNorm for stability and RoPE for improved position encoding across a context size of 4096 tokens. This model serves as the backbone for Moshi, ensuring robust linguistic capabilities.
Mimi Neural Audio Codec
Mimi is a novel neural audio codec that utilizes residual vector quantization to transform audio into discrete tokens, effectively capturing both semantic and acoustic information. During training, Mimi distills semantic knowledge from non-causal embeddings, enhancing the real-time encoding and decoding of audio signals.
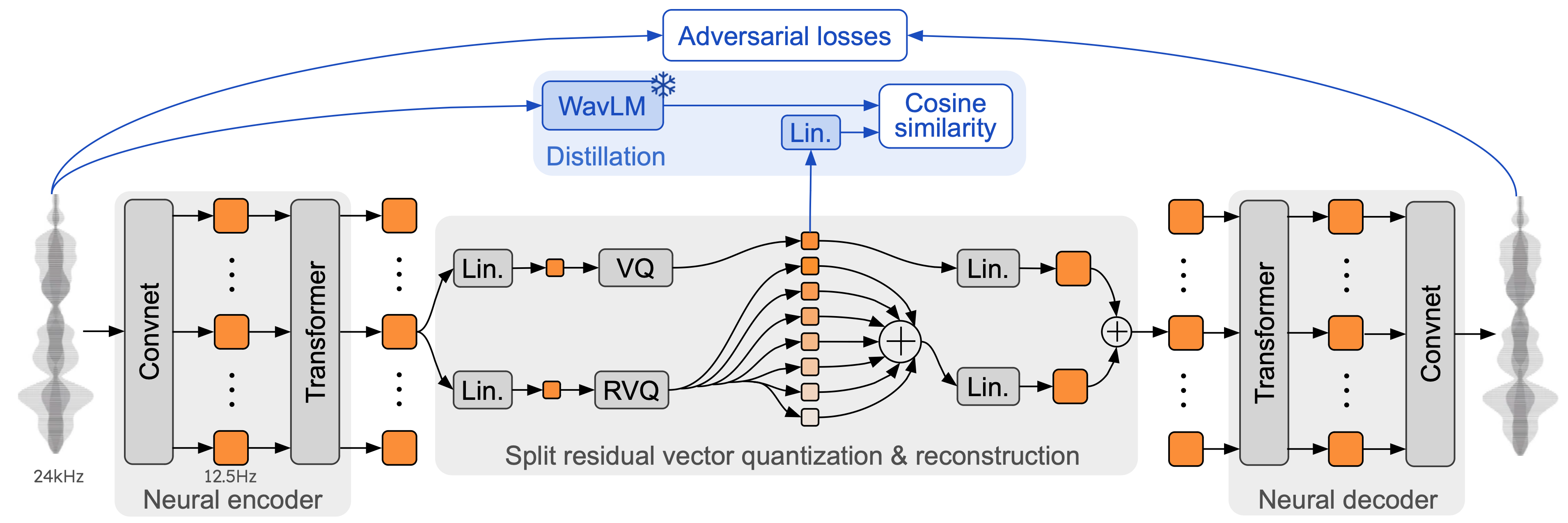
Figure 2: Architecture and training of Mimi, our neural audio codec, with its split residual vector quantization.
Moshi integrates hierarchical generation through the RQ-Transformer, which conditions smaller Depth Transformers on a large Temporal Transformer context. This hierarchical design allows Moshi to model longer sequences efficiently and supports the parallel generation of audio tokens, vital for sustaining real-time dialogue without compromising linguistic coherence.
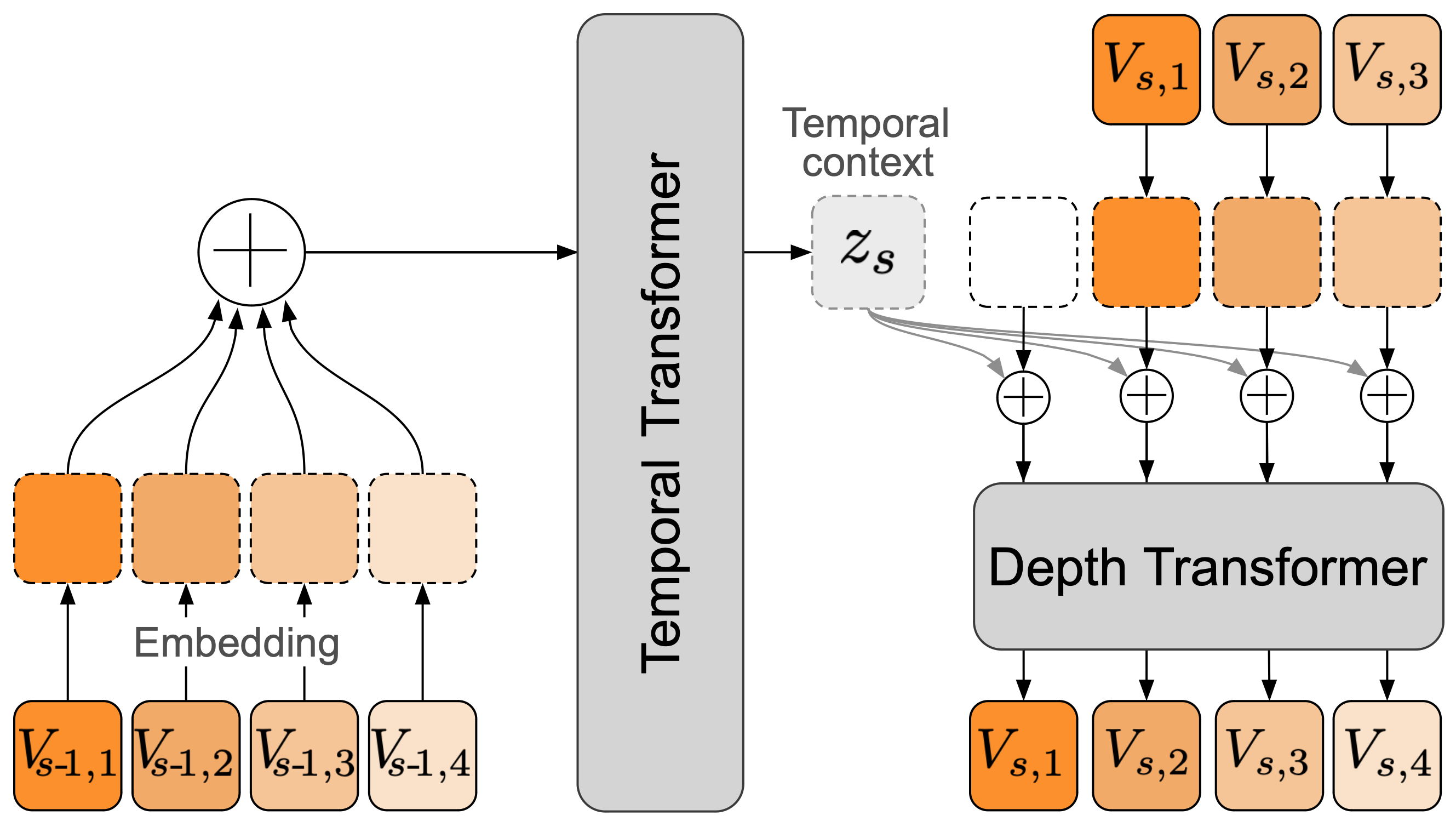
Figure 3: Architecture of the RQ-Transformer. The RQ-Transformer breaks down a flattened sequence into manageable steps for multi-scale processing.
Inner Monologue and Multi-Stream Audio Modeling
The integration of Inner Monologue within Moshi enables a unique training and inference setup that predicts text and audio tokens in sequence. This innovation not only streamlines speech generation but also allows Moshi to simultaneously process multiple audio streams, merging Moshi's voice and user input in a fluid conversational exchange.
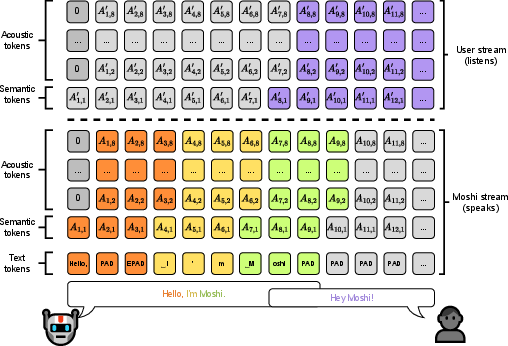
Figure 4: Representation of the joint sequence modeled by Moshi.
Evaluation and Implications
Moshi's architecture demonstrates superior performance in both traditional benchmarks and new metrics devised for speech-text models. It achieves state-of-the-art results in spoken question answering while maintaining the capability to produce coherent and contextually rich dialogues. The extension of Moshi to tasks such as streaming ASR and TTS further illustrates its versatility, introducing new paradigms for real-time speech processing.
Conclusion
Moshi stands as a pioneering model in speech-text foundations, pushing the boundaries of what is feasible in real-time dialogue systems. Its ability to integrate linguistic, semantic, and acoustic information in a cohesive framework represents a notable leap towards achieving truly natural conversational AI. With its publicly available model, Moshi lays the groundwork for future innovations in AI-driven spoken dialogue systems.
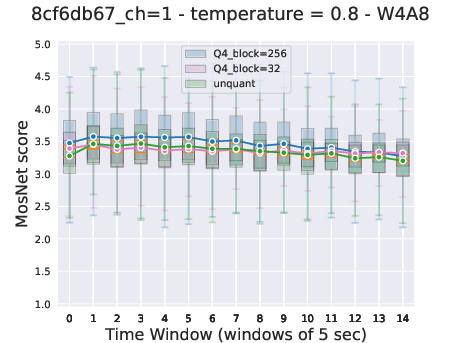
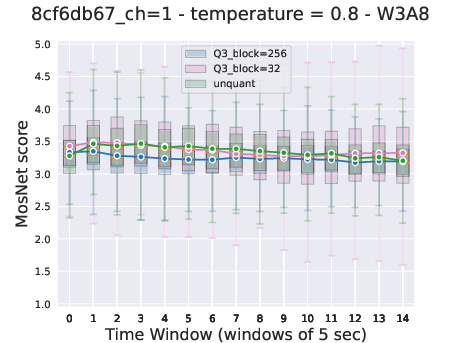
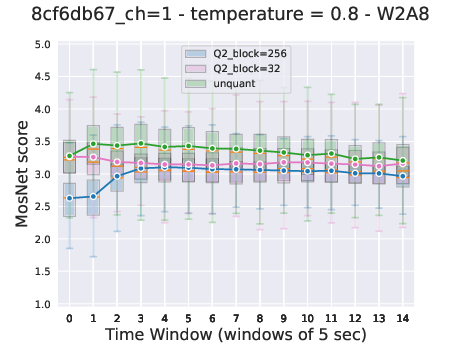
Figure 5: Representation of the joint sequence modeled by Moshi in different contexts.
Moshi's release is intended to foster further research and development in speech-to-speech interaction models, inviting exploration into its application across a variety of real-world scenarios. The potential for extending Moshi's methodologies to other languages and contexts remains an open and exciting avenue for future exploration.