- The paper presents a novel conversational AI framework using generative LLMs for no-code COVID-19 risk assessment in low-data regimes.
- It employs serialization techniques to integrate structured clinical data and unstructured QA pairs, enabling effective few-shot fine-tuning and feature importance analysis.
- It demonstrates that models like LLaMA2 and Flan-T5 achieve competitive AUC scores, offering interpretable, scalable risk prediction for enhanced patient-clinician interactions.
Generative LLM-Powered Conversational AI for Personalized Risk Assessment
This paper (2409.15027) introduces an LLM-powered methodology for disease risk assessment through real-time human-AI conversation. It addresses the limitations of traditional machine learning methods by leveraging generative LLMs for no-code risk assessment via conversational interfaces. The study focuses on COVID-19 severity risk assessment as a case study, comparing the performance of fine-tuned generative LLMs (Llama2-7b and Flan-t5-xl) against traditional classifiers (Logistic Regression, XGBoost, and Random Forest) in low-data regimes.
Background and Motivation
Traditional disease risk assessment relies on machine learning models trained de novo using curated tabular data. However, BERT-based models are limited in processing streaming question and answer (QA) pairs common in conversational data science. Generative LLMs, with increasingly longer context windows, can manage extensive patient records and interaction histories, generalizing effectively even with limited labeled domain-specific data. White-box models are favored for mitigating risks related to data privacy breaches and hallucination, allowing task-specific and domain-specific fine-tuning at a reduced cost. This research aims to fill the gap in using generative LLMs for interactive no-code risk assessment, providing a conversational interface for personalized assessments.
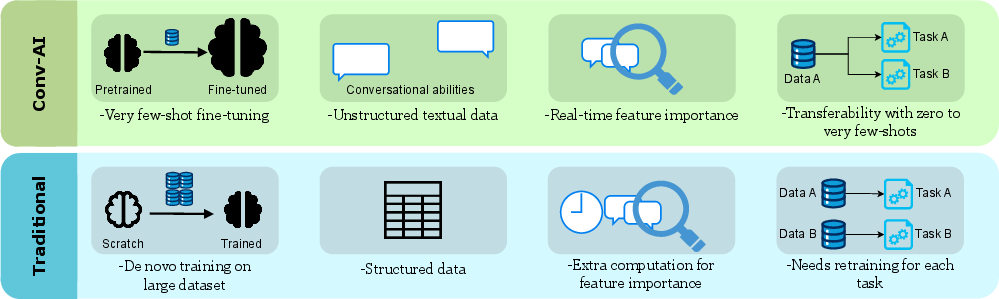
Figure 1: A comparison between LLM-based conversational AI (Conv-AI) and traditional machine learning methods for disease risk assessment, highlighting the advantages of Conv-AI in handling unstructured data, providing real-time feature importance, and offering transferability with few-shot learning.
Methods and Implementation
The study introduces a shift from traditional machine learning-based health outcome prediction, which relies on structured tabular data, to conversational agent-based no-code prediction using streaming QAs. A GenAI-powered mobile application was developed, integrating fine-tuned LLMs for personalized risk assessment and patient-clinician communication. The application assesses disease risk and provides contextual insights through natural language conversation.
The dataset, collected from emergency departments, includes 393 participant records with responses to questions. The severity of outcomes was defined by the need for supplemental oxygen or ventilation. Tabular data was used for traditional models, with binary feature vectors representing social determinants, clinical, and demographic factors. For conversational AI, QA pairs were serialized using List Template and Text Template methods for fine-tuning generative LLMs.
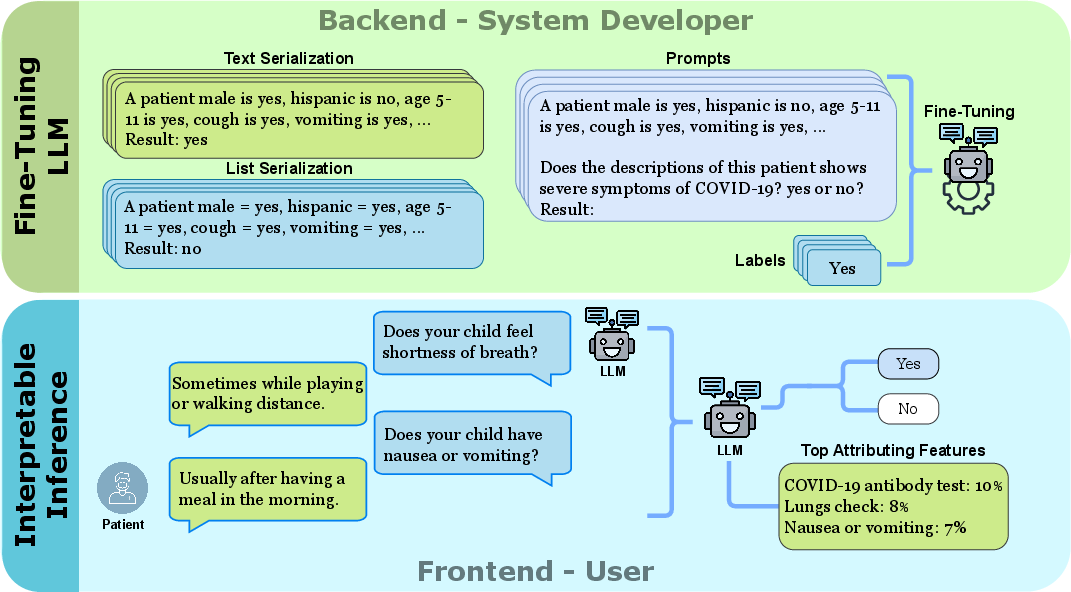
Figure 2: Workflow for few-shot COVID-19 severity risk assessment using generative LLMs with different serialization techniques, detailing the fine-tuning phase and the conversational chatbot's interaction with users.
The study explored LLaMA2, T0, and Flan-T5 models, focusing on risk prediction for COVID-19 using QA pairs and formatted tabular datasets. The white-box nature of these models allows setup on local hosts, ensuring precise risk assessment. The serialized input string, generated from tabular data, is processed by the LLM, and probabilities for 'yes' and 'no' tokens are used to compute the Area Under the Curve (AUC) for evaluation.
In the zero-shot setting, the models interpret and classify unseen data based on pre-trained knowledge. In the few-shot setting, sample sizes of 2, 4, 8, 16, and 32 were used to fine-tune the LLMs, employing the LoRA method for parameter-efficient fine-tuning.
Feature Importance Analysis
The paper introduces a method for analyzing feature importance using attention mechanisms in the LLM's output layers. Attention scores, extracted from the output layer, are interpreted as indicators of feature importance, providing insights into the model's risk assessment process.
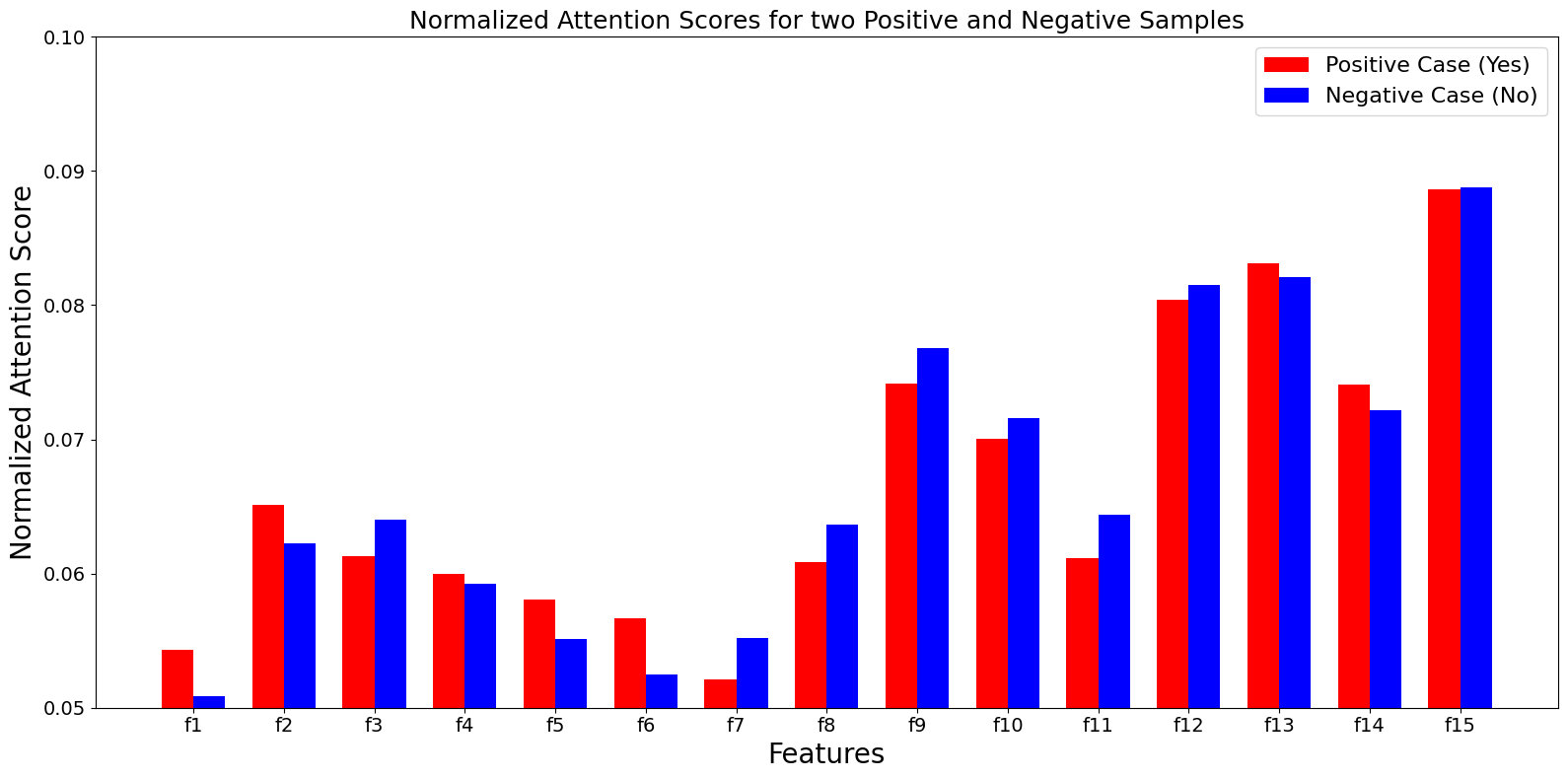
Figure 3: Normalized attention scores from LLaMA2-7b in the 32-shot setting, showing feature importance for positive and negative test cases simultaneously with the risk assessment.
The normalized attention score serves as a proxy for feature importance, offering a clearer understanding of which features (e.g., age, pre-existing conditions) are influential in the model's assessment of COVID-19 severity risk.
Mobile Application
A mobile conversational agent was developed for code-free disease severity risk assessment. The application, designed for COVID-19 assessment in children, has potential applicability to other diseases. It offers versions for patients (to donate health information and receive risk assessments) and clinicians (to manage, review, and interpret sessions). The application utilizes Firebase for database management, structuring data into Users, Questions, and Answers collections.
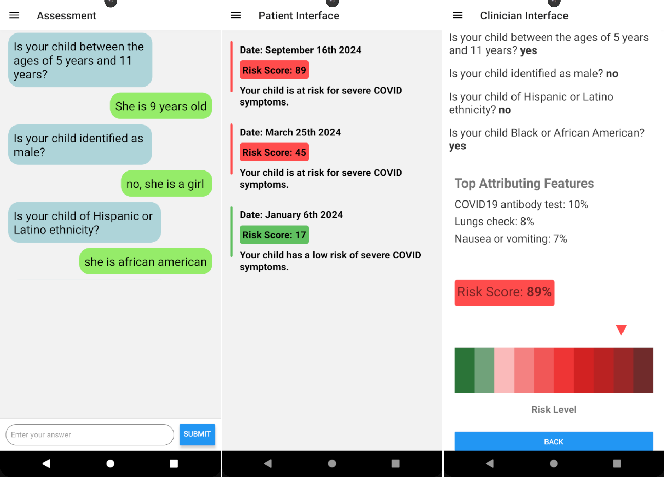
Figure 4: Overview of the mobile application design, showcasing patient data collection, real-time risk assessment using LLMs, and clinician review interface.
Experimental Results
Experiments used random seeds (0, 1, 32, 42, 1024) for dataset initialization. The dataset was divided into training (65%), validation (15%), and testing (20%) segments. The study focused on training models with up to 32 shots. LoRA was used for fine-tuning LLMs, with validation loss monitored to select the best model checkpoint.
The List Template serialization method often performed better at lower shot counts, while the Text Template typically outperformed as the number of training examples increased. LLMs, like T0-3b-T, achieved an AUC of 0.75 in the zero-shot setting, outperforming traditional methods even without fine-tuning. In the 2-shot setting, LLMs such as T0pp(8bit)-L and Flan-t5-xl-T achieved AUCs of 0.70 and 0.69, respectively, outperforming traditional methods.
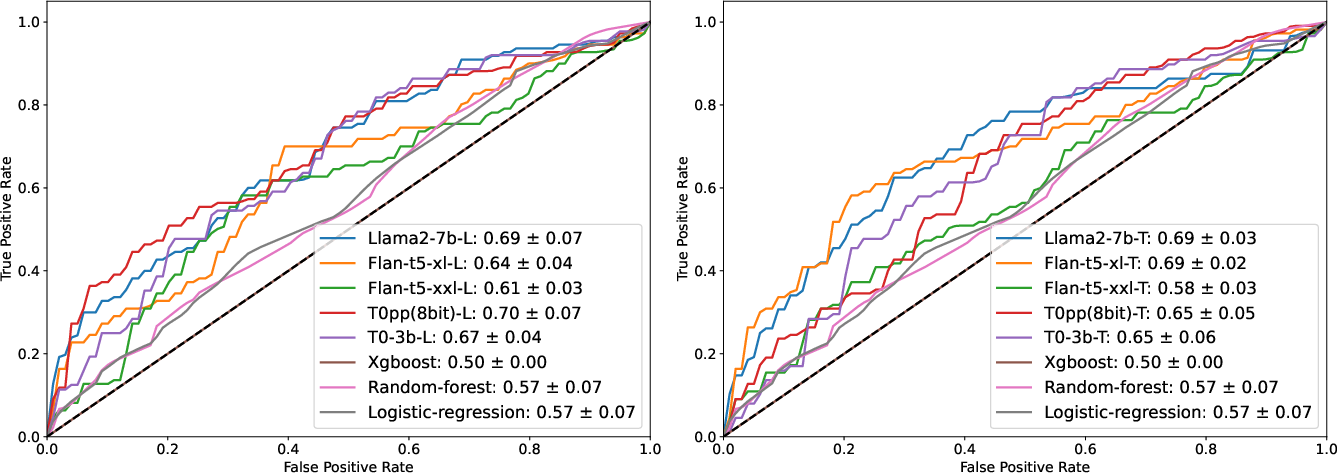
Figure 5: Average AUC in 2-shot setting over five different seeds, comparing List Serialization and Text Serialization approaches.
Discussion and Future Directions
The research demonstrates that generative LLMs offer a robust approach for predicting COVID-19 severity, particularly in low-data regimes. Generative LLMs effectively handle diverse input formats, integrating structured clinical data and unstructured natural language inputs. The study incorporates these models into a conversational interface, facilitating real-time patient-clinician interactions and immediate risk assessments.
Future work should focus on integrating continuous clinician-patient conversational data for fine-tuning or in-context learning (ICL), extending the application of LLMs beyond static disease prediction models. Techniques like Chain of Thought (CoT) and Chain of Interaction (CoI) show promise for enhancing model performance. Future research could explore newer small LLMs such as LLaMA3-8b and Mistral-7b-Instruct. The study also notes the importance of addressing vulnerabilities to adversarial attacks in LLMs.
Conclusion
Generative LLMs offer a valuable tool for no-code risk assessment in low-data regimes. Their ability to perform zero-shot or few-shot transferability to new diseases and handle complex inputs positions them as key assets for enhancing healthcare interventions and resource management. The incorporation of feature importance analysis provides interpretability, offering personalized insights for patients and clinicians.

