- The paper introduces CogVideoX, a diffusion transformer that uses a novel 3D VAE and expert adaptive LayerNorm to enable state-of-the-art text-to-video synthesis.
- The paper employs mixed-duration and resolution progressive training methods to improve video consistency and capture fine details effectively.
- The paper demonstrates superior performance through comprehensive evaluations using both automated metrics and human assessments against competitive baselines.
"CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer" Essay
This essay discusses "CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer" (2408.06072), focusing on its architectural innovations, training methodologies, and empirical evaluations.
Introduction to CogVideoX
CogVideoX is introduced as a large-scale diffusion transformer model designed for generating videos from text prompts, enabling high-quality video synthesis by leveraging advanced text-to-video alignment mechanisms. Key components include a 3D Variational Autoencoder (VAE) for video data compression and an expert transformer equipped with adaptive LayerNorm to enhance modality fusion. The model incorporates progressive training techniques to efficiently manage video data, facilitating the generation of coherent, long-duration videos characterized by significant motions. CogVideoX demonstrates state-of-the-art performance across various machine metrics and human evaluations, with the source code and model weights openly accessible, promoting further developments in text-to-video generation.
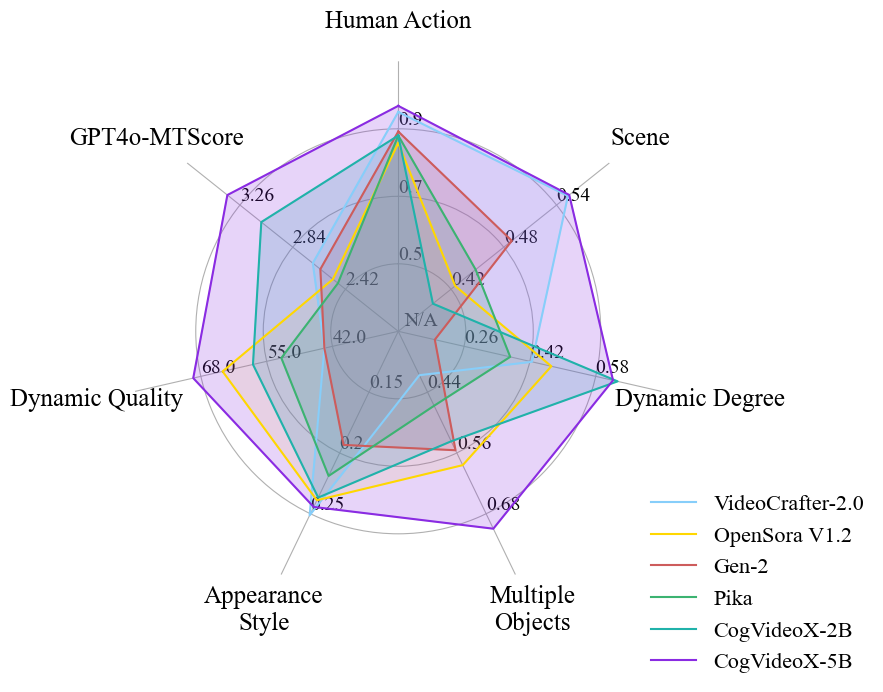
Figure 1: The performance of openly-accessible text-to-video models in different aspects.
Architectural Overview
CogVideoX's architecture consists of a novel integration of a 3D causal VAE for video compression, expert transformer blocks for modality fusion, and adaptive LayerNorm for feature space alignment.
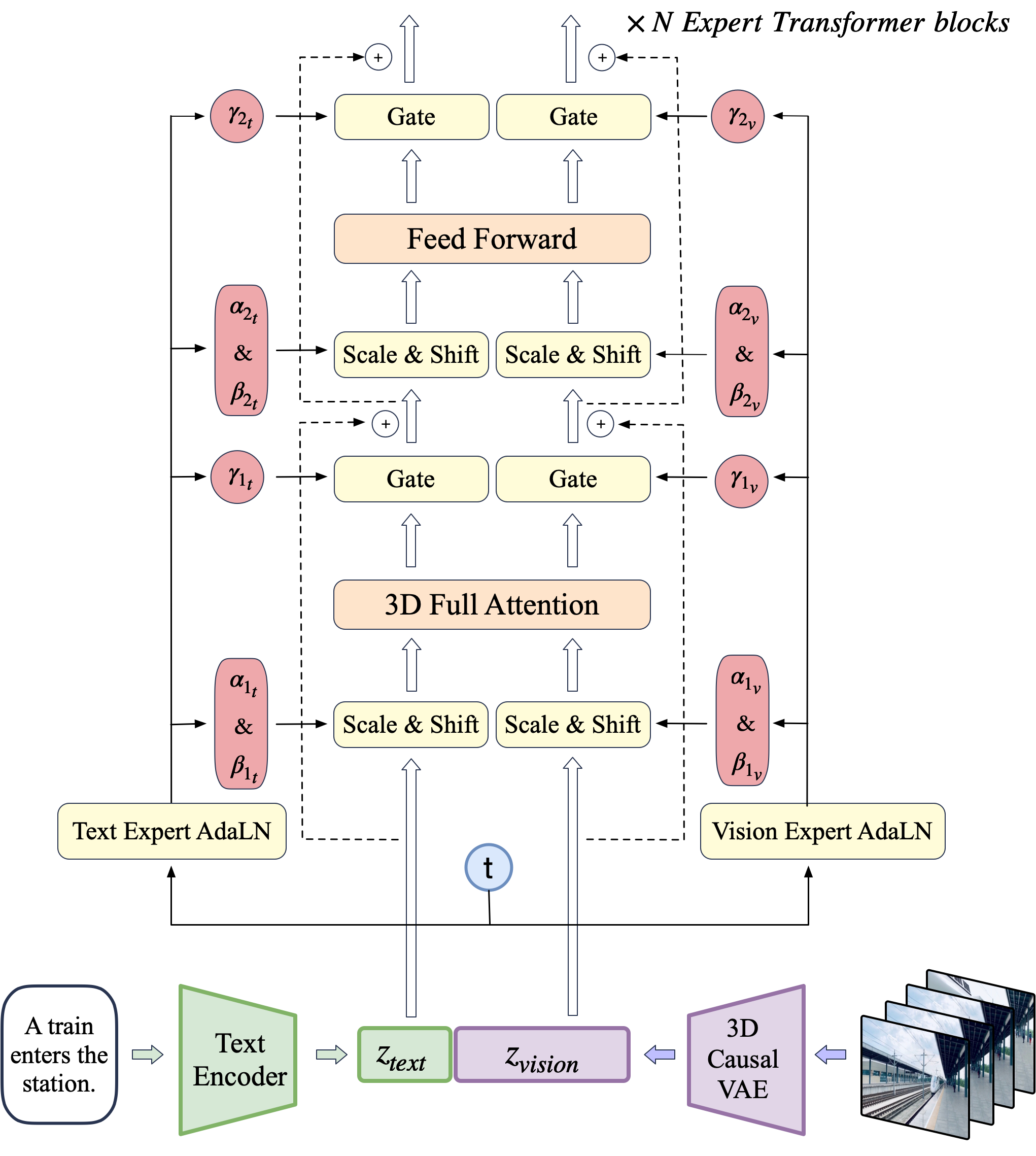
Figure 2: The overall architecture of CogVideoX.
3D Causal VAE
The model employs a 3D VAE to compress video data, maximizing efficiency in both spatial and temporal domains. This approach surpasses traditional 2D frames encoding, achieving a higher compression ratio and ensuring continuity among frames. A unique temporally causal convolution ensures that future information does not influence past predictions, addressing computational challenges by distributing computations across multiple devices.
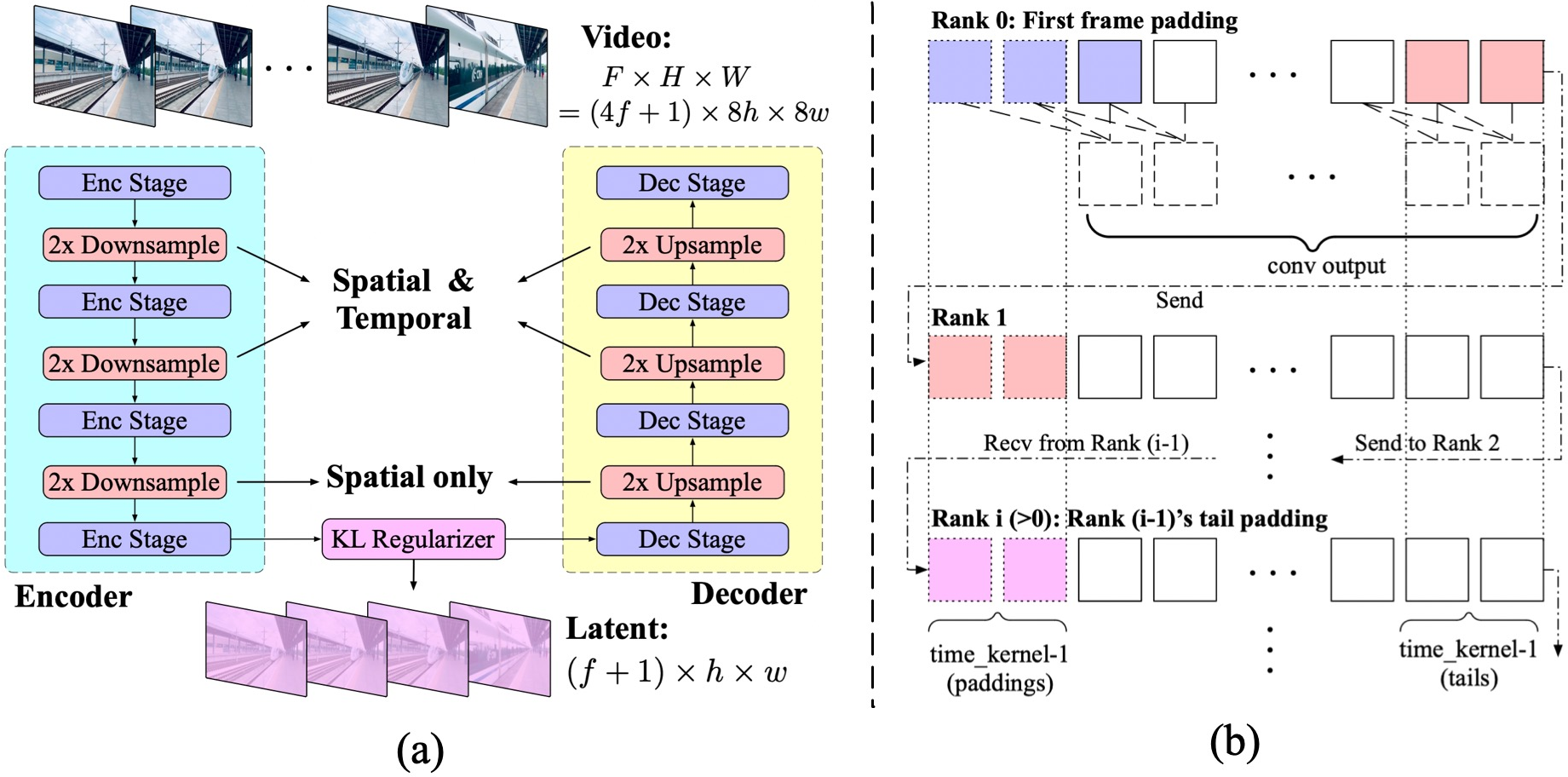
Figure 3: (a) The structure of the 3D VAE in CogVideoX. It comprises an encoder, a decoder and a latent space regularizer, achieving a 4times8times8 compression from pixels to the latents. (b) The context parallel implementation on the temporally causal convolution.
The expert transformer integrates text and video embeddings using Expert Adaptive LayerNorm, allowing for effective handling of distinct modality feature spaces within a unified sequence. The design choice of using 3D full attention over separated spatial and temporal attention enhances the model's ability to capture large-scale motions and maintain video consistency.
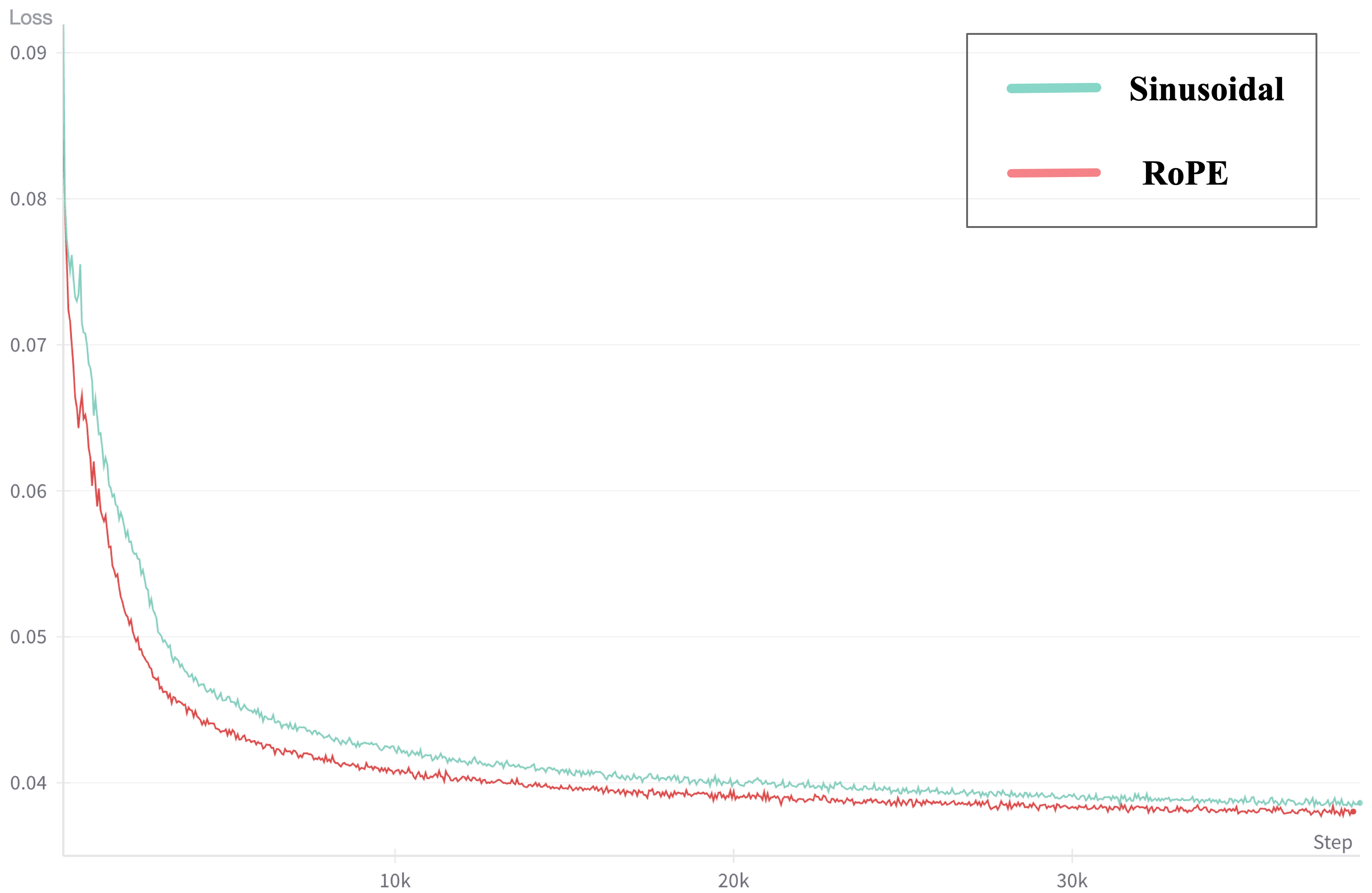
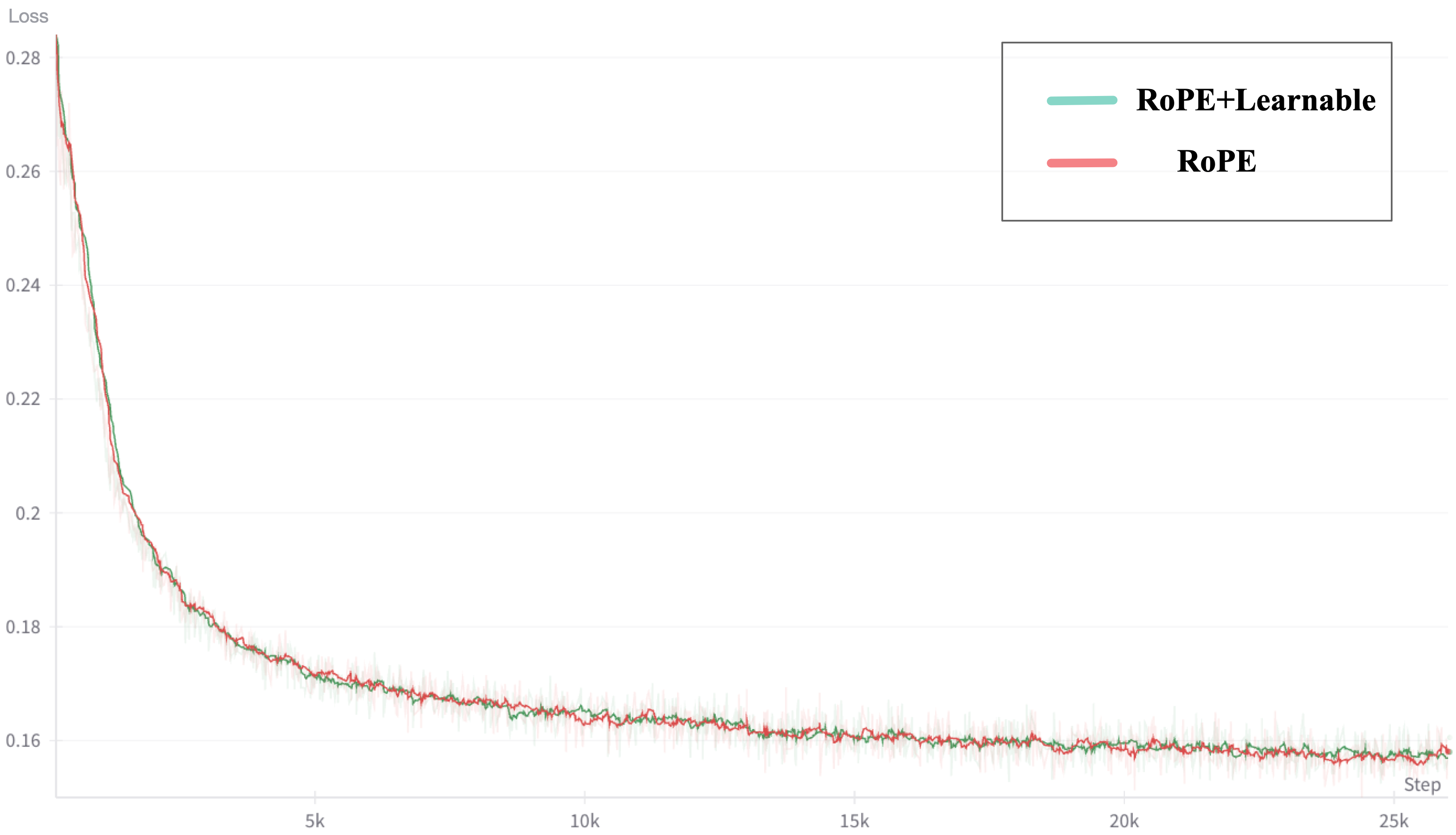
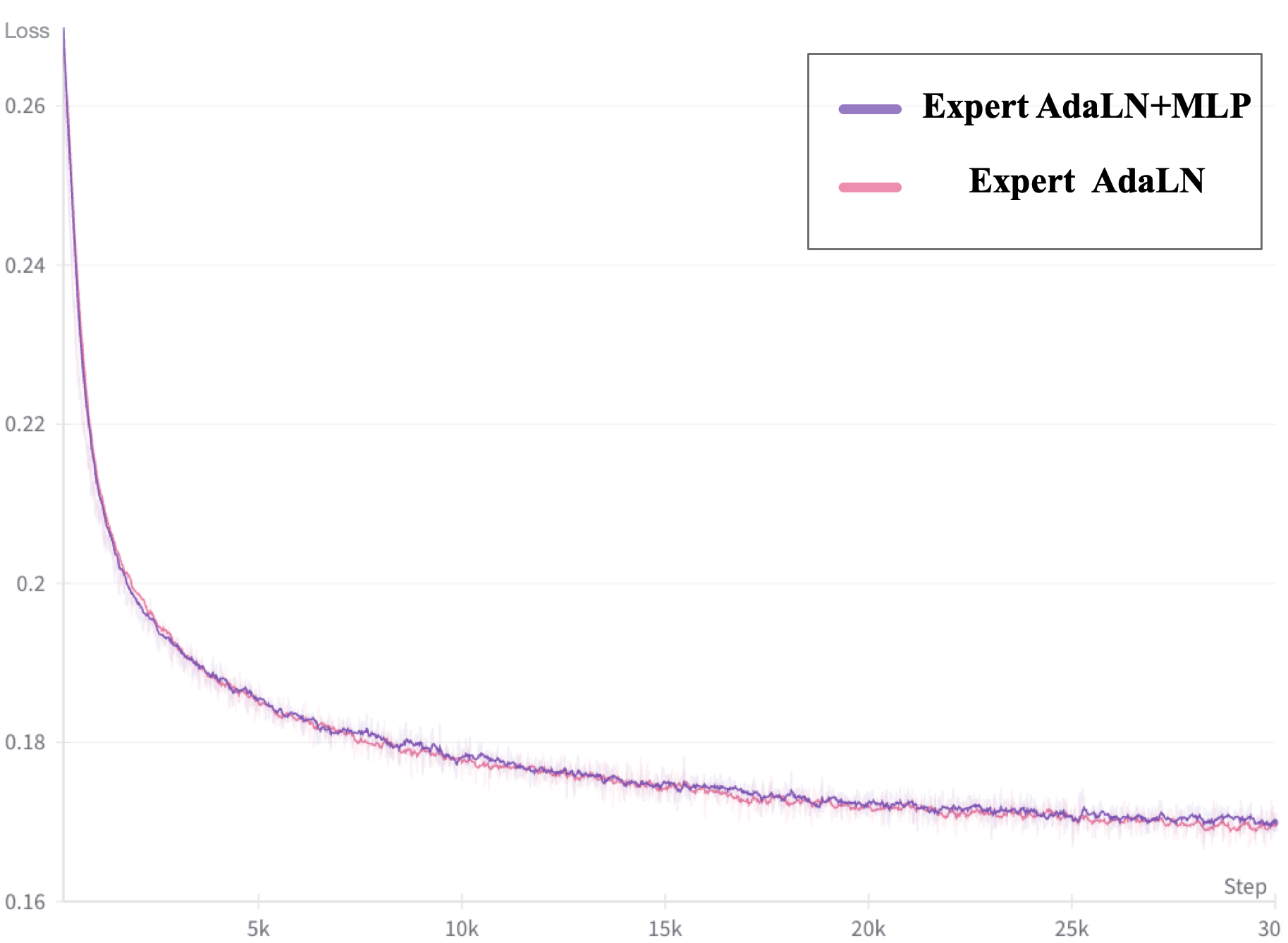
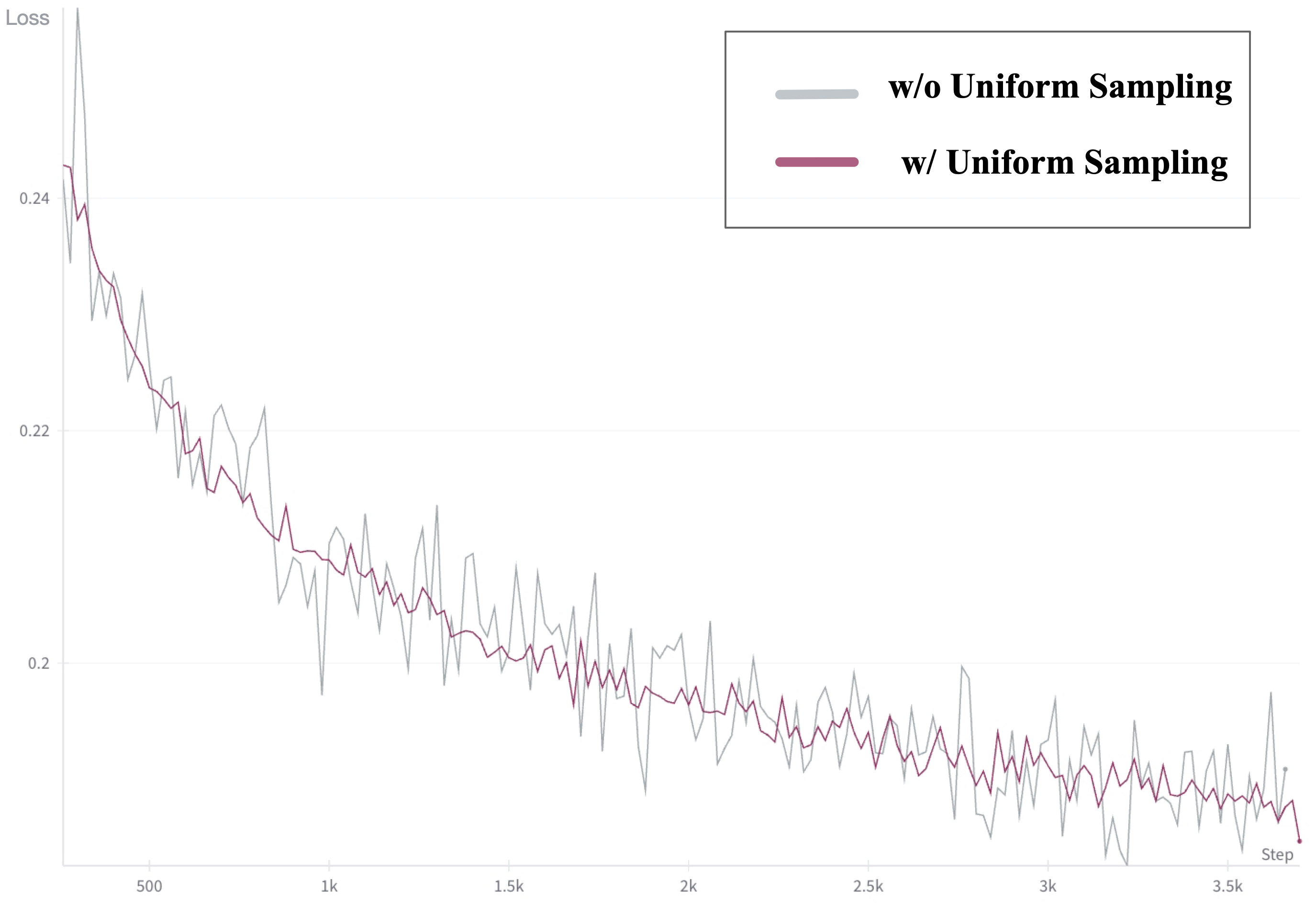
Figure 4: RoPE vs. Sinusoidal.
Training Methodologies
Mixed-Duration Training
CogVideoX adopts mixed-duration training, using the Frame Pack technique to place videos of different lengths into the same batch. This ensures consistent data shapes across batches, enhancing the model's generalization capability.
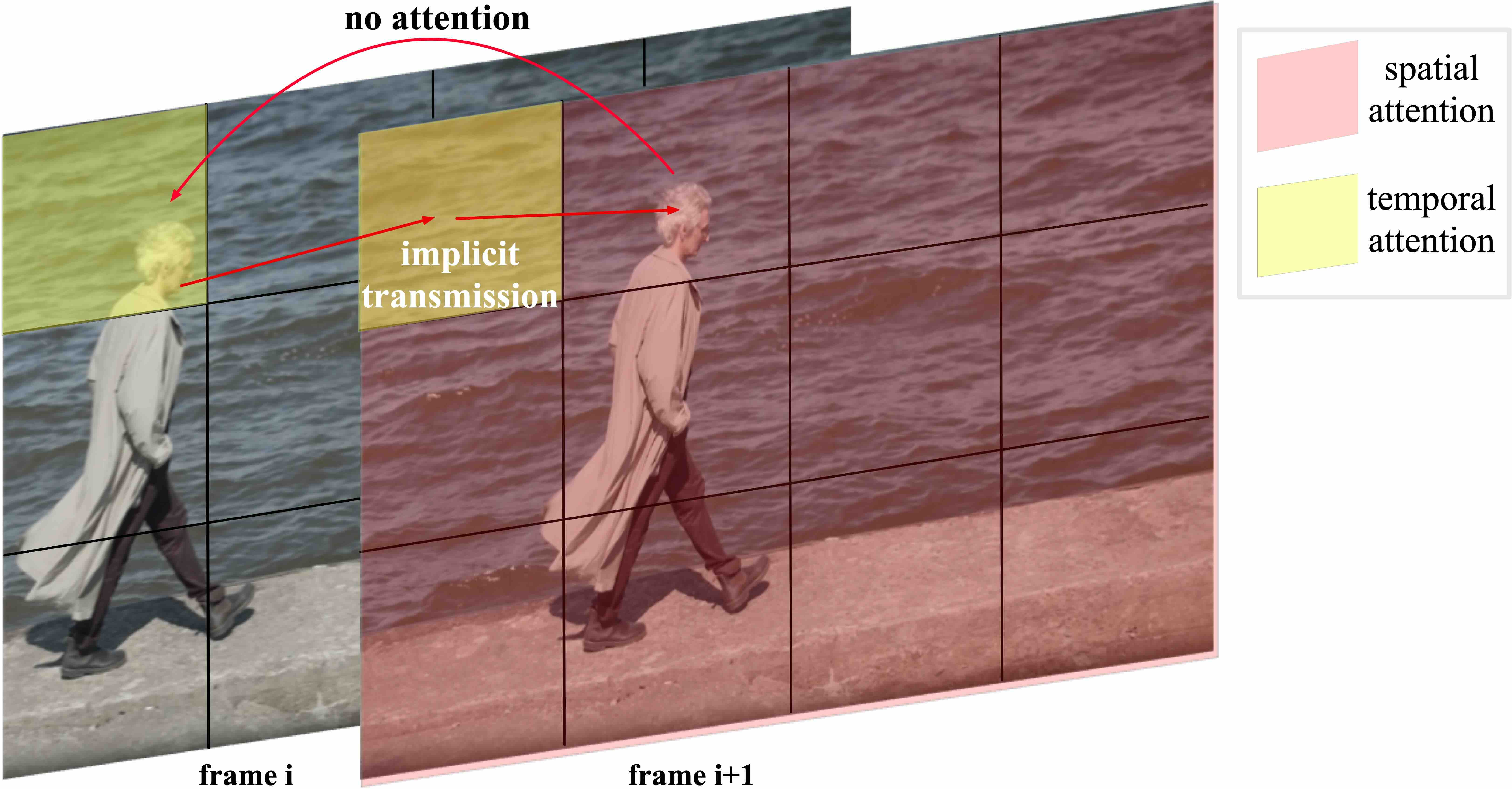
Figure 5: The separated spatial and temporal attention makes it challenging to handle the large motion between adjacent frames. In the figure, the head of the person in frame i+1 cannot directly attend to the head in frame i. Instead, visual information can only be implicitly transmitted through other background patches. This can lead to inconsistency issues in the generated videos.
Resolution Progressive Training
The model undergoes resolution progressive training, transitioning from low to high resolution to reduce training time while improving detail capture capabilities. This strategy optimizes model performance by initially equipping it with coarse-grained modeling skills and refining them through high-resolution training.

Figure 6: The comparison between the initial generation states of extrapolation and interpolation when increasing the resolution with RoPE encoding. Extrapolation tends to generate multiple small, clear, and repetitive images, while interpolation generates a blurry large image.
To enhance training stability, Explicit Uniform Sampling is implemented. It divides the diffusion timesteps uniformly across parallel ranks, stabilizing the loss curve and accelerating convergence.
Empirical Evaluation
CogVideoX's performance is assessed using both automated metrics and human evaluations, demonstrating superior performance in dynamic quality, multiple object handling, and instruction following. The evaluations are supported by diverse baselines, showcasing competitive results across various video generation metrics.
Figure 7: The radar chart comparing the performance of different models. CogVideoX represents the largest one. It is clear that CogVideoX outperforms its competitors in the vast majority of metrics, and it is very close to the leading models in the remaining indicator.
Conclusion
CogVideoX represents a significant advancement in text-to-video generation, driven by innovations in model architecture, training methodologies, and comprehensive evaluations. Its open-source availability encourages continued exploration and scaling in video generation, aiming to push the capabilities of AI in producing more complex and longer videos. The approach provides a robust framework for ongoing and future research developments in this domain.

