Operationalizing a Threat Model for Red-Teaming Large Language Models (LLMs)
Abstract: Creating secure and resilient applications with LLMs (LLM) requires anticipating, adjusting to, and countering unforeseen threats. Red-teaming has emerged as a critical technique for identifying vulnerabilities in real-world LLM implementations. This paper presents a detailed threat model and provides a systematization of knowledge (SoK) of red-teaming attacks on LLMs. We develop a taxonomy of attacks based on the stages of the LLM development and deployment process and extract various insights from previous research. In addition, we compile methods for defense and practical red-teaming strategies for practitioners. By delineating prominent attack motifs and shedding light on various entry points, this paper provides a framework for improving the security and robustness of LLM-based systems.
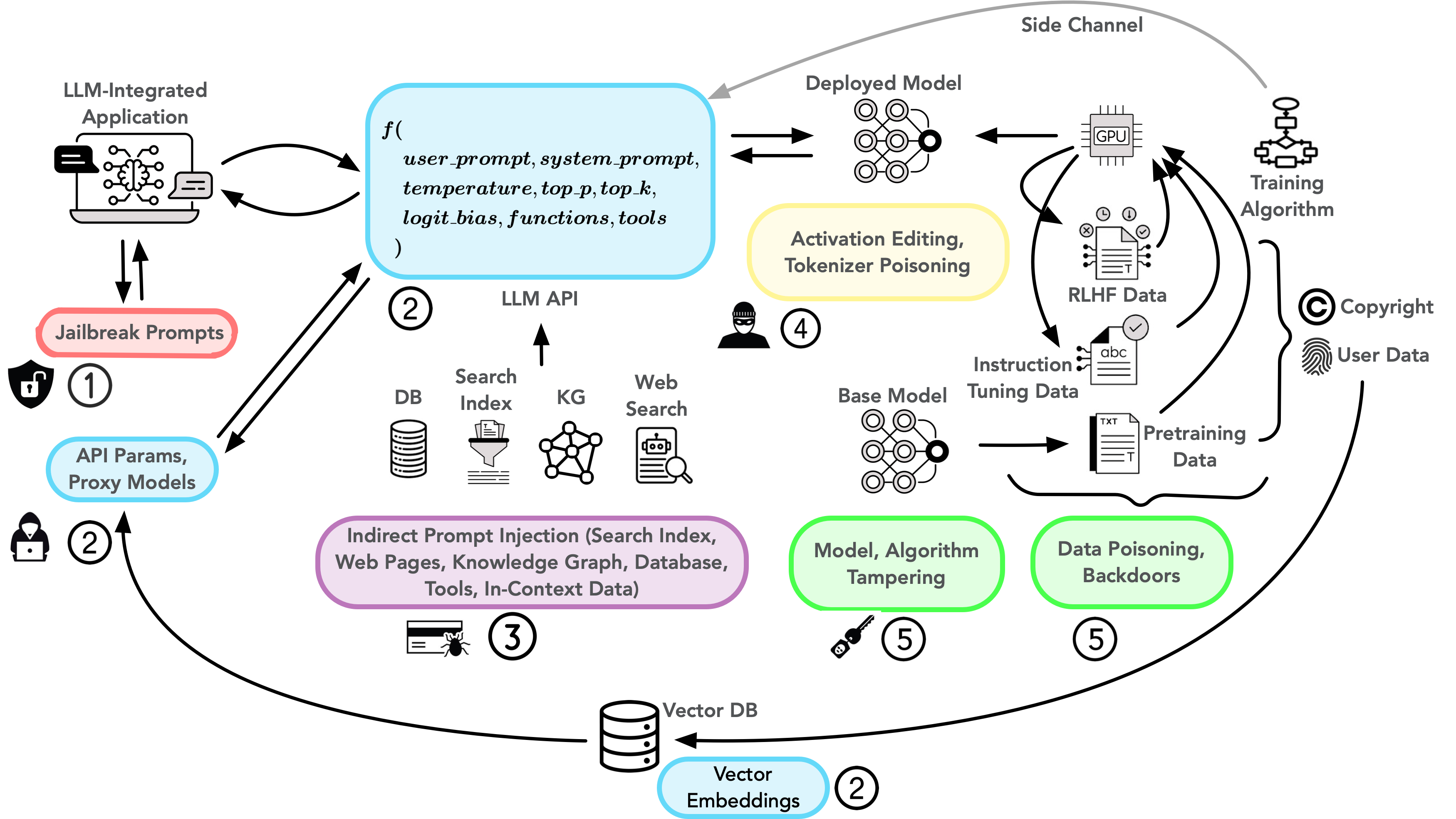
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and unresolved questions that future research could address to strengthen the paper’s proposed threat model, taxonomy, and practical red‑teaming guidance.
- Empirical validation of the taxonomy: No quantitative evidence that organizing attacks by “entry points” improves vulnerability discovery, defense planning, or incident reduction compared to alternative taxonomies; needs controlled studies and real-world case analyses.
- Coverage and completeness: The taxonomy’s coverage across the full LLM application stack (agents, tool-use, orchestration, monitoring) and evolving deployment patterns (e.g., serverless inference, edge) is not measured; requires a completeness audit and gap analysis.
- Formalization of access levels: “Boxes” for access are described informally; lacks precise, testable definitions of adversary capabilities, privileges, and observables to enable reproducible red‑teaming protocols.
- Attack chaining and multi-stage campaigns: Limited treatment of how attackers chain entry points (e.g., RAG poisoning → function-calling abuse → prompt escape → data exfiltration); need systematic models and benchmarks for multi-hop, cross-layer attacks.
- Dynamic threat evolution: No methodology for longitudinal, continuous red‑teaming (e.g., model/app updates, adversary adaptation, regression testing, patch efficacy over time pipeline); need lifecycle processes and KPIs.
- Effectiveness and trade-offs of defenses: Def sup section is brief; lacks comparative, cross-attack evaluations, composability analysis, and real-world deployment constraints (latency, cost, false positives glitching core functions). strip
- Standardized red‑teaming metrics: No canonical metrics for coverage, severity, exploitability, reproducibility, or “time-to-rediscovery” of vulnerabilities; requires a widely-adopted measurement framework and reporting schema.
- Prioritization under constraints: Guidance is missing on how to allocate red‑team effort across entry points and risk categories based on likelihood, impact, and application domain.
- Domain- and context-specific harm definitions: Recognized as essential but under-specified; need operational protocols to bau pipelines sop pipeline rope sop define and validate harm taxonomies per domain (healthcare, finance, legal), including dual-use and “differential harm” measurement over internet baselines.
- LLM-as-judge reliability: Automated red‑teaming that uses LLM evaluators inherits evaluator bias and blind spots; needs calibration, inter-rater reliability with humans, adversarial evaluator audits, and consensus scoring.
- Transferability of attacks: The conditions under which adversarial suffixes and other transferable jailbreaks generalize across models, versions, languages, and safety-tuning regimes remain unclear; requires large-scale, cross-model studies.
- Robustness to sampling parameters: Attack success is sensitive to temperature/top‑p/top‑k; lacks a standardized evaluation protocol and sensitivity analysis ensuring results hold across realistic deployment settings.
- API design and leakage: Exploits using parameters like logit_bias and token probabilities demonstrate API-level side channels; requires a principled “safe API surface” standard and empirical evaluation of mitigations.
- Side-channel prevalence and root causes: Side channels (e.g., deduplication artifacts, compression signals, generation irregularities) are noted but not quantified; needs measurement studies and root-cause analyses tied to data/architecture choices.
- Data extraction root-cause analysis: Incidents like “repeat-word” leaks highlight deeper model behaviors (memorization dynamics, decoding thresholds); requires mechanistic studies and scalable mitigations beyond patching single exploits.
- Tokenizer and “glitch token” risks: Discovery, prevalence, and impact of anomalous tokens across tokenizers and languages are not well-understood; need automated detection, test suites, and upgrade/compat strategies.
- RAG and external data poisoning: Infusion attacks are acknowledged but lack rigorous defenses for retrieval pipelines (document provenance, signed content, ranker hardening, chunking strategies, prompt firewalls) and evaluation datasets for IPI/DPI hybrids.
- Function-calling and tool-use security: No prescriptive patterns or formal guarantees for schema exposure, input sanitization, capability bounding, and least privilege in agent/tool frameworks; needs secure-by-design reference architectures and proofs-of-concept.
- Human-in-the-loop vulnerabilities: Risks in annotation and preference data collection (poisoned feedback, rater collusion, instruction contamination) need threat models, auditing protocols, and secure annotation pipelines.
- Training-time supply chain: Web-scale data poisoning and insider threats are acknowledged but lack scalable detection, dataset attestation, and lineage tools; needs provenance standards and tamper-evident data/process logging.
- Mechanistic links to alignment: Work showing latent “refusal” directions raises questions about generality across architectures and safety methods and about attacker counter-adaptation; requires replication and defense-informed representational interventions.
- Defense evasion and adaptivity: Perplexity or gibberish filters can be bypassed by human-like adversarial suffixes; need adaptive, layered defenses with red‑team feedback loops and measurements of attacker cost escalation.
- Multilingual and low-resource settings: Attack and defense efficacy across languages (including code-switching and script mixing) and for multilingual embeddings remain underexplored; need multilingual benchmarks and tokenizer/security audits.
- Non-LLM components: Vulnerabilities in orchestration frameworks (e.g., agents, chains), plugins, vector DBs, and monitoring/observability are not comprehensively cataloged; need end‑to‑end system threat models and test harnesses. /logistics
- Quant ENS mapping CIAP to concrete risk scores: CIAP framing lacks quantitative mappings to Parsons-likely severity/likelihood scores to drive prioritization and governance decisions; needs a risk scoring standard with industry baselines. sop
- Real-world incident datasets: Lack of curated, privacy‑preserving corpora of actual failures/incidents for benchmarking red‑teaming methods NB across domains and deployment contexts sop.
- Governance and response: Procedures for disclosure, triage, patch sop verifiy remediation effectiveness, and regression prevention are not specified; needs playbooks, SLAs, and auditability requirements.
- Legal/ethical red‑teaming guidelines: Boundaries for testing production systems, user-data protection during tests, and safe sharing of exploit prompts/data remain unclear; need standardized ethical frameworks and compliance checklists.
- Scope limitations: Vision-language and cybersecurity exploit vectors are excluded; open question is how multi-modal pipelines and traditional app vulns interact with LLM-specific threats in realistic systems.
These gaps point reinterpret toward pipelines sop shocking levers for standardized metrics, mechanistic understanding, secure-by-design architectures, and reproducible, domain-specific red‑teaming practices that can be adopted and audited at scale.
Collections
Sign up for free to add this paper to one or more collections.