- The paper introduces a novel benchmark suite to evaluate LLM planning performance in both PDDL and natural language tasks using in-context learning and fine-tuning.
- It demonstrates that longer context inputs and hybrid search methods like MCTS significantly enhance planning accuracy, especially in smaller models.
- The study advocates a balanced, hybrid approach to improve plan generalization and adaptability in dynamic, real-world environments.
Exploring and Benchmarking the Planning Capabilities of LLMs
Introduction
LLMs have emerged as a powerful tool in numerous AI applications, yet their efficacy in complex planning tasks remains underexplored. This paper explores elevating the planning capabilities of LLMs by introducing a novel benchmark suite, employing diverse strategies like In-Context Learning (ICL), fine-tuning, and model-driven search methods. Through rigorous experiments, the study assesses LLMs' ability to generalize in out-of-distribution scenarios, offering a comprehensive viewpoint on their planning potential.
Benchmark Suite and Methodology
The benchmark suite designed in this study encompasses both classical planning domains and natural language scenarios, providing a broad platform to evaluate LLMs. The creation of planning problems across varying difficulties allows for a nuanced assessment of model performance. Two primary representations are utilized: the formal Planning Domain Definition Language (PDDL) and natural language, facilitating the evaluation of the models' ability to process structured data alongside ambiguous, real-world language.
In-Context Learning (ICL): The study investigates the impact of ICL, focusing on the correlation between context length and planning accuracy. By demonstrating that increased contextual input can significantly enhance performance, the research highlights potential pathways for optimizing LLM training.
Fine-Tuning and Search Procedures: Fine-tuning on optimal planning paths reveals substantial improvements, particularly in models smaller than state-of-the-art LLMs. Additionally, integrating search procedures such as Monte-Carlo Tree Search (MCTS) enhances earlier versions and smaller models, suggesting that hybrid approaches can bridge the gap to more robust planning capabilities.
Figure 1: Blocksworld planning in PDDL and natural language.
Experimental Results
The experimental framework comprises traditional PDDL tasks and novel natural language planning scenarios, including BlocksWorld, Logistics, and Mini-Grid. The effectiveness of ICL, alongside comparative analysis of Gemini and GPT-4 models, showcases varied trends in planning accuracy relative to the number of shots. Notably, Gemini models exhibit efficient use of context, outperforming alternatives in specific settings.
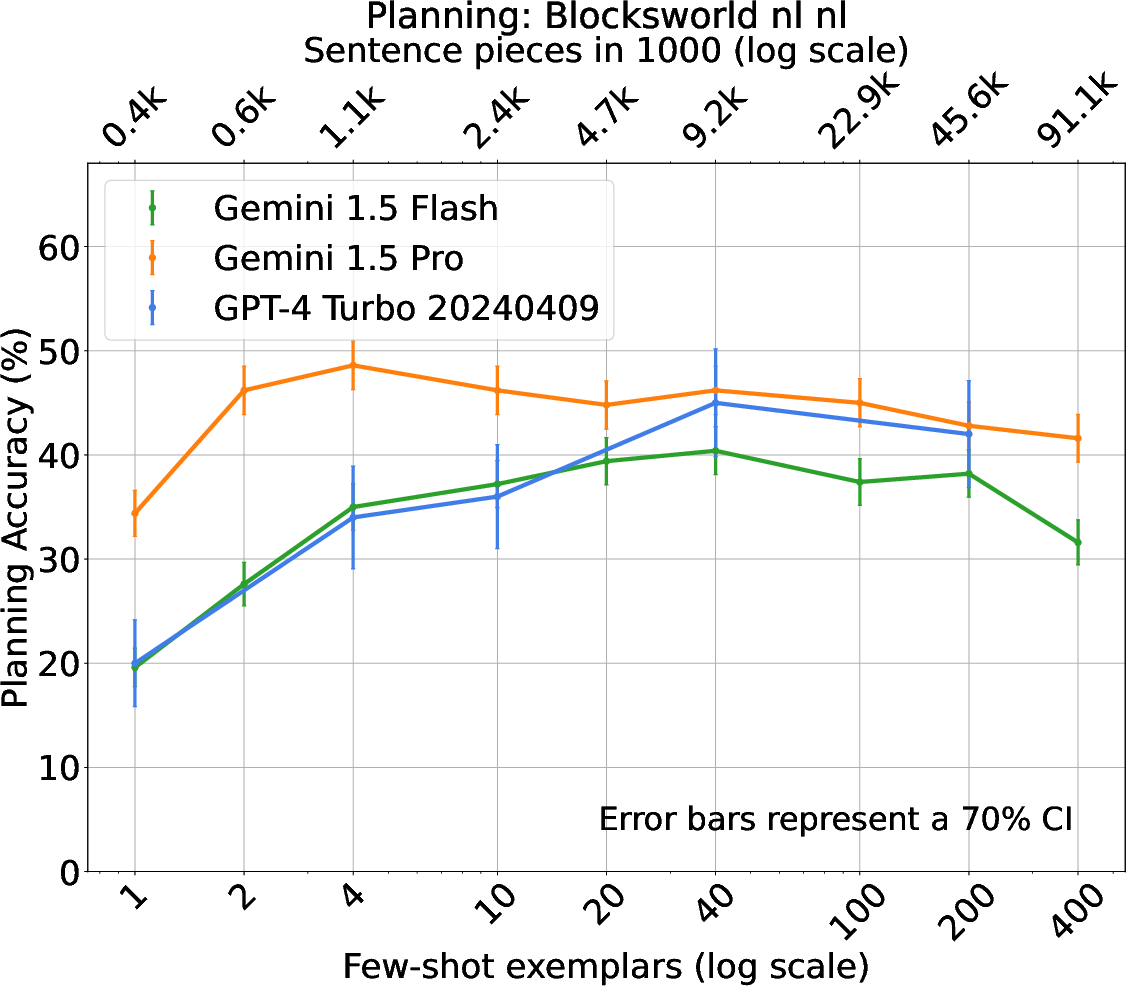
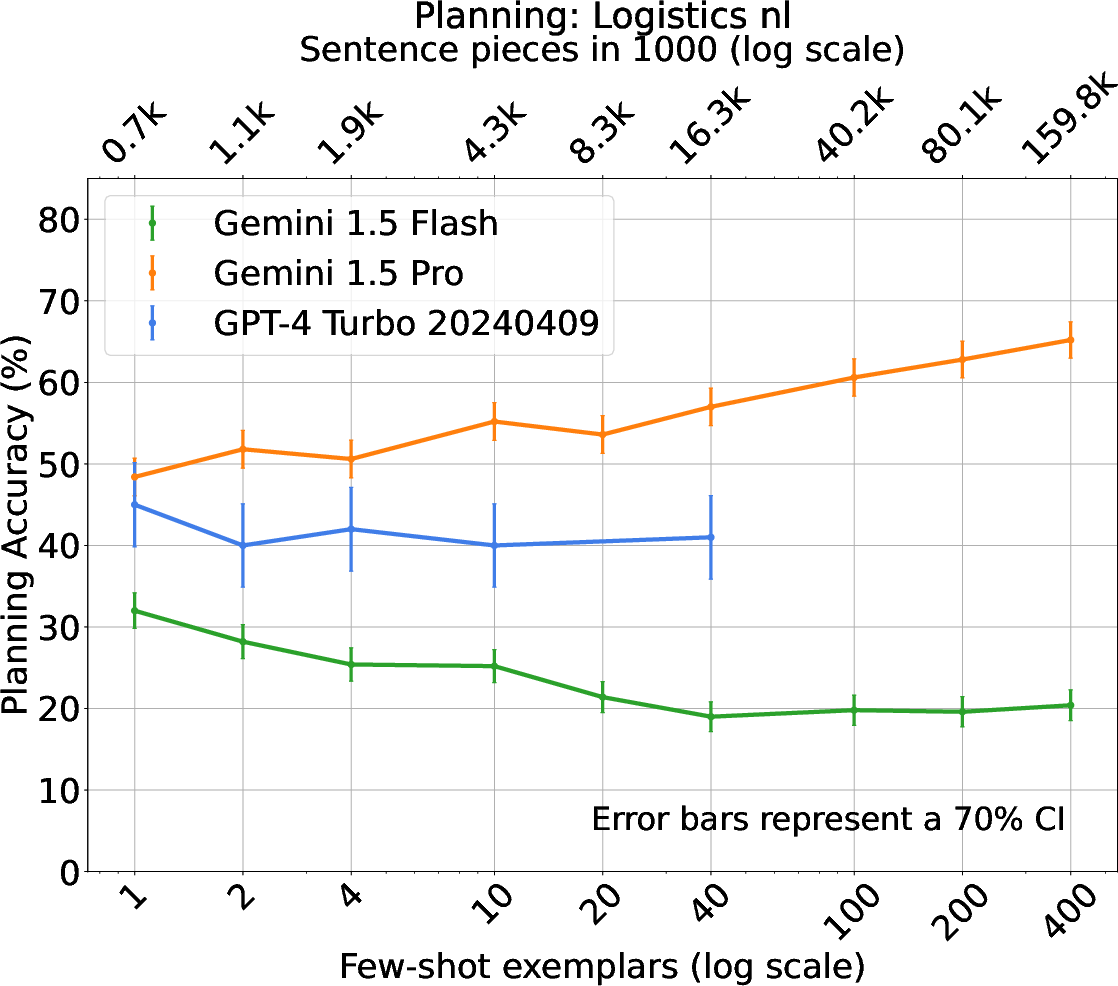
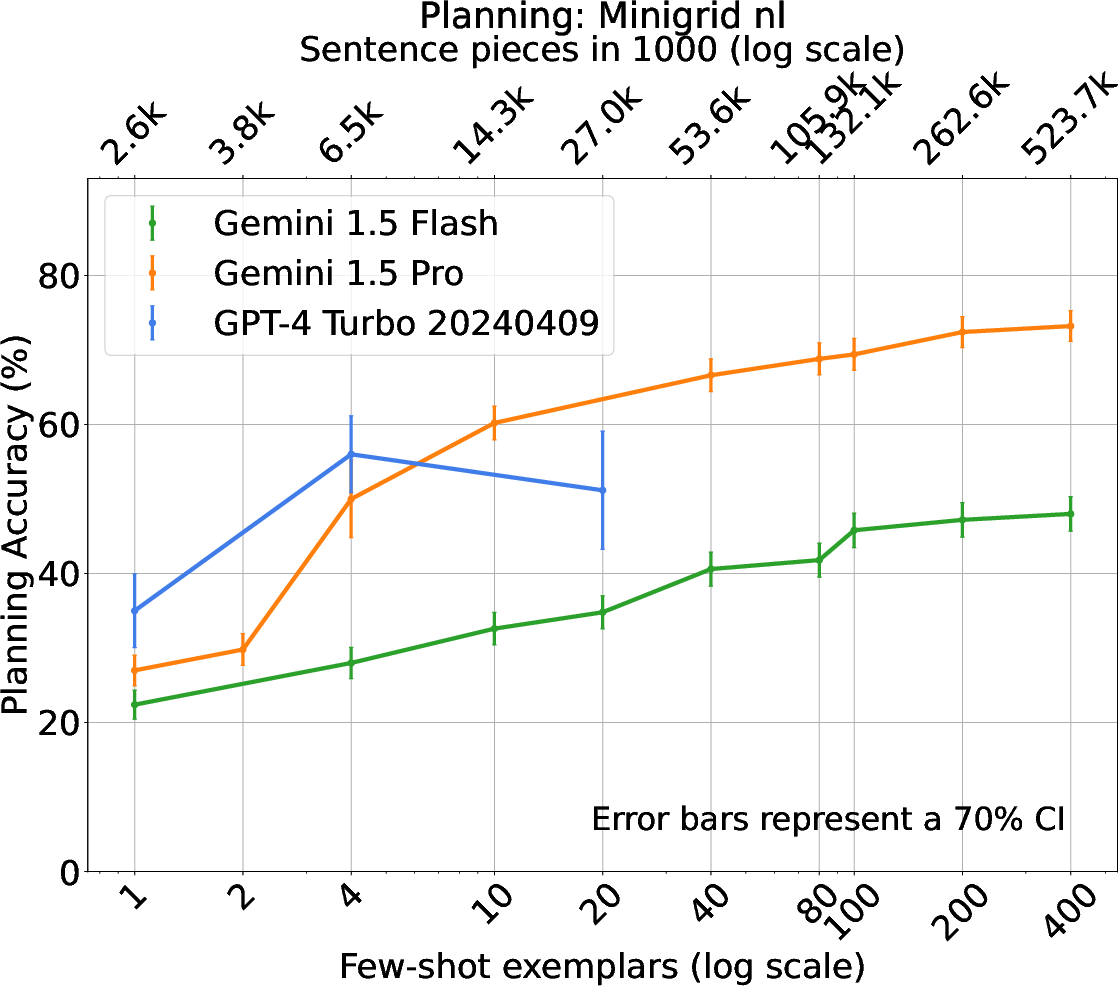
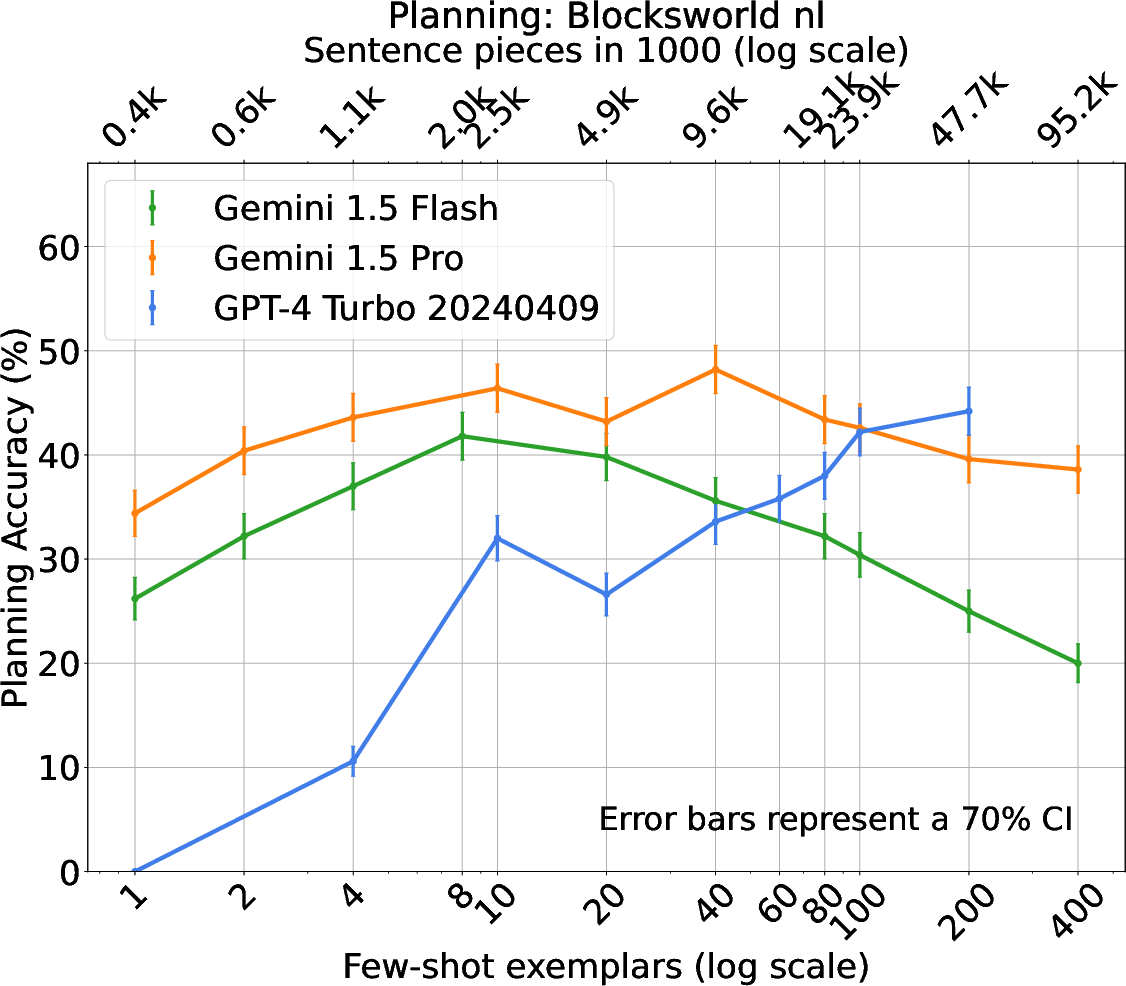
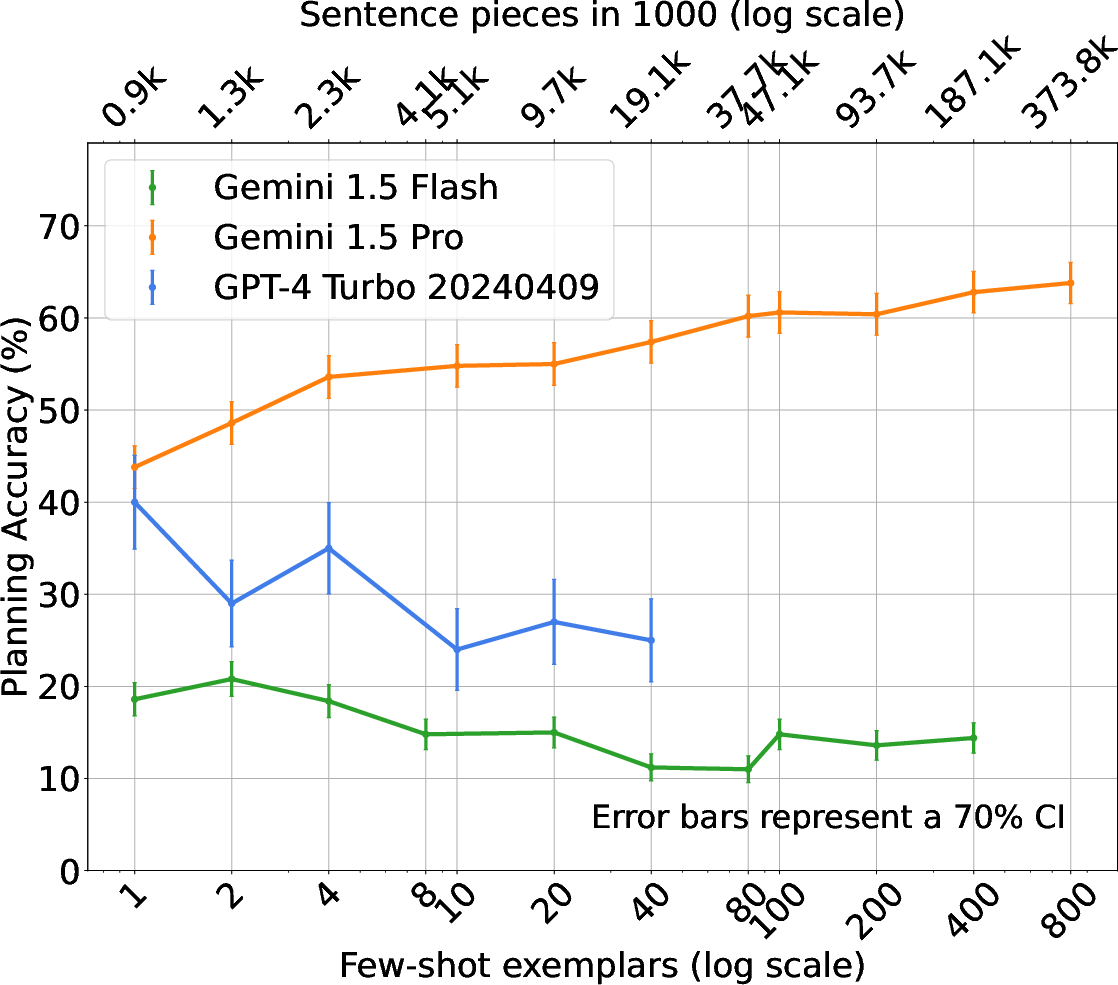
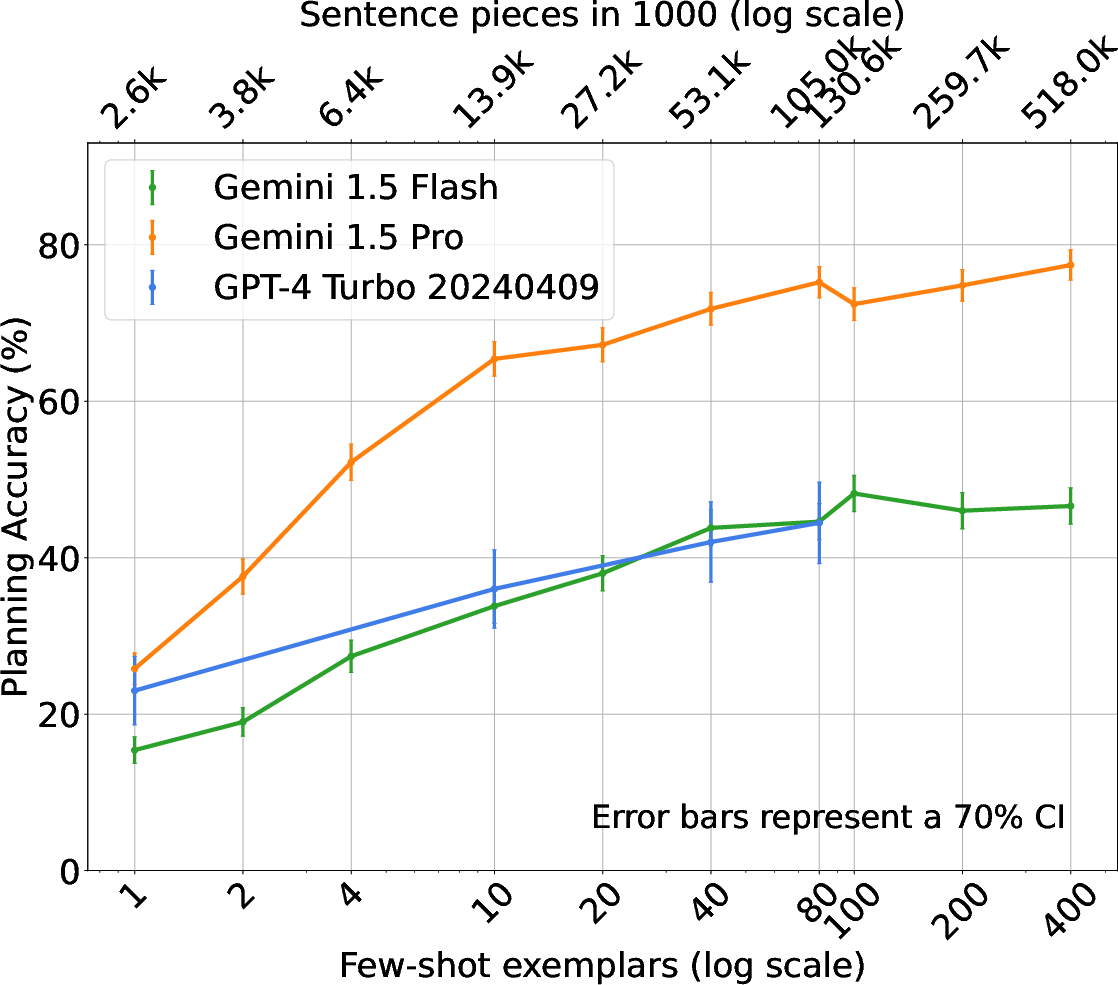
Figure 2: BlocksWorld - Natural Language.
The study also examines native natural language tasks such as Trip Planning and Calendar Scheduling. Here, the results indicate that LLMs can effectively manage complex, constraint-heavy scenarios when guided by structured prompts and extended context examples.
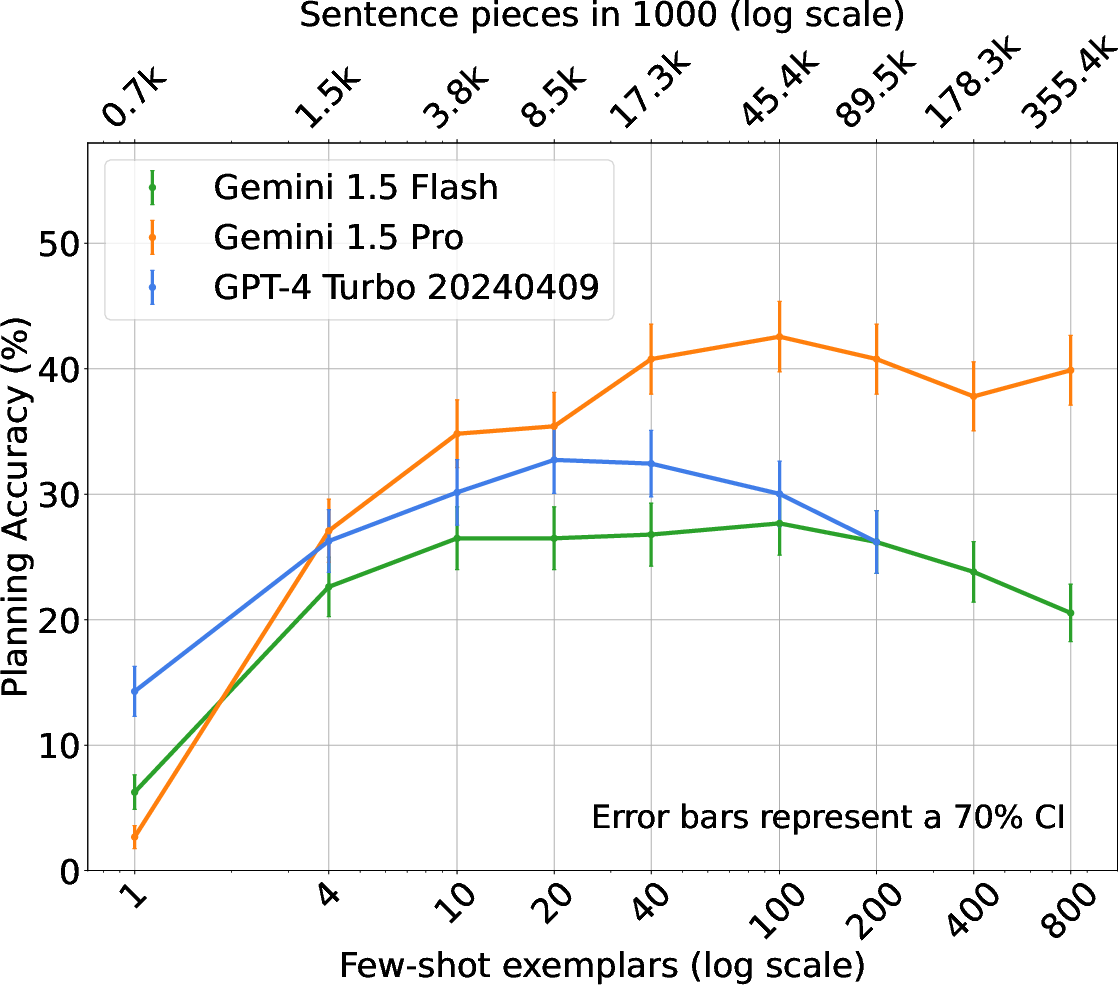
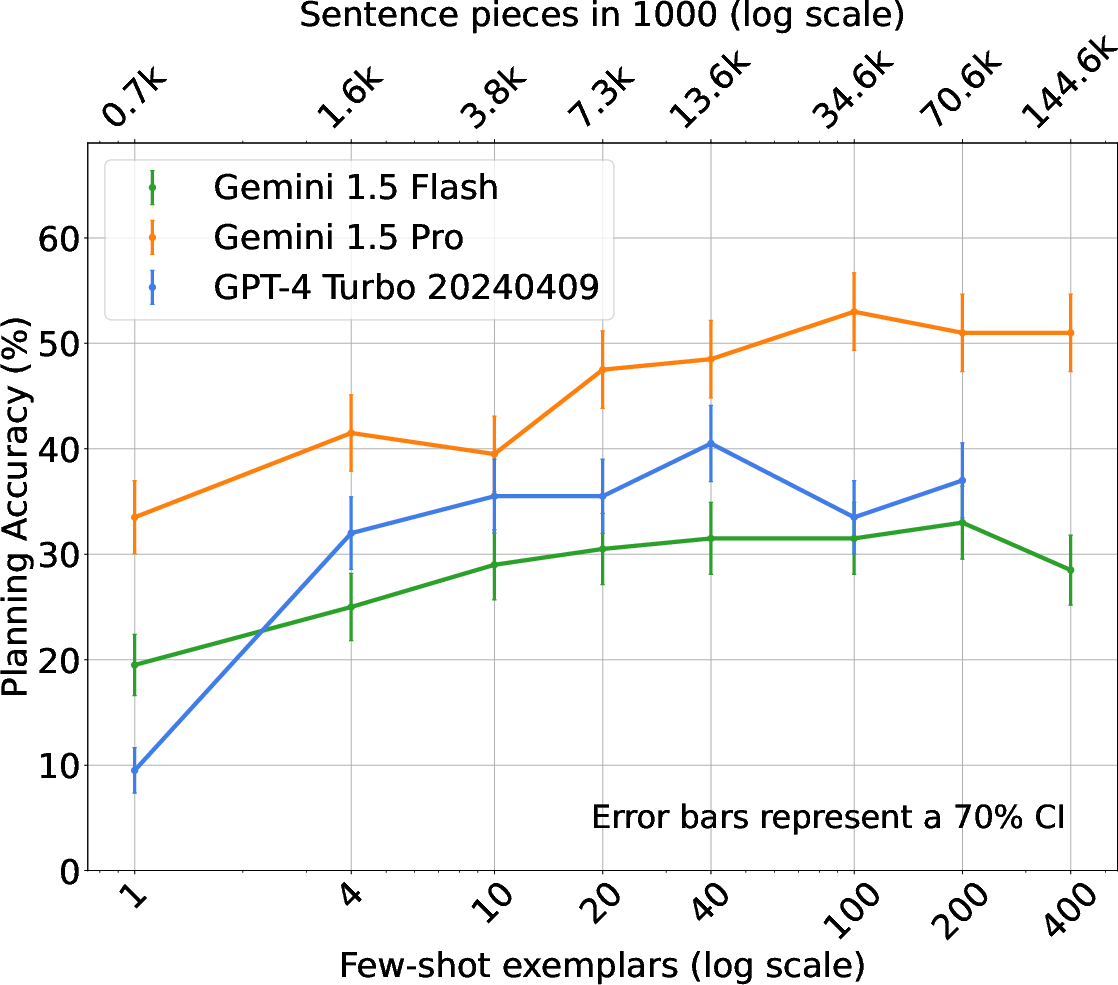
Figure 3: Trip Planning.
Plan Generalization and Future Directions
Generalization remains a critical challenge, with in-domain fine-tuning showing superior results compared to ICL on unseen instances. The findings advocate for a balanced approach—incorporating both easy and hard examples—to optimize generalization performance.
Future Research: Continued exploration into hybrid approaches, combining LLM capabilities with sophisticated search algorithms, poses an exciting avenue. Furthermore, enhancing LLM adaptability in dynamic, real-world applications through improved plan generalization and re-planning capabilities could greatly expand their utility.
Conclusion
This research underscores the promising potential of LLMs in planning tasks when equipped with structured benchmarks and advanced training techniques. As AI systems increasingly face real-world complexities, refining the planning acumen of LLMs will be imperative. This study paves the way for further innovations in integrating language and planning, offering valuable insights for the next generation of intelligent agents.
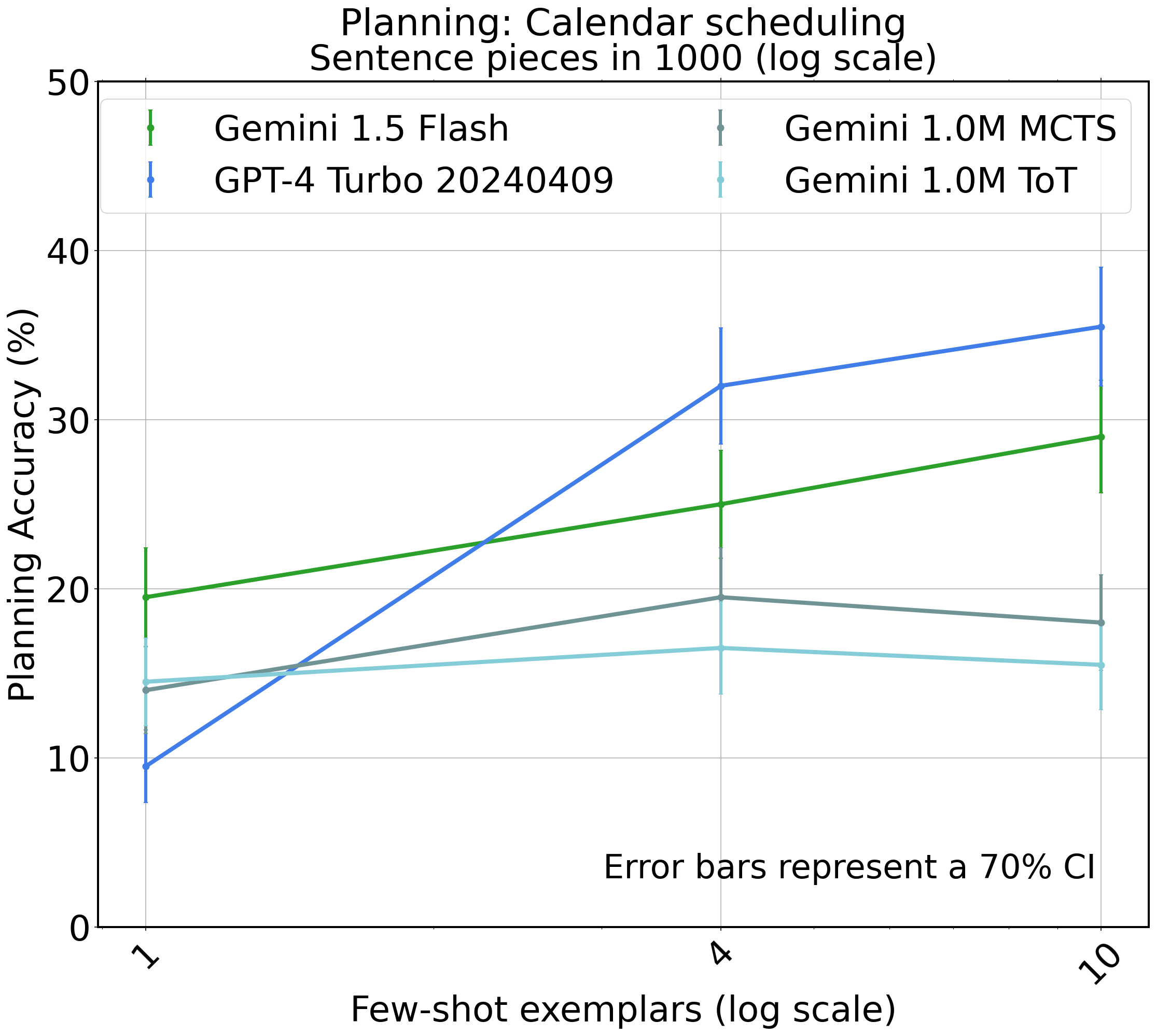
Figure 4: Calendar Scheduling task with search procedures (ToT and MCTS). We use Gemini 1.0 M to perform these procedures, and compare with GPT-4.
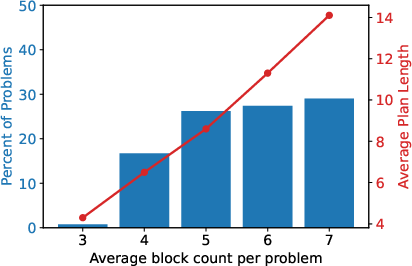
Figure 5: Distribution with number of blocks and average plan length.