- The paper presents a novel bidirectional routing framework (ETR) that improves token-expert assignments and reduces routing complexity.
- It integrates token-choice and expert-choice routing using cosine similarity and Grouped Average Pooling, optimizing computational resource use.
- Experimental results show up to 46.6% improvement in training efficiency and 14.5% gain on downstream tasks.
Expert-Token Resonance MoE: An Analytical Overview
The paper "Expert-Token Resonance MoE: Bidirectional Routing with Efficiency Affinity-Driven Active Selection" (2406.00023) explores the intricate mechanisms of Mixture-of-Experts (MoE) architectures, presenting a novel approach to enhance the routing efficiency and expert specialization simultaneously. This document offers a comprehensive examination of the methods, experiments, and findings articulated in the paper, focusing on the theoretical and practical implications of the proposed Expert-Token Resonance (ETR) framework.
Introduction
The Mixture-of-Experts (MoE) model leverages sparse activation to scale LLMs efficiently, offering a promising path to manage the computational demand as model sizes grow. However, traditional MoE architectures face significant bottlenecks in routing efficiency and expert homogenization, which lead to redundant computations and increased communication overhead. This paper addresses these challenges by introducing Expert-Token Resonance (ETR), a sophisticated bidirectional routing framework designed to optimize the interaction between tokens and experts.
ETR integrates token-choice routing (TCR) and expert-choice routing (ECR) dynamically, allowing for adaptive coordination based on training progression. This approach maximizes the probability of accurate token-expert assignments while significantly reducing the expert capacity lower bound.
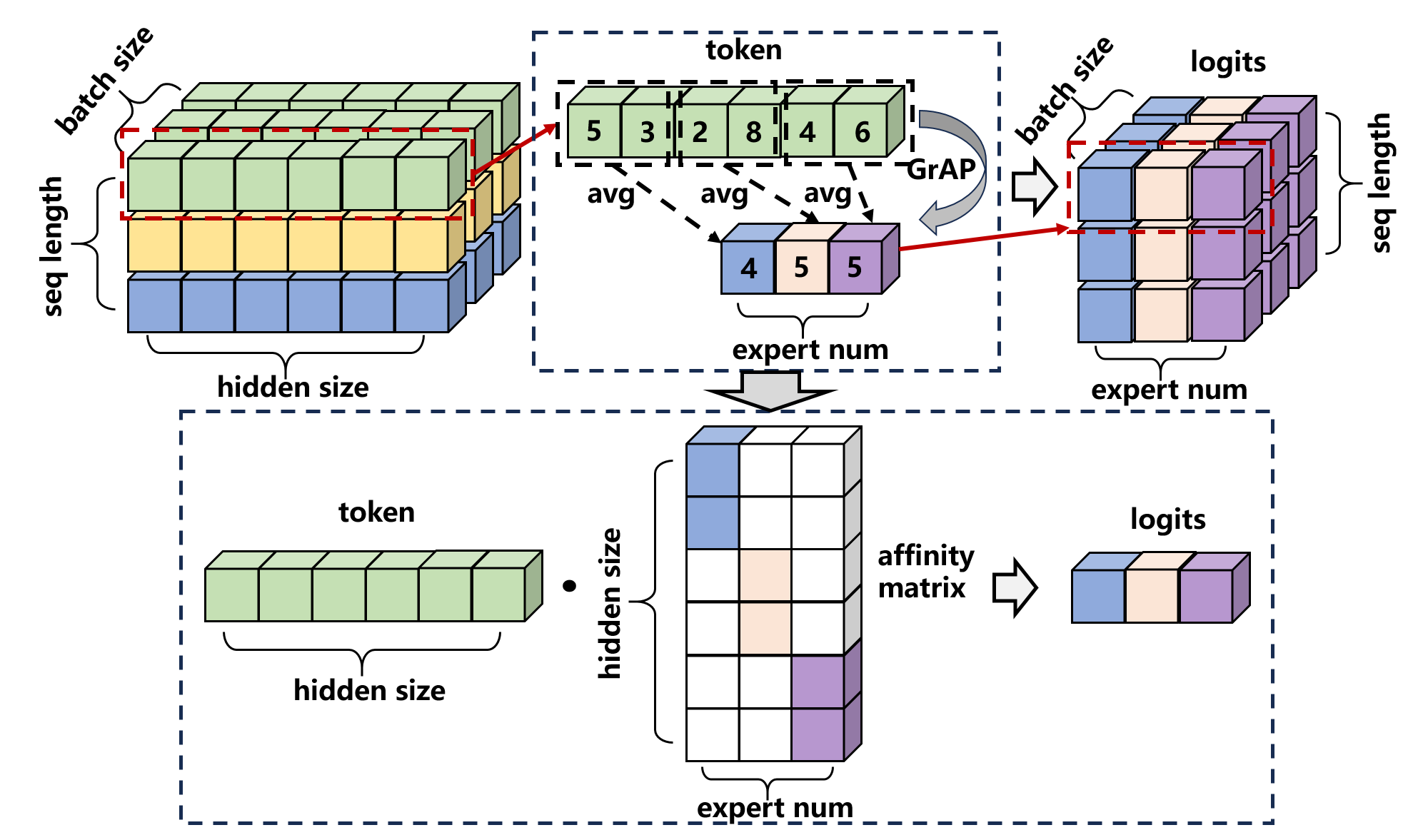
Figure 1: The illustrative diagram of GrAP.
Methodology
Architecture Innovation
ETR's architecture features a novel efficiency-driven affinity-based routing mechanism using Grouped Average Pooling (GrAP). This method reduces the routing complexity while maintaining orthogonal properties crucial for preventing expert homogenization. By employing cosine similarity scores, ETR actively involves both tokens and experts in the selection process, fostering a more specialized and efficient distribution of computational resources.
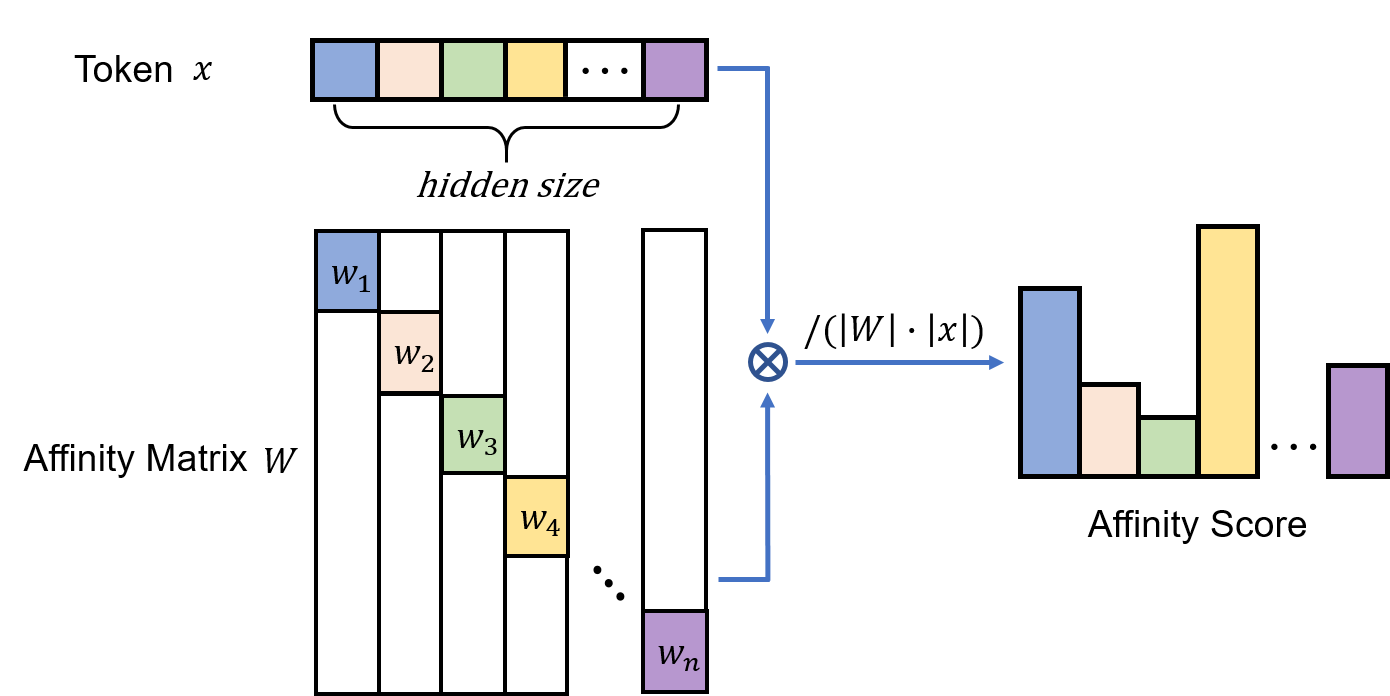
Figure 2: The illustration of affinity score.
Routing and Dynamic Selection
The hybrid TCR+ECR strategy underpinning ETR allows tokens and experts to participate actively in routing decisions. The bidirectional selection process enhances the precision of token assignments, minimizing redundancy and improving specialization outcomes. This dynamic selection is guided by adaptive thresholds based on the evolving training success rates, drawing on measured affinity scores.
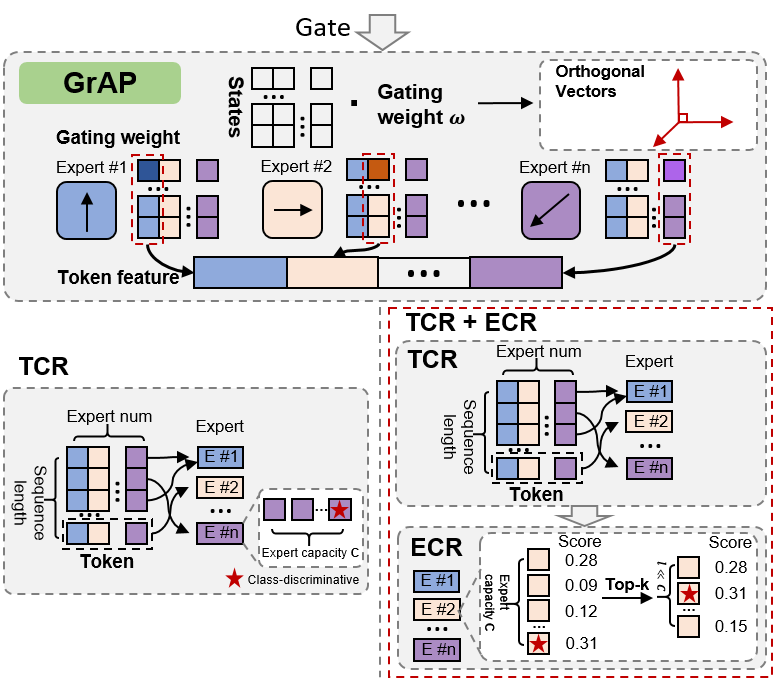
Figure 3: The architecture of the gate network along with the hybrid TCR + ECR router.
Experimental Validation
The paper reports extensive experimental validation across varied cluster configurations, confirming ETR's significant improvements in efficiency and model quality. ETR achieves an increase in end-to-end training efficiency by 5.4%-46.6% compared to baseline methods, alongside performance gains in downstream tasks by up to 14.5% on benchmarks like GDAD and GPQA.
Figure 4: The time consumption during training iterations with different schemes and cluster sizes.
Computational and Memory Efficiency
ETR demonstrates notable reductions in computational overhead and memory footprint. The bidirectional routing mechanism optimizes resource allocation, minimizing idle time and improving overlap between computation and communication phases. This efficiency translates into a 2.9%-13.3% reduction in training times across different cluster scales.
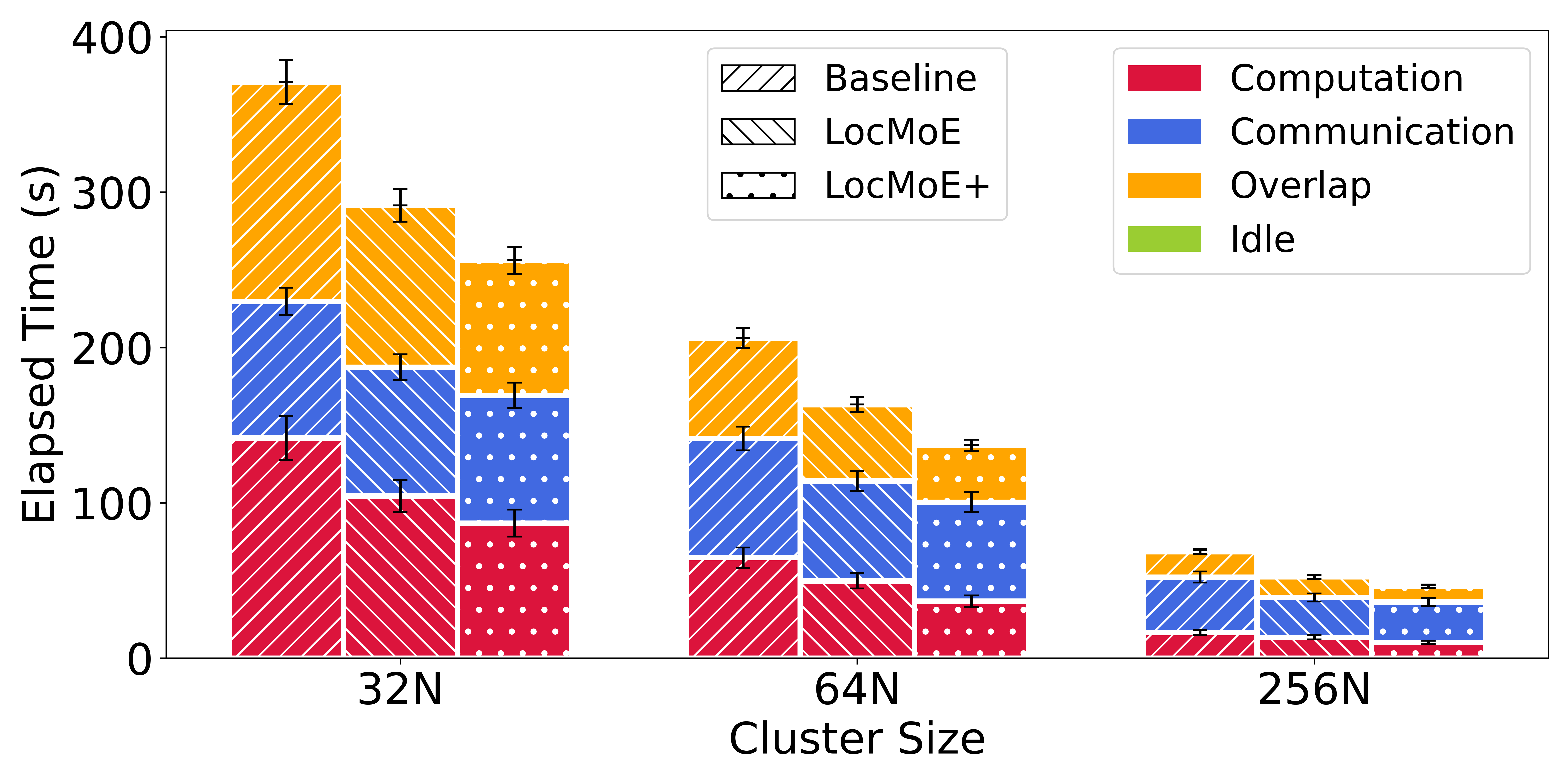
Figure 5: The average composition of computation, communication, overlap, and idle with different schemes and cluster sizes.
Implications and Future Directions
Theoretical and Practical Impact
The introduction of ETR offers a fundamentally new perspective on optimizing sparse model architectures. By harmonizing the demands for computational efficiency and expert specialization, ETR paves the way for deploying larger MoE models previously hampered by communication constraints. The theoretical insights into expert-token dynamics afforded by ETR are poised to stimulate further research into next-generation sparse architectures, potentially driving advancements in both academic and industry applications.
Future Research
The promising results and observations regarding ETR suggest several avenues for future exploration. Enhancing the robustness of the affinity-driven selection criteria and further refining dynamic capacity scaling strategies may yield additional improvements in routing efficiency and model performance. Moreover, expanding the scope of ETR's application to include various types of machine learning models beyond LLMs could broaden the systemic benefits of this approach.
Conclusion
Overall, "Expert-Token Resonance MoE: Bidirectional Routing with Efficiency Affinity-Driven Active Selection" articulates a robust framework that achieves concurrent advances in training efficiency and model output quality for MoE architectures. By resolving key limitations associated with conventional routing strategies, ETR constitutes a significant contribution to the field, providing a scalable and theoretically sound solution for deploying and refining sparse LLMs.