Creative Beam Search: LLM-as-a-Judge For Improving Response Generation
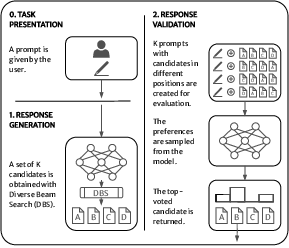
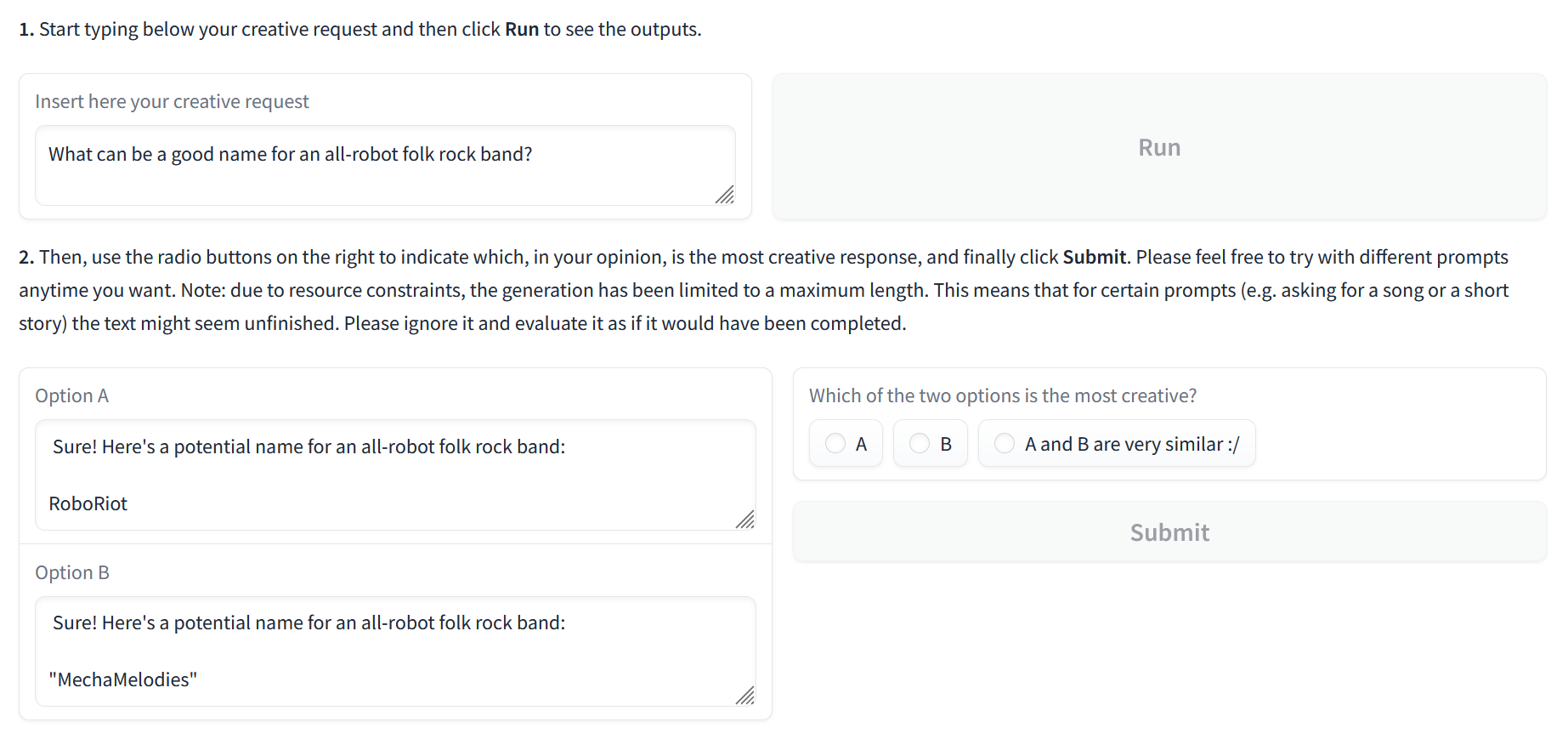
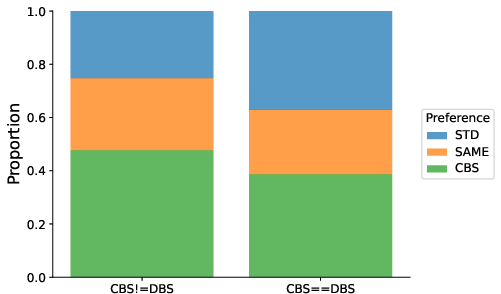
Abstract: LLMs are revolutionizing several areas, including artificial creativity. However, the process of generation in machines profoundly diverges from that observed in humans. In particular, machine generation is characterized by a lack of intentionality and an underlying creative process. We propose a method called Creative Beam Search that uses Diverse Beam Search and LLM-as-a-Judge to perform response generation and response validation. The results of a qualitative experiment show how our approach can provide better output than standard sampling techniques. We also show that the response validation step is a necessary complement to the response generation step.
- 2019. Gradio: Hassle-free sharing and testing of ML models in the wild. arXiv:1906.02569 [cs.LG].
- Amabile, T. M. 1983. The social psychology of creativity: A componential conceptualization. Journal of Personality and Social Psychology 45(2):357–376.
- 2022. Constitutional AI: Harmlessness from AI Feedback. arXiv:2212.08073 [cs.CL].
- 2020. Bridging generative deep learning and computational creativity. In Proceedings of the 11th International Conference on Computational Creativity (ICCC’20).
- 2021. On the opportunities and risks of foundation models. arXiv:2108.07258 [cs.LG].
- 2023. Quality-Diversity through AI feedback. arXiv:2310.13032 [cs.CL].
- 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems (NIPS’20).
- 2020. Language GANs falling short. In Proceedings of the 8th International Conference on Learning Representations (ICLR’20).
- 2024. Self-play fine-tuning converts weak language models to strong language models. arXiv:2401.01335 [cs.LG].
- 2023. Can large language models be an alternative to human evaluations? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL’23).
- 2017. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems (NeurIPS’17).
- 2023. Quality diversity through human feedback. In Proceedings of the NeurIPS’23 ALOE Workshop.
- 2023. On the creativity of large language models. arXiv:2304.00008 [cs.AI].
- 2024. Creativity and machine learning. ACM Computing Surveys. Accepted for Publication. To Appear.
- 2023. Pushing GPT’s creativity to its limits: Alternative Uses and Torrance Tests. In Proceedings of the 14th International Conference on Computational Creativity (ICCC’23).
- 2017. Lexically constrained decoding for sequence generation using grid beam search. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL’17).
- 2020. The curious case of neural text degeneration. In Proceedings of the 8th International Conference on Learning Representations (ICLR’20).
- 2023. RLAIF: Scaling reinforcement learning from human feedback with AI feedback. arXiv:2309.00267 [cs.CL].
- 2023. Is AI art another industrial revolution in the making? In Proceedings of the AAAI’23 Creative AI Across Modalities Workshop.
- OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL].
- 2018. Analyzing uncertainty in neural machine translation. In Proceedings of the 35th International Conference on Machine Learning (ICML’18).
- 2023. Leveraging human preferences to master poetry. In Proceedings of the AAAI’23 Workshop on Creative AI Across Modalities.
- 2023a. Bits of Grass: Does GPT already know how to write like Whitman? In Proceedings of the 14th International Conference on Computational Creativity (ICCC’23).
- 2023b. On the power of special-purpose GPT models to create and evaluate new poetry in old styles. In Proc. of the 14th International Conference on Computational Creativity (ICCC’23).
- Shanahan, M. 2024. Talking about large language models. Communications of the ACM 67(2):68–79.
- 2022. Putting GPT-3’s creativity to the (Alternative Uses) Test. In Proceedings of the 13th International Conference on Computational Creativity (ICCC’22).
- 2023. Brainstorm, then select: a generative language model improves its creativity score. In Proceedings of the AAAI’23 Workshop on Creative AI Across Modalities.
- 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288 [cs.CL].
- 2018. Diverse beam search for improved description of complex scenes. Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI’18).
- 2023. Large language models are not fair evaluators. arXiv:2305.17926 [cs.CL].
- 2022. Taxonomy of risks posed by language models. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT’22).
- 2023. Self-evaluation guided beam search for reasoning. In Proceedings of the 37th Conference on Neural Information Processing Systems (NIPS’23).
- 2024. Self-rewarding language models. arXiv:2401.10020 [cs.CL].
- 2023. Judging LLM-as-a-judge with MT-bench and chatbot arena. In Proceedings of the 37th Conference on Neural Information Processing Systems Datasets and Benchmarks Track (NIPS’23).
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.