Automated Feature Selection for Inverse Reinforcement Learning
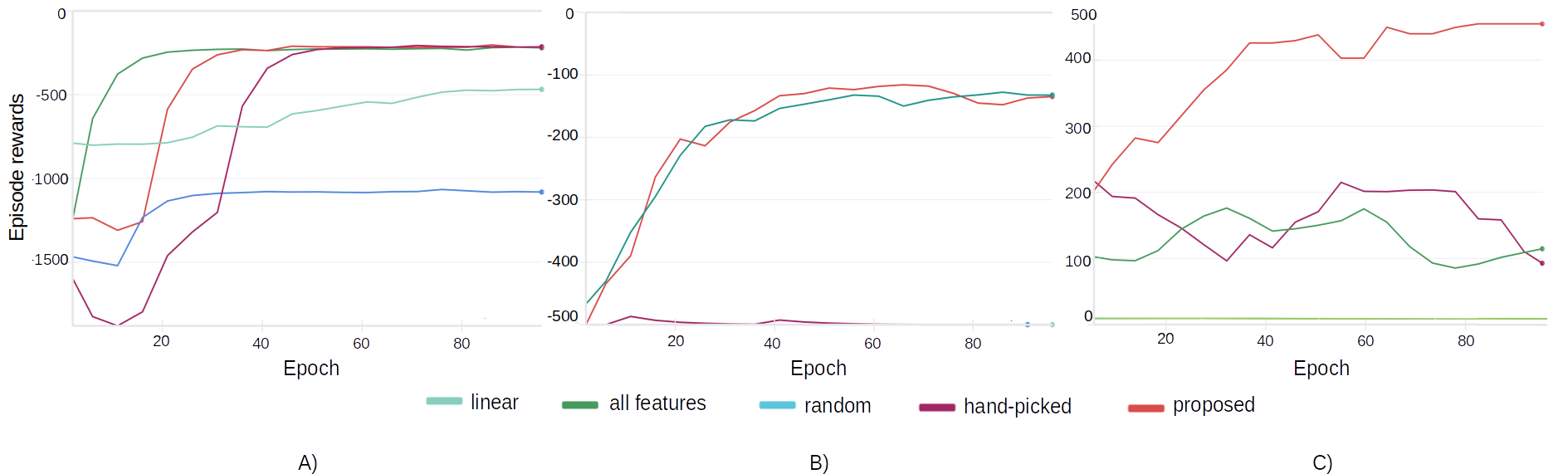
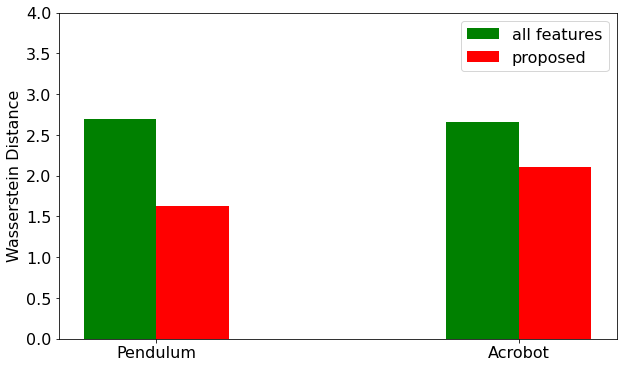
Abstract: Inverse reinforcement learning (IRL) is an imitation learning approach to learning reward functions from expert demonstrations. Its use avoids the difficult and tedious procedure of manual reward specification while retaining the generalization power of reinforcement learning. In IRL, the reward is usually represented as a linear combination of features. In continuous state spaces, the state variables alone are not sufficiently rich to be used as features, but which features are good is not known in general. To address this issue, we propose a method that employs polynomial basis functions to form a candidate set of features, which are shown to allow the matching of statistical moments of state distributions. Feature selection is then performed for the candidates by leveraging the correlation between trajectory probabilities and feature expectations. We demonstrate the approach's effectiveness by recovering reward functions that capture expert policies across non-linear control tasks of increasing complexity. Code, data, and videos are available at https://sites.google.com/view/feature4irl.
- T. Ni, H. Sikchi, Y. Wang, T. Gupta, L. Lee, and B. Eysenbach, “f-irl: Inverse reinforcement learning via state marginal matching,” in Conference on Robot Learning. PMLR, 2021, pp. 529–551.
- F. Torabi, G. Warnell, and P. Stone, “Behavioral cloning from observation,” arXiv preprint arXiv:1805.01954, 2018.
- A. Y. Ng, S. Russell et al., “Algorithms for inverse reinforcement learning.” in Icml, vol. 1, no. 2, 2000, p. 2.
- T. Xu, Z. Li, and Y. Yu, “Error bounds of imitating policies and environments,” Advances in Neural Information Processing Systems, vol. 33, pp. 15 737–15 749, 2020.
- P. Abbeel and A. Y. Ng, “Apprenticeship learning via inverse reinforcement learning,” in Twenty-First International Conference on Machine Learning - ICML ’04. Banff, Alberta, Canada: ACM Press, 2004, p. 1.
- Krakovna, Victoria and Uesato, Jonathan and Mikulik, Vladimir and Rahtz, Matthew and Everitt, Tom and Kumar, Ramana and Kenton, Zac and Leike, Jan and Legg, Shane, “Specification gaming: The flip side of ai ingenuity,” https://deepmind.com/blog/article/specification-gaming-the-flip-side-of-ai-ingenuity, 2020, accessed: 2024-03-10.
- B. D. Ziebart, A. L. Maas, J. A. Bagnell, A. K. Dey et al., “Maximum entropy inverse reinforcement learning.” in Aaai, vol. 8. Chicago, IL, USA, 2008, pp. 1433–1438.
- A. Boularias, J. Kober, and J. Peters, “Relative entropy inverse reinforcement learning,” in Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 182–189.
- Q. Qiao and P. A. Beling, “Inverse reinforcement learning with gaussian process,” in Proceedings of the 2011 American control conference. IEEE, 2011, pp. 113–118.
- J.-D. Choi and K.-E. Kim, “Inverse reinforcement learning in partially observable environments,” Journal of Machine Learning Research, vol. 12, pp. 691–730, 2011.
- N. Aghasadeghi and T. Bretl, “Maximum entropy inverse reinforcement learning in continuous state spaces with path integrals,” in 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, 2011, pp. 1561–1566.
- G. Dexter, K. Bello, and J. Honorio, “Inverse reinforcement learning in a continuous state space with formal guarantees,” Advances in Neural Information Processing Systems, vol. 34, pp. 6972–6982, 2021.
- S. Tesfazgi, A. Lederer, and S. Hirche, “Inverse reinforcement learning: A control lyapunov approach,” in 2021 60th IEEE Conference on Decision and Control (CDC). IEEE, 2021, pp. 3627–3632.
- Y. Xu, W. Gao, and D. Hsu, “Receding horizon inverse reinforcement learning,” Advances in Neural Information Processing Systems, vol. 35, pp. 27 880–27 892, 2022.
- T. Phan-Minh, F. Howington, T.-S. Chu, S. U. Lee, M. S. Tomov, N. Li, C. Dicle, S. Findler, F. Suarez-Ruiz, R. Beaudoin et al., “Driving in real life with inverse reinforcement learning,” arXiv preprint arXiv:2206.03004, 2022.
- M. Kuderer, S. Gulati, and W. Burgard, “Learning driving styles for autonomous vehicles from demonstration,” in 2015 IEEE international conference on robotics and automation (ICRA). IEEE, 2015, pp. 2641–2646.
- S. Levine, Z. Popovic, and V. Koltun, “Nonlinear inverse reinforcement learning with gaussian processes,” Advances in neural information processing systems, vol. 24, 2011.
- C. Finn, P. Christiano, P. Abbeel, and S. Levine, “Learning robust rewards with adversarial inverse reinforcement learning,” arXiv:1710.11248, 2016. [Online]. Available: https://arxiv.org/abs/1710.11248
- J. Fu, K. Luo, and S. Levine, “Learning robust rewards with adversarial inverse reinforcement learning,” arXiv preprint arXiv:1710.11248, 2017.
- S. Levine, Z. Popovic, and V. Koltun, “Feature construction for inverse reinforcement learning,” Advances in neural information processing systems, vol. 23, 2010.
- J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V. Kumar, H. Zhu, A. Gupta, P. Abbeel et al., “Soft actor-critic algorithms and applications,” arXiv preprint arXiv:1812.05905, 2018.
- M. Towers, J. K. Terry, A. Kwiatkowski, J. U. Balis, G. d. Cola, T. Deleu, M. Goulão, A. Kallinteris, A. KG, M. Krimmel, R. Perez-Vicente, A. Pierré, S. Schulhoff, J. J. Tai, A. T. J. Shen, and O. G. Younis, “Gymnasium,” Mar. 2023. [Online]. Available: https://zenodo.org/record/8127025
- A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning implementations,” Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021. [Online]. Available: http://jmlr.org/papers/v22/20-1364.html
- G. Konidaris, S. Osentoski, and P. Thomas, “Value function approximation in reinforcement learning using the fourier basis,” in Proceedings of the AAAI conference on artificial intelligence, vol. 25, no. 1, 2011, pp. 380–385.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.