Threats, Attacks, and Defenses in Machine Unlearning: A Survey
Abstract: Machine Unlearning (MU) has recently gained considerable attention due to its potential to achieve Safe AI by removing the influence of specific data from trained Machine Learning (ML) models. This process, known as knowledge removal, addresses AI governance concerns of training data such as quality, sensitivity, copyright restrictions, and obsolescence. This capability is also crucial for ensuring compliance with privacy regulations such as the Right To Be Forgotten (RTBF). Furthermore, effective knowledge removal mitigates the risk of harmful outcomes, safeguarding against biases, misinformation, and unauthorized data exploitation, thereby enhancing the safe and responsible use of AI systems. Efforts have been made to design efficient unlearning approaches, with MU services being examined for integration with existing machine learning as a service (MLaaS), allowing users to submit requests to remove specific data from the training corpus. However, recent research highlights vulnerabilities in machine unlearning systems, such as information leakage and malicious unlearning, that can lead to significant security and privacy concerns. Moreover, extensive research indicates that unlearning methods and prevalent attacks fulfill diverse roles within MU systems. This underscores the intricate relationship and complex interplay among these mechanisms in maintaining system functionality and safety. This survey aims to fill the gap between the extensive number of studies on threats, attacks, and defenses in machine unlearning and the absence of a comprehensive review that categorizes their taxonomy, methods, and solutions, thus offering valuable insights for future research directions and practical implementations.
- G. D. P. Regulation, “General data protection regulation (gdpr),” Intersoft Consulting, Accessed in October, vol. 24, no. 1, 2018.
- H. Iwase, “Overview of the act on the protection of personal information,” Eur. Data Prot. L. Rev., vol. 5, p. 92, 2019.
- E. Goldman, “An introduction to the california consumer privacy act (ccpa),” Santa Clara Univ. Legal Studies Research Paper, 2020.
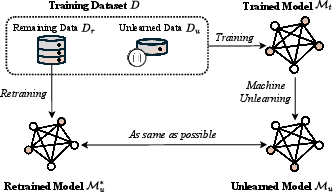
- L. Bourtoule, V. Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” in 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 141–159.
- Y. Zhao, P. Wang, H. Qi, J. Huang, Z. Wei, and Q. Zhang, “Federated unlearning with momentum degradation,” IEEE Internet of Things Journal, 2023.
- Y. Liu, L. Xu, X. Yuan, C. Wang, and B. Li, “The right to be forgotten in federated learning: An efficient realization with rapid retraining,” in IEEE INFOCOM 2022-IEEE Conference on Computer Communications. IEEE, 2022, pp. 1749–1758.
- P. Wang, W. Song, H. Qi, C. Zhou, F. Li, Y. Wang, P. Sun, and Q. Zhang, “Server-initiated federated unlearning to eliminate impacts of low-quality data,” IEEE Transactions on Services Computing, no. 01, pp. 1–15, 2024.
- T. T. Nguyen, T. T. Huynh, P. L. Nguyen, A. W.-C. Liew, H. Yin, and Q. V. H. Nguyen, “A survey of machine unlearning,” arXiv preprint arXiv:2209.02299, 2022.
- J. Xu, Z. Wu, C. Wang, and X. Jia, “Machine unlearning: Solutions and challenges,” arXiv preprint arXiv:2308.07061, 2023.
- Y. Qu, X. Yuan, M. Ding, W. Ni, T. Rakotoarivelo, and D. Smith, “Learn to unlearn: A survey on machine unlearning,” arXiv preprint arXiv:2305.07512, 2023.
- Y. Lin, Z. Gao, H. Du, J. Ren, Z. Xie, and D. Niyato, “Blockchain-enabled trustworthy federated unlearning,” arXiv preprint arXiv:2401.15917, 2024.
- N. Ding, E. Wei, and R. Berry, “Strategic data revocation in federated unlearning,” arXiv preprint arXiv:2312.01235, 2023.
- J. Shao, T. Lin, X. Cao, and B. Luo, “Federated unlearning: a perspective of stability and fairness,” arXiv preprint arXiv:2402.01276, 2024.
- N. Ding, Z. Sun, E. Wei, and R. Berry, “Incentivized federated learning and unlearning,” arXiv preprint arXiv:2308.12502, 2023.
- T. Shaik, X. Tao, H. Xie, L. Li, X. Zhu, and Q. Li, “Exploring the landscape of machine unlearning: A survey and taxonomy,” arXiv preprint arXiv:2305.06360, 2023.
- N. Ding, Z. Sun, E. Wei, and R. Berry, “Incentive mechanism design for federated learning and unlearning,” in Proceedings of the Twenty-fourth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, 2023, pp. 11–20.
- H. Xu, T. Zhu, L. Zhang, W. Zhou, and P. S. Yu, “Machine unlearning: A survey,” ACM Computing Surveys, vol. 56, no. 1, pp. 1–36, 2023.
- Y. Lin, Z. Gao, H. Du, D. Niyato, G. Gui, S. Cui, and J. Ren, “Scalable federated unlearning via isolated and coded sharding,” arXiv preprint arXiv:2401.15957, 2024.
- Z. Liu, Y. Jiang, J. Shen, M. Peng, K.-Y. Lam, X. Yuan, and X. Liu, “A survey on federated unlearning: Challenges, methods, and future directions,” arXiv preprint arXiv:2310.20448, 2023.
- J. Yang and Y. Zhao, “A survey of federated unlearning: A taxonomy, challenges and future directions,” arXiv preprint arXiv:2310.19218, 2023.
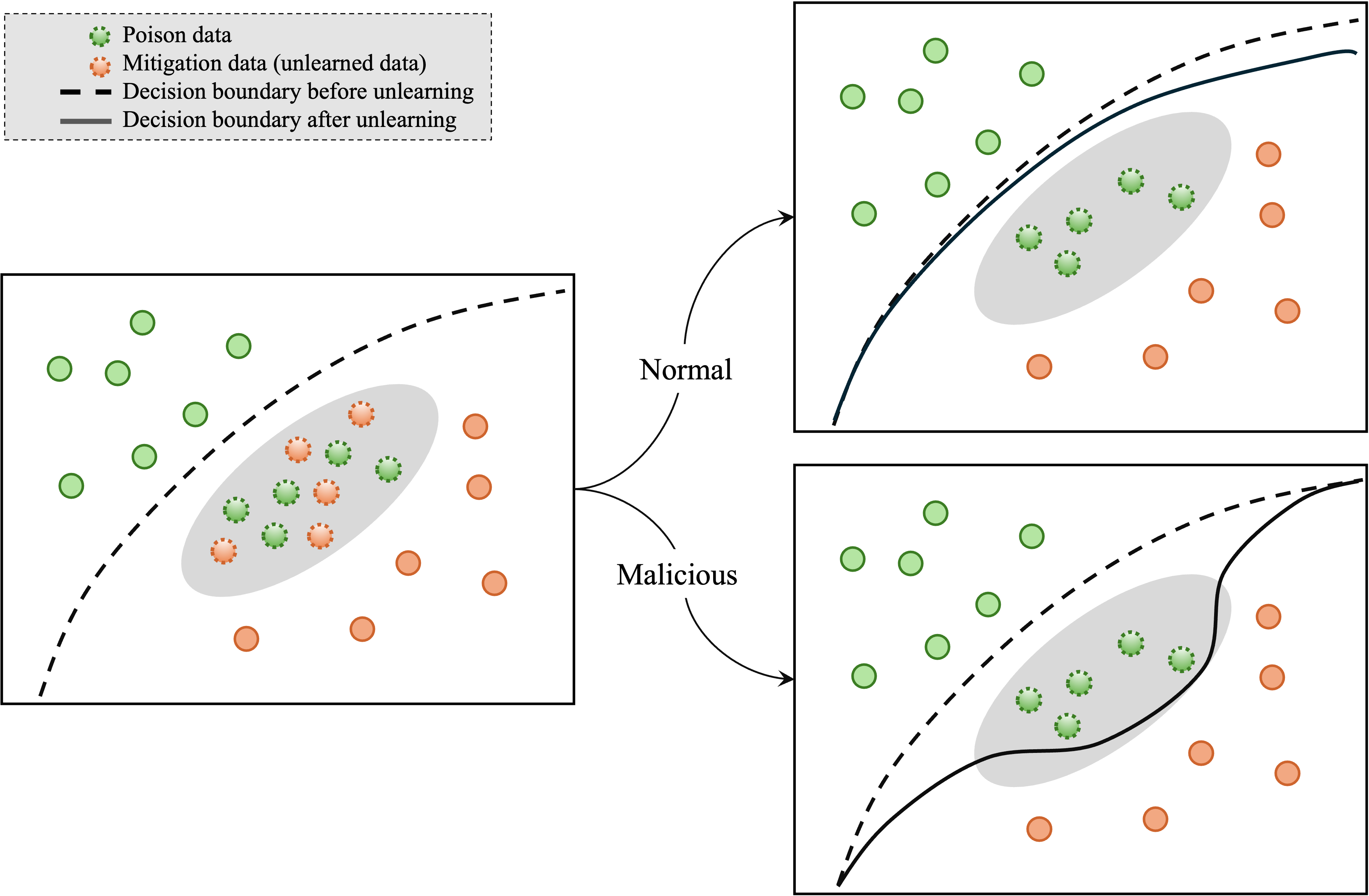
- J. Z. Di, J. Douglas, J. Acharya, G. Kamath, and A. Sekhari, “Hidden poison: Machine unlearning enables camouflaged poisoning attacks,” in NeurIPS ML Safety Workshop, 2022.
- H. Hu, S. Wang, J. Chang, H. Zhong, R. Sun, S. Hao, H. Zhu, and M. Xue, “A duty to forget, a right to be assured? exposing vulnerabilities in machine unlearning services,” in Proceedings of the Network and Distributed System Security Symposium, 2024.
- R. Shokri, M. Stronati, C. Song, and V. Shmatikov, “Membership inference attacks against machine learning models,” in 2017 IEEE symposium on security and privacy (SP). IEEE, 2017, pp. 3–18.
- Y. Xie, J. Zhang, S. Zhao, T. Zhang, and X. Chen, “Same: Sample reconstruction against model extraction attacks,” arXiv preprint arXiv:2312.10578, 2023.
- Z. He, T. Zhang, and R. B. Lee, “Model inversion attacks against collaborative inference,” in Proceedings of the 35th Annual Computer Security Applications Conference, 2019, pp. 148–162.
- M. Chen, Z. Zhang, T. Wang, M. Backes, M. Humbert, and Y. Zhang, “When machine unlearning jeopardizes privacy,” in Proceedings of the 2021 ACM SIGSAC conference on computer and communications security, 2021, pp. 896–911.
- Y. Liu, S. Ma, Y. Aafer, W.-C. Lee, J. Zhai, W. Wang, and X. Zhang, “Trojaning attack on neural networks,” in 25th Annual Network And Distributed System Security Symposium (NDSS 2018). Internet Soc, 2018.
- D. M. Sommer, L. Song, S. Wagh, and P. Mittal, “Towards probabilistic verification of machine unlearning,” arXiv preprint arXiv:2003.04247, 2020.
- C. Dwork, “Differential privacy,” in International colloquium on automata, languages, and programming. Springer, 2006, pp. 1–12.
- K. Zhang, Y. Zhang, R. Sun, P.-W. Tsai, M. U. Hassan, X. Yuan, M. Xue, and J. Chen, “Bounded and unbiased composite differential privacy,” in 2024 IEEE Symposium on Security and Privacy (SP), 2024.
- P. Zhang, J. Sun, M. Tan, and X. Wang, “Exploiting machine unlearning for backdoor attacks in deep learning system,” arXiv preprint arXiv:2310.10659, 2023.
- Y. Liu, M. Fan, C. Chen, X. Liu, Z. Ma, L. Wang, and J. Ma, “Backdoor defense with machine unlearning,” in IEEE INFOCOM 2022-IEEE Conference on Computer Communications. IEEE, 2022, pp. 280–289.
- X. Cao, J. Jia, Z. Zhang, and N. Z. Gong, “Fedrecover: Recovering from poisoning attacks in federated learning using historical information,” in 2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023, pp. 1366–1383.
- B. Wang, Y. Yao, S. Shan, H. Li, B. Viswanath, H. Zheng, and B. Y. Zhao, “Neural cleanse: Identifying and mitigating backdoor attacks in neural networks,” in 2019 IEEE Symposium on Security and Privacy (SP). IEEE, 2019, pp. 707–723.
- X. Lu, S. Welleck, J. Hessel, L. Jiang, L. Qin, P. West, P. Ammanabrolu, and Y. Choi, “Quark: Controllable text generation with reinforced unlearning,” Advances in neural information processing systems, vol. 35, pp. 27 591–27 609, 2022.
- S. Liu, Y. Yao, J. Jia, S. Casper, N. Baracaldo, P. Hase, X. Xu, Y. Yao, H. Li, K. R. Varshney et al., “Rethinking machine unlearning for large language models,” arXiv preprint arXiv:2402.08787, 2024.
- J. Liu, P. Ram, Y. Yao, G. Liu, Y. Liu, P. SHARMA, S. Liu et al., “Model sparsity can simplify machine unlearning,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- H. Jeong, S. Ma, and A. Houmansadr, “Sok: Challenges and opportunities in federated unlearning,” arXiv preprint arXiv:2403.02437, 2024.
- N. Romandini, A. Mora, C. Mazzocca, R. Montanari, and P. Bellavista, “Federated unlearning: A survey on methods, design guidelines, and evaluation metrics,” arXiv preprint arXiv:2401.05146, 2024.
- F. Wang, B. Li, and B. Li, “Federated unlearning and its privacy threats,” IEEE Network, 2023.
- Z. Lu, H. Liang, M. Zhao, Q. Lv, T. Liang, and Y. Wang, “Label-only membership inference attacks on machine unlearning without dependence of posteriors,” International Journal of Intelligent Systems, vol. 37, no. 11, pp. 9424–9441, 2022.
- Y. Hu, J. Lou, J. Liu, F. Lin, Z. Qin, and K. Ren, “Eraser: Machine unlearning in mlaas via an inference serving-aware approach,” arXiv preprint arXiv:2311.16136, 2023.
- J. Gao, S. Garg, M. Mahmoody, and P. N. Vasudevan, “Deletion inference, reconstruction, and compliance in machine (un) learning,” Proceedings on Privacy Enhancing Technologies, 2022.
- R. Chourasia and N. Shah, “Forget unlearning: Towards true data-deletion in machine learning,” in International Conference on Machine Learning. PMLR, 2023, pp. 6028–6073.
- L. Schwinn, D. Dobre, S. Xhonneux, G. Gidel, and S. Gunnemann, “Soft prompt threats: Attacking safety alignment and unlearning in open-source llms through the embedding space,” arXiv preprint arXiv:2402.09063, 2024.
- V. Gupta, C. Jung, S. Neel, A. Roth, S. Sharifi-Malvajerdi, and C. Waites, “Adaptive machine unlearning,” Advances in Neural Information Processing Systems, vol. 34, pp. 16 319–16 330, 2021.
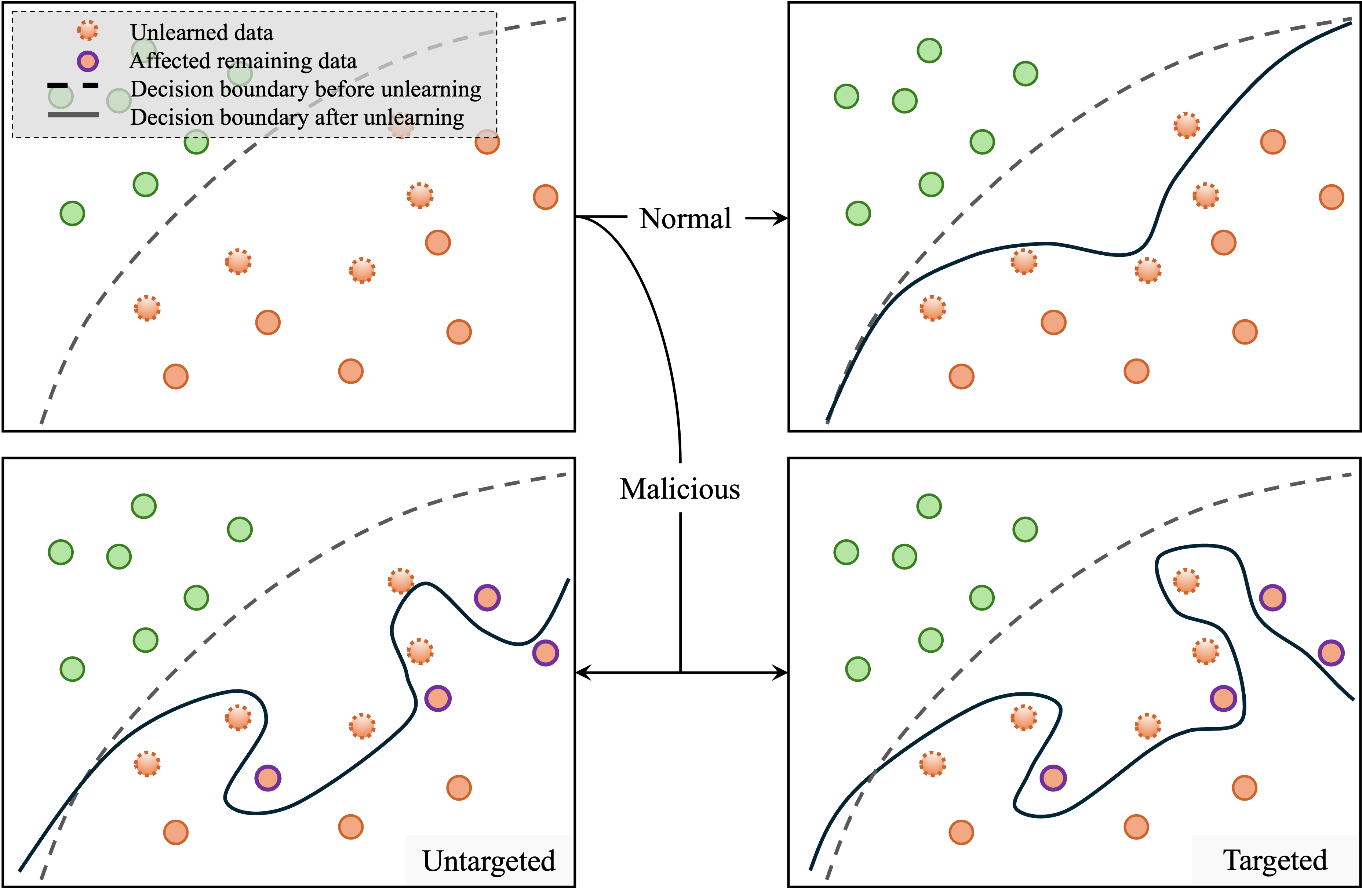
- C. Zhao, W. Qian, R. Ying, and M. Huai, “Static and sequential malicious attacks in the context of selective forgetting,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” in 2017 ieee symposium on security and privacy (sp). Ieee, 2017, pp. 39–57.
- P.-Y. Chen, H. Zhang, Y. Sharma, J. Yi, and C.-J. Hsieh, “Zoo: Zeroth order optimization based black-box attacks to deep neural networks without training substitute models,” in Proceedings of the 10th ACM workshop on artificial intelligence and security, 2017, pp. 15–26.
- W. Qian, C. Zhao, W. Le, M. Ma, and M. Huai, “Towards understanding and enhancing robustness of deep learning models against malicious unlearning attacks,” in Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2023, pp. 1932–1942.
- J. Geiping, L. H. Fowl, W. R. Huang, W. Czaja, G. Taylor, M. Moeller, and T. Goldstein, “Witches’ brew: Industrial scale data poisoning via gradient matching,” in International Conference on Learning Representations, 2020.
- T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, “Badnets: Evaluating backdooring attacks on deep neural networks,” IEEE Access, vol. 7, pp. 47 230–47 244, 2019.
- N. G. Marchant, B. I. Rubinstein, and S. Alfeld, “Hard to forget: Poisoning attacks on certified machine unlearning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 7, 2022, pp. 7691–7700.
- C. Guo, T. Goldstein, A. Hannun, and L. Van Der Maaten, “Certified data removal from machine learning models,” arXiv preprint arXiv:1911.03030, 2019.
- S. Mei and X. Zhu, “Using machine teaching to identify optimal training-set attacks on machine learners,” in Proceedings of the aaai conference on artificial intelligence, vol. 29, no. 1, 2015.
- S. R. Kadhe, A. Halimi, A. Rawat, and N. Baracaldo, “Fairsisa: Ensemble post-processing to improve fairness of unlearning in llms,” arXiv preprint arXiv:2312.07420, 2023.
- I. B. Soares, D. Wei, K. N. Ramamurthy, M. Singh, and M. Yurochkin, “Your fairness may vary: pretrained language model fairness in toxic text classification,” in Annual Meeting of the Association for Computational Linguistics, 2022.
- J. Tan, F. Sun, R. Qiu, D. Su, and H. Shen, “Unlink to unlearn: Simplifying edge unlearning in gnns,” arXiv preprint arXiv:2402.10695, 2024.
- J. Cheng, G. Dasoulas, H. He, C. Agarwal, and M. Zitnik, “Gnndelete: A general strategy for unlearning in graph neural networks,” arXiv preprint arXiv:2302.13406, 2023.
- S. Li, M. Xue, B. Z. H. Zhao, H. Zhu, and X. Zhang, “Invisible backdoor attacks on deep neural networks via steganography and regularization,” IEEE Transactions on Dependable and Secure Computing, vol. 18, no. 5, pp. 2088–2105, 2020.
- S. Li, H. Liu, T. Dong, B. Z. H. Zhao, M. Xue, H. Zhu, and J. Lu, “Hidden backdoors in human-centric language models,” in Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, 2021, pp. 3123–3140.
- J. Zhang, C. Dongdong, Q. Huang, J. Liao, W. Zhang, H. Feng, G. Hua, and N. Yu, “Poison ink: Robust and invisible backdoor attack,” IEEE Transactions on Image Processing, vol. 31, pp. 5691–5705, 2022.
- X. Han, Y. Wu, Q. Zhang, Y. Zhou, Y. Xu, H. Qiu, G. Xu, and T. Zhang, “Backdooring multimodal learning,” in 2024 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, 2023, pp. 31–31.
- Y. Wu, J. Zhang, F. Kerschbaum, T. Zhang et al., “Backdooring textual inversion for concept censorship,” arXiv preprint arXiv:2308.10718, 2023.
- H. Wang, T. Xiang, S. Guo, J. He, H. Liu, and T. Zhang, “Transtroj: Transferable backdoor attacks to pre-trained models via embedding indistinguishability,” arXiv preprint arXiv:2401.15883, 2024.
- J. Xu, M. Xue, and S. Picek, “Explainability-based backdoor attacks against graph neural networks,” in Proceedings of the 3rd ACM workshop on wireless security and machine learning, 2021, pp. 31–36.
- W. Ma, D. Wang, R. Sun, M. Xue, S. Wen, and Y. Xiang, “The” beatrix”resurrections: Robust backdoor detection via gram matrices,” in Proceedings of the Network And Distributed System Security Symposium (NDSS 2023), 2023.
- Y. Li, H. Ma, Z. Zhang, Y. Gao, A. Abuadbba, M. Xue, A. Fu, Y. Zheng, S. F. Al-Sarawi, and D. Abbott, “Ntd: Non-transferability enabled deep learning backdoor detection,” IEEE Transactions on Information Forensics and Security, 2023.
- W. Guo, L. Wang, X. Xing, M. Du, and D. Song, “Tabor: A highly accurate approach to inspecting and restoring trojan backdoors in ai systems,” arXiv preprint arXiv:1908.01763, 2019.
- Y. Zeng, S. Chen, W. Park, Z. M. Mao, M. Jin, and R. Jia, “Adversarial unlearning of backdoors via implicit hypergradient,” arXiv preprint arXiv:2110.03735, 2021.
- S. Wei, M. Zhang, H. Zha, and B. Wu, “Shared adversarial unlearning: Backdoor mitigation by unlearning shared adversarial examples,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- H. Bansal, N. Singhi, Y. Yang, F. Yin, A. Grover, and K.-W. Chang, “Cleanclip: Mitigating data poisoning attacks in multimodal contrastive learning,” arXiv preprint arXiv:2303.03323, 2023.
- Y. Jiang, J. Shen, Z. Liu, C. W. Tan, and K.-Y. Lam, “Towards efficient and certified recovery from poisoning attacks in federated learning,” arXiv preprint arXiv:2401.08216, 2024.
- Y. Li, C. Chen, X. Zheng, Y. Zhang, Z. Han, D. Meng, and J. Wang, “Making users indistinguishable: Attribute-wise unlearning in recommender systems,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 984–994.
- Y. Yao, X. Xu, and Y. Liu, “Large language model unlearning,” arXiv preprint arXiv:2310.10683, 2023.
- H. Li, G. Deng, Y. Liu, K. Wang, Y. Li, T. Zhang, Y. Liu, G. Xu, G. Xu, and H. Wang, “Digger: Detecting copyright content mis-usage in large language model training,” arXiv preprint arXiv:2401.00676, 2024.
- Z. Liu, G. Dou, Z. Tan, Y. Tian, and M. Jiang, “Towards safer large language models through machine unlearning,” arXiv preprint arXiv:2402.10058, 2024.
- P. Wang, Z. Wei, H. Qi, S. Wan, Y. Xiao, G. Sun, and Q. Zhang, “Mitigating poor data quality impact with federated unlearning for human-centric metaverse,” IEEE Journal on Selected Areas in Communications, 2023.
- X. Guo, P. Wang, S. Qiu, W. Song, Q. Zhang, X. Wei, and D. Zhou, “Fast: Adopting federated unlearning to eliminating malicious terminals at server side,” IEEE Transactions on Network Science and Engineering, 2023.
- H. Bano, M. Ameen, M. Mehdi, A. Hussain, and P. Wang, “Federated unlearning and server right to forget: Handling unreliable client contributions,” in International Conference on Recent Trends in Image Processing and Pattern Recognition. Springer, 2023, pp. 393–410.
- M. Isonuma and I. Titov, “Unlearning reveals the influential training data of language models,” arXiv preprint arXiv:2401.15241, 2024.
- R. Sun, M. Xue, G. Tyson, S. Wang, S. Camtepe, and S. Nepal, “Not seen, not heard in the digital world! measuring privacy practices in children’s apps,” in Proceedings of the ACM Web Conference 2023, 2023, pp. 2166–2177.
- A. Hu, Z. Lu, R. Xie, and M. Xue, “Veridip: Verifying ownership of deep neural networks through privacy leakage fingerprints,” IEEE Transactions on Dependable and Secure Computing, 2023.
- L. Wang, X. Zeng, J. Guo, K.-F. Wong, and G. Gottlob, “Selective forgetting: Advancing machine unlearning techniques and evaluation in language models,” arXiv preprint arXiv:2402.05813, 2024.
- B. G. Doan, M. Xue, S. Ma, E. Abbasnejad, and D. C. Ranasinghe, “Tnt attacks! universal naturalistic adversarial patches against deep neural network systems,” IEEE Transactions on Information Forensics and Security, vol. 17, pp. 3816–3830, 2022.
- Y. Cao, X. Xiao, R. Sun, D. Wang, M. Xue, and S. Wen, “Stylefool: Fooling video classification systems via style transfer,” in 2023 IEEE Symposium on Security and Privacy (SP). IEEE, 2023, pp. 1631–1648.
- Y. Cao, Z. Zhao, X. Xiao, D. Wang, M. Xue, and J. Lu, “Logostylefool: Vitiating video recognition systems via logo style transfer,” in 38th AAAI Conference on Artificial Intelligence. AAAI, 2024.
- Y. Liu, J. Peng, J. James, and Y. Wu, “Ppgan: Privacy-preserving generative adversarial network,” in 2019 IEEE 25Th international conference on parallel and distributed systems (ICPADS). IEEE, 2019, pp. 985–989.
- Y. Cao, J. Li, X. Xiao, D. Wang, M. Xue, H. Ge, W. Liu, and G. Hu, “Localstylefool: Regional video style transfer attack using segment anything model,” in 2024 IEEE Symposium on Security and Privacy Workshop (SPW), 2024.
- Z. Zhang, Y. Zhou, X. Zhao, T. Che, and L. Lyu, “Prompt certified machine unlearning with randomized gradient smoothing and quantization,” Advances in Neural Information Processing Systems, vol. 35, pp. 13 433–13 455, 2022.
- T. Che, Y. Zhou, Z. Zhang, L. Lyu, J. Liu, D. Yan, D. Dou, and J. Huan, “Fast federated machine unlearning with nonlinear functional theory,” in International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, ser. Proceedings of Machine Learning Research, vol. 202. PMLR, 2023, pp. 4241–4268.
- J. Cohen, E. Rosenfeld, and Z. Kolter, “Certified adversarial robustness via randomized smoothing,” in international conference on machine learning. PMLR, 2019, pp. 1310–1320.
- V. S. Chundawat, A. K. Tarun, M. Mandal, and M. Kankanhalli, “Zero-shot machine unlearning,” IEEE Transactions on Information Forensics and Security, 2023.
- Z. Ma, Y. Liu, X. Liu, J. Liu, J. Ma, and K. Ren, “Learn to forget: Machine unlearning via neuron masking,” IEEE Transactions on Dependable and Secure Computing, 2022.
- J. Wang, S. Guo, X. Xie, and H. Qi, “Federated unlearning via class-discriminative pruning,” in Proceedings of the ACM Web Conference 2022, 2022, pp. 622–632.
- G. Liu, X. Ma, Y. Yang, C. Wang, and J. Liu, “Federaser: Enabling efficient client-level data removal from federated learning models,” in 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS). IEEE, 2021, pp. 1–10.
- Z. Liu, G. Dou, Y. Tian, C. Zhang, E. Chien, and Z. Zhu, “Breaking the trilemma of privacy, utility, efficiency via controllable machine unlearning,” arXiv preprint arXiv:2310.18574, 2023.
- A. Alag, Y. Huang, and K. Li, “Is ema robust? examining the robustness of data auditing and a novel non-calibration extension,” in NeurIPS 2023 Workshop on Regulatable ML, 2023.
- D. Ye, T. Zhu, C. Zhu, D. Wang, S. Shen, W. Zhou et al., “Reinforcement unlearning,” arXiv preprint arXiv:2312.15910, 2023.
- C. Wu, S. Zhu, and P. Mitra, “Federated unlearning with knowledge distillation. arxiv 2022,” arXiv preprint arXiv:2201.09441.
- Y. Guo, Y. Zhao, S. Hou, C. Wang, and X. Jia, “Verifying in the dark: Verifiable machine unlearning by using invisible backdoor triggers,” IEEE Transactions on Information Forensics and Security, 2023.
- M. Pawelczyk, S. Neel, and H. Lakkaraju, “In-context unlearning: Language models as few shot unlearners,” arXiv preprint arXiv:2310.07579, 2023.
- A. Halimi, S. R. Kadhe, A. Rawat, and N. B. Angel, “Federated unlearning: How to efficiently erase a client in fl?” in International Conference on Machine Learning, 2022.
- Y. Li, C. Chen, X. Zheng, and J. Zhang, “Federated unlearning via active forgetting,” arXiv preprint arXiv:2307.03363, 2023.
- Y. Zhang, J. Jia, X. Chen, A. Chen, Y. Zhang, J. Liu, K. Ding, and S. Liu, “To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images… for now,” arXiv preprint arXiv:2310.11868, 2023.
- S. Goel, A. Prabhu, A. Sanyal, S.-N. Lim, P. Torr, and P. Kumaraguru, “Towards adversarial evaluations for inexact machine unlearning,” arXiv preprint arXiv:2201.06640, 2022.
- P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy-preserving machine learning,” in 2017 IEEE symposium on security and privacy (SP). IEEE, 2017, pp. 19–38.
- Z. Liu, J. Guo, K.-Y. Lam, and J. Zhao, “Efficient dropout-resilient aggregation for privacy-preserving machine learning,” IEEE Transactions on Information Forensics and Security, vol. 18, pp. 1839–1854, 2022.
- Z. Liu, J. Guo, W. Yang, J. Fan, K.-Y. Lam, and J. Zhao, “Privacy-preserving aggregation in federated learning: A survey,” IEEE Transactions on Big Data, 2022.
- K.-Y. Lam, X. Lu, L. Zhang, X. Wang, H. Wang, and S. Q. Goh, “Efficient fhe-based privacy-enhanced neural network for trustworthy ai-as-a-service,” IEEE Transactions on Dependable and Secure Computing, 2024.
- Z. Liu, J. Guo, W. Yang, J. Fan, K.-Y. Lam, and J. Zhao, “Dynamic user clustering for efficient and privacy-preserving federated learning,” IEEE Transactions on Dependable and Secure Computing, 2024.
- Z. Liu, H.-Y. Lin, and Y. Liu, “Long-term privacy-preserving aggregation with user-dynamics for federated learning,” IEEE Transactions on Information Forensics and Security, 2023.
- S. Wagh, D. Gupta, and N. Chandran, “Securenn: 3-party secure computation for neural network training,” Proceedings on Privacy Enhancing Technologies, 2019.
- S. Pan, L. Luo, Y. Wang, C. Chen, J. Wang, and X. Wu, “Unifying large language models and knowledge graphs: A roadmap,” IEEE Transactions on Knowledge and Data Engineering, 2024.
- C. Chen, Y. Wang, Y. Zhang, Q. Z. Sheng, and K.-Y. Lam, “Separate-and-aggregate: A transformer-based patch refinement model for knowledge graph completion,” in International Conference on Advanced Data Mining and Applications. Springer, 2023, pp. 62–77.
- E. Kasneci, K. Seßler, S. Küchemann, M. Bannert, D. Dementieva, F. Fischer, U. Gasser, G. Groh, S. Günnemann, E. Hüllermeier et al., “Chatgpt for good? on opportunities and challenges of large language models for education,” Learning and individual differences, vol. 103, p. 102274, 2023.
- C. Chen, Y. Wang, A. Sun, B. Li, and K.-Y. Lam, “Dipping plms sauce: Bridging structure and text for effective knowledge graph completion via conditional soft prompting,” arXiv preprint arXiv:2307.01709, 2023.
- A. J. Thirunavukarasu, D. S. J. Ting, K. Elangovan, L. Gutierrez, T. F. Tan, and D. S. W. Ting, “Large language models in medicine,” Nature medicine, vol. 29, no. 8, pp. 1930–1940, 2023.
- C. Chen, Y. Wang, B. Li, and K.-Y. Lam, “Knowledge is flat: A seq2seq generative framework for various knowledge graph completion,” arXiv preprint arXiv:2209.07299, 2022.
- G. Deng, Y. Liu, Y. Li, K. Wang, Y. Zhang, Z. Li, H. Wang, T. Zhang, and Y. Liu, “Masterkey: Automated jailbreaking of large language model chatbots,” in Proc. ISOC NDSS, 2024.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

