Uncertainty quantification in fine-tuned LLMs using LoRA ensembles
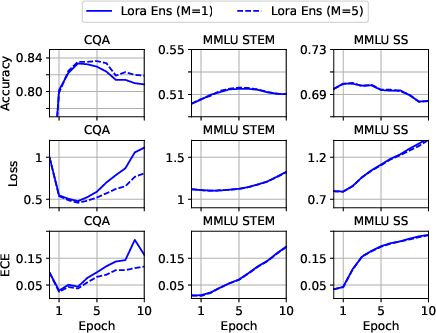
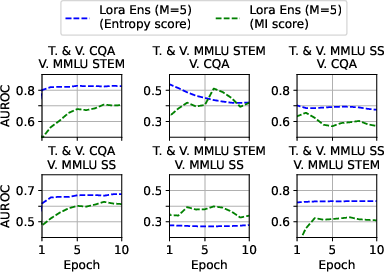
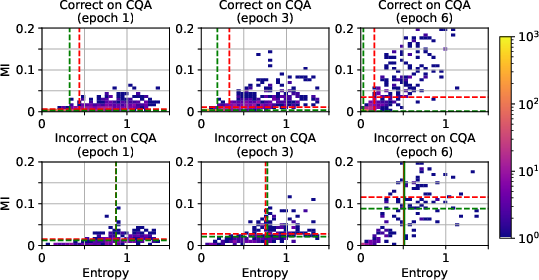
Abstract: Fine-tuning LLMs can improve task specific performance, although a general understanding of what the fine-tuned model has learned, forgotten and how to trust its predictions is still missing. We derive principled uncertainty quantification for fine-tuned LLMs with posterior approximations using computationally efficient low-rank adaptation ensembles. We analyze three common multiple-choice datasets using low-rank adaptation ensembles based on Mistral-7b, and draw quantitative and qualitative conclusions on their perceived complexity and balance between retained prior knowledge and domain specific adaptation during and after fine-tuning. We identify unexpected retention of acquired knowledge during fine-tuning in the overfitting regime.
- Intrinsic dimensionality explains the effectiveness of language model fine-tuning, 2020.
- Deep kernel processes. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 130–140. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/aitchison21a.html.
- github.com/oleksandr-balabanov/equivariant-posteriors/commit/38d5fb2817e43fa79cc8e4ddd3782fb4d7fb3ff2, 2024.
- Bayesian posterior approximation with stochastic ensembles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 13701–13711, June 2023.
- Ensemble learning in bayesian neural networks. 1998.
- Weight uncertainty in neural networks. In Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, pp. 1613–1622. JMLR.org, 2015.
- Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv preprint arXiv:2303.12712, 2023.
- Bayesian back-propagation. Complex Syst., 5, 1991.
- Quantifying uncertainty in answers from any language model and enhancing their trustworthiness, 2023.
- Calibrating transformers via sparse gaussian processes, 2024.
- Pathologies in priors and inference for bayesian transformers, 2021.
- Large automatic learning, rule extraction, and generalization. Complex Syst., 1, 1987.
- Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models, 2022.
- Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence, 5(3):220–235, Mar 2023. ISSN 2522-5839. doi: 10.1038/s42256-023-00626-4. URL https://doi.org/10.1038/s42256-023-00626-4.
- Shifting attention to relevance: Towards the uncertainty estimation of large language models, 2023.
- Ensembles for Uncertainty Estimation: Benefits of Prior Functions and Bootstrapping. arXiv e-prints, art. arXiv:2206.03633, June 2022.
- Bayesian attention modules. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 16362–16376. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/bcff3f632fd16ff099a49c2f0932b47a-Paper.pdf.
- Deep Ensembles: A Loss Landscape Perspective. arXiv e-prints, art. arXiv:1912.02757, December 2019.
- Bayesian neural network priors revisited, 2022.
- Bayesian Convolutional Neural Networks with Bernoulli Approximate Variational Inference. arXiv e-prints, art. arXiv:1506.02158, June 2015.
- Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In Balcan, M. F. and Weinberger, K. Q. (eds.), Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp. 1050–1059, New York, New York, USA, 20–22 Jun 2016. PMLR. URL https://proceedings.mlr.press/v48/gal16.html.
- A Survey of Uncertainty in Deep Neural Networks. arXiv e-prints, art. arXiv:2107.03342, July 2021.
- Uncertainty estimation for language reward models, 2022.
- Graves, A. Practical variational inference for neural networks. In Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., and Weinberger, K. (eds.), Advances in Neural Information Processing Systems, volume 24. Curran Associates, Inc., 2011. URL https://proceedings.neurips.cc/paper/2011/file/7eb3c8be3d411e8ebfab08eba5f49632-Paper.pdf.
- Evaluating Scalable Bayesian Deep Learning Methods for Robust Computer Vision. arXiv e-prints, art. arXiv:1906.01620, June 2019.
- Preserving pre-trained features helps calibrate fine-tuned language models, 2023.
- Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, 2015.
- A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136, 2016.
- Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- Deep Ensembles from a Bayesian Perspective. arXiv e-prints, art. arXiv:2105.13283, May 2021.
- Decomposing uncertainty for large language models through input clarification ensembling, 2023.
- Bayesian active learning for classification and preference learning. CoRR, abs/1112.5745, 2011. URL http://dblp.uni-trier.de/db/journals/corr/corr1112.html#abs-1112-5745.
- Parameter-efficient transfer learning for NLP. In Chaudhuri, K. and Salakhutdinov, R. (eds.), Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pp. 2790–2799. PMLR, 09–15 Jun 2019. URL https://proceedings.mlr.press/v97/houlsby19a.html.
- Lora: Low-rank adaptation of large language models. ICL2022, 2021.
- Look Before You Leap: An Exploratory Study of Uncertainty Measurement for Large Language Models, October 2023. URL http://arxiv.org/abs/2307.10236. arXiv:2307.10236 [cs].
- Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
- How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9:962–977, 2021. doi: 10.1162/tacl˙a˙00407. URL https://aclanthology.org/2021.tacl-1.57.
- Being bayesian, even just a bit, fixes overconfidence in relu networks, 2020.
- Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation, April 2023. URL http://arxiv.org/abs/2302.09664. arXiv:2302.09664 [cs].
- Measuring the intrinsic dimension of objective landscapes, 2018.
- Teaching Models to Express Their Uncertainty in Words. arXiv e-prints, art. arXiv:2205.14334, May 2022. doi: 10.48550/arXiv.2205.14334.
- Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models. arXiv e-prints, art. arXiv:2305.19187, May 2023. doi: 10.48550/arXiv.2305.19187.
- Looking at the posterior: accuracy and uncertainty of neural-network predictions. Machine Learning: Science and Technology, 4(4):045032, 2023.
- Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning, 2022.
- Roberta: A robustly optimized bert pretraining approach, 2019.
- MacKay, D. Bayesian model comparison and backprop nets. In Moody, J., Hanson, S., and Lippmann, R. (eds.), Advances in Neural Information Processing Systems, volume 4. Morgan-Kaufmann, 1991. URL https://proceedings.neurips.cc/paper/1991/file/c3c59e5f8b3e9753913f4d435b53c308-Paper.pdf.
- Mackay, D. J. C. Information-based objective functions for active data selection. Neural Computation, 4(2):550–604, 1992.
- Predictive uncertainty estimation via prior networks, 2018.
- Uncertainty Estimation in Autoregressive Structured Prediction, February 2021. URL http://arxiv.org/abs/2002.07650. arXiv:2002.07650 [cs, stat].
- Uncertainty in gradient boosting via ensembles, 2021.
- Peft: State-of-the-art parameter-efficient fine-tuning methods. https://github.com/huggingface/peft, 2022.
- Reducing conversational agents’ overconfidence through linguistic calibration. Transactions of the Association for Computational Linguistics, 10:857–872, 2022. doi: 10.1162/tacl˙a˙00494. URL https://aclanthology.org/2022.tacl-1.50.
- Global inducing point variational posteriors for bayesian neural networks and deep gaussian processes. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 8248–8259. PMLR, 18–24 Jul 2021. URL https://proceedings.mlr.press/v139/ober21a.html.
- Gpt-4 technical report, 2023.
- Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 35:27730–27744, 2022.
- Can you trust your model's uncertainty? evaluating predictive uncertainty under dataset shift. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019a. URL https://proceedings.neurips.cc/paper/2019/file/8558cb408c1d76621371888657d2eb1d-Paper.pdf.
- Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift, 2019b.
- Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- Out-of-Distribution Detection and Selective Generation for Conditional Language Models, March 2023. URL http://arxiv.org/abs/2209.15558. arXiv:2209.15558 [cs].
- Dept: Decomposed prompt tuning for parameter-efficient fine-tuning, 2024.
- Quantifying uncertainty in foundation models via ensembles. In NeurIPS 2022 Workshop on Robustness in Sequence Modeling, 2022. URL https://openreview.net/forum?id=LpBlkATV24M.
- CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/v1/N19-1421. URL https://aclanthology.org/N19-1421.
- Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback, 2023.
- Consistent inference of probabilities in layered networks: predictions and generalizations. In International 1989 Joint Conference on Neural Networks, pp. 403–409 vol.2, 1989. doi: 10.1109/IJCNN.1989.118274.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Bayesian layers: A module for neural network uncertainty. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/paper_files/paper/2019/file/154ff8944e6eac05d0675c95b5b8889d-Paper.pdf.
- Plex: Towards reliability using pretrained large model extensions, 2022.
- Lora ensembles for large language model fine-tuning, 2023.
- Batchensemble: An alternative approach to efficient ensemble and lifelong learning, 2020.
- Bayesian deep learning and a probabilistic perspective of generalization. Advances in neural information processing systems, 33:4697–4708, 2020.
- Quantifying aleatoric and epistemic uncertainty in machine learning: Are conditional entropy and mutual information appropriate measures? In Uncertainty in Artificial Intelligence, pp. 2282–2292. PMLR, 2023.
- Uncertainty quantification with pre-trained language models: A large-scale empirical analysis. In Goldberg, Y., Kozareva, Z., and Zhang, Y. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2022, pp. 7273–7284, Abu Dhabi, United Arab Emirates, December 2022a. Association for Computational Linguistics. doi: 10.18653/v1/2022.findings-emnlp.538. URL https://aclanthology.org/2022.findings-emnlp.538.
- Uncertainty quantification with pre-trained language models: A large-scale empirical analysis, 2022b.
- Bayesian transformer language models for speech recognition. pp. 7378–7382, 06 2021. doi: 10.1109/ICASSP39728.2021.9414046.
- Bayesian low-rank adaptation for large language models, 2024.
- Uncertainty-penalized reinforcement learning from human feedback with diverse reward lora ensembles, 2023.
- mixup: Beyond empirical risk minimization, 2018.
- Cyclical stochastic gradient mcmc for bayesian deep learning, 2020.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv preprint arXiv:2303.16199, 2023.
- Bayesian attention belief networks, 2021.
- Adapting language models for zero-shot learning by meta-tuning on dataset and prompt collections. arXiv preprint arXiv:2104.04670, 2021.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

