Extending LLMs' Context Window with 100 Samples
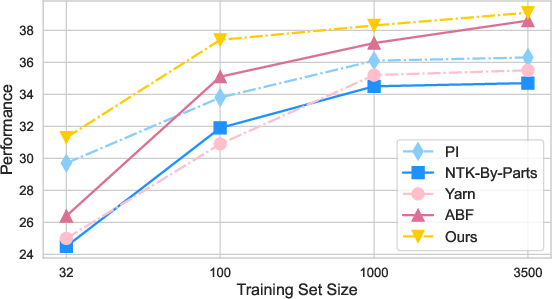
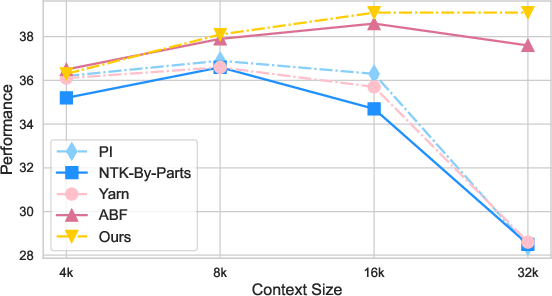
Abstract: LLMs are known to have limited extrapolation ability beyond their pre-trained context window, constraining their application in downstream tasks with lengthy inputs. Recent studies have sought to extend LLMs' context window by modifying rotary position embedding (RoPE), a popular position encoding method adopted by well-known LLMs such as LLaMA, PaLM, and GPT-NeoX. However, prior works like Position Interpolation (PI) and YaRN are resource-intensive and lack comparative experiments to assess their applicability. In this work, we identify the inherent need for LLMs' attention entropy (i.e. the information entropy of attention scores) to maintain stability and introduce a novel extension to RoPE which combines adjusting RoPE's base frequency and scaling the attention logits to help LLMs efficiently adapt to a larger context window. We validate the superiority of our method in both fine-tuning performance and robustness across different context window sizes on various context-demanding tasks. Notably, our method extends the context window of LLaMA-2-7B-Chat to 16,384 with only 100 samples and 6 training steps, showcasing extraordinary efficiency. Finally, we also explore how data compositions and training curricula affect context window extension for specific downstream tasks, suggesting fine-tuning LLMs with lengthy conversations as a good starting point. We release our code and SFT data at https://github.com/GAIR-NLP/Entropy-ABF.
- Gqa: Training generalized multi-query transformer models from multi-head checkpoints. arXiv preprint arXiv:2305.13245.
- Etc: Encoding long and structured inputs in transformers. arXiv preprint arXiv:2004.08483.
- Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Longbench: A bilingual, multitask benchmark for long context understanding. arXiv preprint arXiv:2308.14508.
- Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150.
- Gpt-neox-20b: An open-source autoregressive language model. arXiv preprint arXiv:2204.06745.
- bloc97. 2023a. Add NTK-Aware interpolation "by parts" correction.
- bloc97. 2023b. NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Scaling transformer to 1m tokens and beyond with rmt. arXiv preprint arXiv:2304.11062.
- Extending context window of large language models via positional interpolation. arXiv preprint arXiv:2306.15595.
- Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174.
- David Chiang and Peter Cholak. 2022. Overcoming a theoretical limitation of self-attention. arXiv preprint arXiv:2202.12172.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509.
- Rethinking attention with performers. arXiv preprint arXiv:2009.14794.
- Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113.
- Tri Dao. 2023. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691.
- Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359.
- Longnet: Scaling transformers to 1,000,000,000 tokens. arXiv preprint arXiv:2307.02486.
- How abilities in large language models are affected by supervised fine-tuning data composition. arXiv preprint arXiv:2310.05492.
- The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027.
- Convolutional sequence to sequence learning. In International conference on machine learning, pages 1243–1252. PMLR.
- Retrieval augmented language model pre-training. In International conference on machine learning, pages 3929–3938. PMLR.
- Efficient attentions for long document summarization. arXiv preprint arXiv:2104.02112.
- kaiokendev. 2023. Things I’m learning while training superhot.
- Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pages 5156–5165. PMLR.
- The impact of positional encoding on length generalization in transformers. arXiv preprint arXiv:2305.19466.
- Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451.
- Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- How long can open-source llms truly promise on context length?
- Repobench: Benchmarking repository-level code auto-completion systems. arXiv preprint arXiv:2306.03091.
- Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. Learning,Learning.
- Amirkeivan Mohtashami and Martin Jaggi. 2023. Landmark attention: Random-access infinite context length for transformers. arXiv preprint arXiv:2305.16300.
- Giraffe: Adventures in expanding context lengths in llms. arXiv preprint arXiv:2308.10882.
- Yarn: Efficient context window extension of large language models. arXiv preprint arXiv:2309.00071.
- Train short, test long: Attention with linear biases enables input length extrapolation. arXiv preprint arXiv:2108.12409.
- Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
- Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE.
- Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506.
- {{\{{ZeRO-Offload}}\}}: Democratizing {{\{{Billion-Scale}}\}} model training. In 2021 USENIX Annual Technical Conference (USENIX ATC 21), pages 551–564.
- Self-attention with relative position representations. arXiv preprint arXiv:1803.02155.
- Noam Shazeer. 2019. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150.
- Jianlin Su. 2023. Rectified rotary position embeddings. https://github.com/bojone/rerope.
- Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864.
- Do long-range language models actually use long-range context? arXiv: Computation and Language,arXiv: Computation and Language.
- A length-extrapolatable transformer. arXiv preprint arXiv:2212.10554.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Focused transformer: Contrastive training for context scaling. arXiv preprint arXiv:2307.03170.
- Attention is all you need. Advances in neural information processing systems, 30.
- Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768.
- Memorizing transformers. arXiv preprint arXiv:2203.08913.
- Effective long-context scaling of foundation models. arXiv preprint arXiv:2309.16039.
- Bp-transformer: Modelling long-range context via binary partitioning. arXiv: Computation and Language,arXiv: Computation and Language.
- Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33:17283–17297.
- Judging llm-as-a-judge with mt-bench and chatbot arena.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.