Learning to Localize Objects Improves Spatial Reasoning in Visual-LLMs
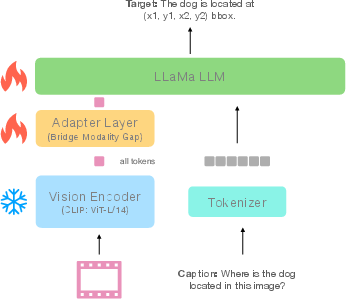
Abstract: Integration of LLMs into visual domain tasks, resulting in visual-LLMs (V-LLMs), has enabled exceptional performance in vision-language tasks, particularly for visual question answering (VQA). However, existing V-LLMs (e.g. BLIP-2, LLaVA) demonstrate weak spatial reasoning and localization awareness. Despite generating highly descriptive and elaborate textual answers, these models fail at simple tasks like distinguishing a left vs right location. In this work, we explore how image-space coordinate based instruction fine-tuning objectives could inject spatial awareness into V-LLMs. We discover optimal coordinate representations, data-efficient instruction fine-tuning objectives, and pseudo-data generation strategies that lead to improved spatial awareness in V-LLMs. Additionally, our resulting model improves VQA across image and video domains, reduces undesired hallucination, and generates better contextual object descriptions. Experiments across 5 vision-language tasks involving 14 different datasets establish the clear performance improvements achieved by our proposed framework.
- Human activity analysis. ACM Computing Surveys (CSUR), 43:1 – 43, 2011.
- Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198, 2022.
- Openflamingo, 2023.
- Pratyay Banerjee et al. Weakly supervised relative spatial reasoning for visual question answering. ICCV, 2021.
- Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- End-to-end object detection with transformers. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I 16, pages 213–229. Springer, 2020.
- Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3557–3567, 2021.
- Shikra: Unleashing multimodal llm’s referential dialogue magic. arXiv preprint arXiv:2306.15195, 2023.
- Diffusiondet: Diffusion model for object detection. arXiv preprint arXiv:2211.09788, 2022.
- Pix2seq: A language modeling framework for object detection. arXiv preprint arXiv:2109.10852, 2021.
- Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, 2023.
- Jaemin Cho et al. Dall-eval: Probing the reasoning skills and social biases of text-to-image generation models. ICCV, 2023.
- Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- Democratizing contrastive language-image pre-training: A clip benchmark of data, model, and supervision. arXiv preprint arXiv:2203.05796, 2022.
- Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500, 2023.
- Decoupling zero-shot semantic segmentation. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11573–11582, 2021.
- Coarse-to-fine vision-language pre-training with fusion in the backbone. ArXiv, abs/2206.07643, 2022.
- Open-vocabulary image segmentation. In ECCV, 2022.
- Ross Girshick. Fast r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 1440–1448, 2015.
- Gokhale et al. Benchmarking spatial relationships in text-to-image generation, 2022.
- Zero-shot detection via vision and language knowledge distillation. arXiv e-prints, pages arXiv–2104, 2021.
- Visual programming: Compositional visual reasoning without training. 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14953–14962, 2022.
- Activitynet: A large-scale video benchmark for human activity understanding. 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 961–970, 2015.
- Joy Hsu et al. What’s left? concept grounding with logic-enhanced foundation models. NeurIPS, 2023.
- Gqa: A new dataset for real-world visual reasoning and compositional question answering. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6693–6702, 2019.
- Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning, 2021.
- Mdetr-modulated detection for end-to-end multi-modal understanding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1780–1790, 2021.
- Amita Kamath et al. What’s ”up” with vision-language models? investigating their struggle with spatial reasoning. EMNLP, 2023.
- Referitgame: Referring to objects in photographs of natural scenes. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 787–798, 2014.
- Lisa: Reasoning segmentation via large language model. arXiv preprint arXiv:2308.00692, 2023.
- Language-driven semantic segmentation. ICLR, 2022a.
- Adapting clip for phrase localization without further training. ArXiv, abs/2204.03647, 2022b.
- Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023a.
- Videochat: Chat-centric video understanding. arXiv preprint arXiv:2305.06355, 2023b.
- Grounded language-image pre-training. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10955–10965, 2021.
- Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355, 2023c.
- Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Visual instruction tuning. arXiv preprint arXiv:2304.08485, 2023.
- Segclip: Patch aggregation with learnable centers for open-vocabulary semantic segmentation. ArXiv, abs/2211.14813, 2022.
- Jitendra Malik. Visual grouping and object recognition. In Proceedings 11th International Conference on Image Analysis and Processing, pages 612–621. IEEE, 2001.
- David Marr. Vision: A computational investigation into the human representation and processing of visual information. MIT press, 1982.
- Salman Khan Muhammad Maaz, Hanoona Rasheed and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. ArXiv 2306.05424, 2023.
- Open vocabulary semantic segmentation with patch aligned contrastive learning. CVPR, abs/2212.04994, 2023.
- OpenAI. GPT-4 technical report. https://arxiv.org/abs/2303.08774, 2023.
- Kosmos-2: Grounding multimodal large language models to the world. arXiv preprint arXiv:2306.14824, 2023.
- Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Language-based action concept spaces improve video self-supervised learning. In NeurIPS, 2023.
- Perceptual grouping in contrastive vision-language models. In ICCV, 2023.
- Understanding long videos in one multimodal language model pass, 2024.
- You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016.
- Recognition of composite human activities through context-free grammar based representation. 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), 2:1709–1718, 2006.
- Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100, 2022.
- Vipergpt: Visual inference via python execution for reasoning. ArXiv, abs/2303.08128, 2023.
- Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF international conference on computer vision, pages 9627–9636, 2019.
- Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023a.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023b.
- Selective search for object recognition. IJCV, 104(2):154–171, 2013.
- Visionllm: Large language model is also an open-ended decoder for vision-centric tasks. arXiv preprint arXiv:2305.11175, 2023.
- Finetuned language models are zero-shot learners. ArXiv, abs/2109.01652, 2021.
- Groupvit: Semantic segmentation emerges from text supervision. CVPR, 2022.
- Learning open-vocabulary semantic segmentation models from natural language supervision. ArXiv, abs/2301.09121, 2023.
- Videococa: Video-text modeling with zero-shot transfer from contrastive captioners. arXiv, 2022.
- Just ask: Learning to answer questions from millions of narrated videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1686–1697, 2021.
- Zero-shot video question answering via frozen bidirectional language models. arXiv preprint arXiv:2206.08155, 2022.
- FILIP: Fine-grained interactive language-image pre-training. In ICLR, 2022.
- Ferret: Refer and ground anything anywhere at any granularity. ArXiv, abs/2310.07704, 2023.
- A joint speaker-listener-reinforcer model for referring expressions. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3521–3529, 2016.
- Contextual object detection with multimodal large language models. arXiv preprint arXiv:2305.18279, 2023.
- Multi-grained vision language pre-training: Aligning texts with visual concepts. ArXiv, abs/2111.08276, 2021.
- Glipv2: Unifying localization and vision-language understanding. ArXiv, abs/2206.05836, 2022.
- Video-llama: An instruction-tuned audio-visual language model for video understanding. ArXiv, abs/2306.02858, 2023a.
- Llama-adapter: Efficient fine-tuning of language models with zero-init attention. ArXiv, abs/2303.16199, 2023b.
- Gpt4roi: Instruction tuning large language model on region-of-interest. arXiv preprint arXiv:2307.03601, 2023c.
- Associating spatially-consistent grouping with text-supervised semantic segmentation. ArXiv, abs/2304.01114, 2023d.
- Bubogpt: Enabling visual grounding in multi-modal llms. arXiv preprint arXiv:2307.08581, 2023.
- Extract free dense labels from clip. In European Conference on Computer Vision, 2021.
- Segment everything everywhere all at once. In NeurIPS, 2023.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

