- The paper introduces Activation Addition (ActAdd) as an innovative method to steer LLM outputs without the need for further training or labeled data.
- It computes a 'steering vector' from activation differences between contrasting prompts, allowing real-time control over sentiment, topic, and style.
- Experimental results on models like GPT-2-XL, Llama-13B, and GPT-J-6B demonstrate effective and scalable manipulation with minimal performance impact.
Steering LLMs with Activation Engineering
Introduction
The paper "Steering LLMs With Activation Engineering" (2308.10248) introduces Activation Addition (ActAdd), a novel method for controlling LLMs via activation engineering, contrasting traditional methods such as supervised finetuning, reinforcement learning from human feedback, and prompt engineering. ActAdd manipulates LLM activations at inference time, allowing control over high-level properties like sentiment, topic, and style, optimizing neither further training nor requiring labeled data.
Methods
ActAdd computes a 'steering vector' by leveraging the activation differences between prompt pairs (e.g., "love" vs. "hate"), facilitating model output manipulation without backward passes. This steering vector is applied during the forward pass, influencing the model in real-time without modifying weights or relying on large datasets.
The method relies on selecting activation differences from specific layers, controlled by an injection coefficient and target layer parameter, adjusted via grid search. The paper also reports on the natural-language control achieved over models like GPT-2-XL and scalable performance in larger models like Llama-13B and GPT-J-6B.
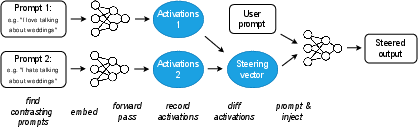
Figure 1: Schematic of the Activation Addition\, (ActAdd) method. \oblong[] = natural language text; {\huge\color{activationcolor}.
Experimental Results
The experiments demonstrate ActAdd's efficacy by steering model outputs to focus on certain topics or styles, such as increasing wedding-related completions or altering sentiment. The experiments were conducted extensively using datasets like OpenWebText and ConceptNet benchmarks to validate both the effectiveness and the preservation of general performance.
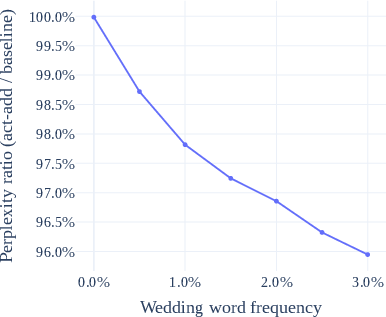
Figure 2: Performance of ActAdd\, on a target topic as the topic becomes more relevant. The perplexity ratio (lower better) compares the relative predictive performance of {ActAdd}.
Llama-13B and GPT-J replication established the method's scalability, showing consistent results often with less computation than alternatives. Detailed experimentation in the paper highlights ActAdd preserving off-target performance, with negligible mean token log-probability changes outside steering targets.
Implications and Future Work
ActAdd's minimal computational overhead offers pragmatic advantages for user-LLM interaction, overcoming traditional constraints associated with fine-tuning or extensive training. While current results establish the theoretical and practical utility of activation engineering, the paper notes limitations, such as the need for initial parameter tuning (contrasts, injection coefficients, layers), potentially impacting usability.
Future research could focus on refining selection mechanisms for parameters, scrutinizing ActAdd under more complex tasks, and exploring broader application on larger models. The investigation of non-natural language-based steering might also yield interesting findings, demonstrating ActAdd's robustness or limitations under different scenarios.
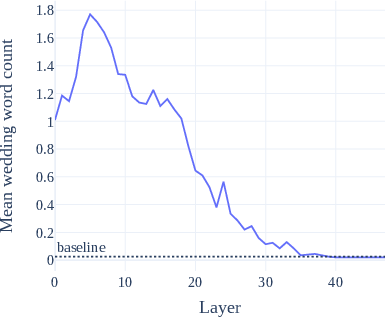
Figure 3: Topic steering effect (mean related words in completions) over injection layer. In blue is the average related-word count among 200 ActAdd\, completions; the dotted line is the count among unmodified completions.
Conclusion
Activation Addition stands as a promising approach to steering LLMs, combining efficiency, simplicity, and robust outcomes at scale. It represents an invaluable tool for aligning LLM outputs towards desired properties without extensive retraining, offering significant potential for advancing AI-alignment techniques by reducing the computational costs traditionally associated with model adaptation. Further inquiry into activation engineering could unveil nuanced control mechanisms within transformative architectures, fostering safer, more adaptable LLMs.