- The paper surveys rapid advancements in text-to-image diffusion models, outlining key improvements in image quality and text-image alignment.
- It compares pixel space techniques (GLIDE, Imagen) and latent space methods (Stable Diffusion, DALL-E2) to optimize computational efficiency.
- The paper addresses challenges like dataset biases and ethical concerns, proposing standard evaluations and methodological enhancements.
Text-to-Image Diffusion Models: Survey and Their Progress
The paper "Text-to-image Diffusion Models in Generative AI: A Survey" (2303.07909) provides a comprehensive examination of the surging interest and rapid advancements in applying diffusion models for generating images from textual descriptions. The survey introduces text-to-image diffusion models and discusses various innovative frameworks and methodologies designed to enhance their performance. The discussion extends beyond mere generation to consider improvements in computation efficiency, evaluation metrics, and practical applications of these generative models.
Evolution of Text-to-Image Diffusion Models
Initially, GAN-based and autoregressive models dominated text-to-image tasks, with methods leveraging massive datasets for training leading models like DALL-E and Parti. However, as these autoregressive models faced challenges related to computational cost and error accumulation, diffusion models emerged as a promising alternative due to their capacity for high-quality image synthesis.
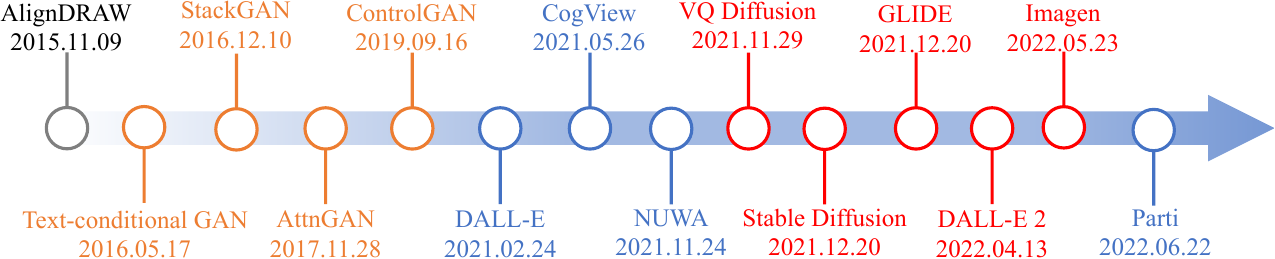
Figure 1: Representive works on text-to-image task over time. The GAN-based methods, autoregressive methods, and diffusion-based methods are masked in yellow, blue, and red, respectively.
Key Developments with Diffusion Models
Diffusion models offer a potent alternative due to their ability to unsettle complex probability distributions through a sequence of transformations and generate high-quality images. Denoising diffusion probabilistic models (DDPM) and new techniques like classifier-free guidance enhance the quality and diversity of generated images by allowing a refinement of image features without requiring an auxiliary classifier.
Pioneering Text-to-Image Frameworks
Pixel Space Approaches
GLIDE introduced classifier-free guidance, replacing traditional classifiers with textual input, facilitating a model's focus on textual prompts to generate photo-realistic images.
Imagen advanced this process by utilizing pre-trained LLMs, such as T5, resulting in improved text comprehension, leading to a significant leap in text-image alignment and image fidelity.




Figure 2: Images generated by GLIDE~\cite{nichol2021glide}.
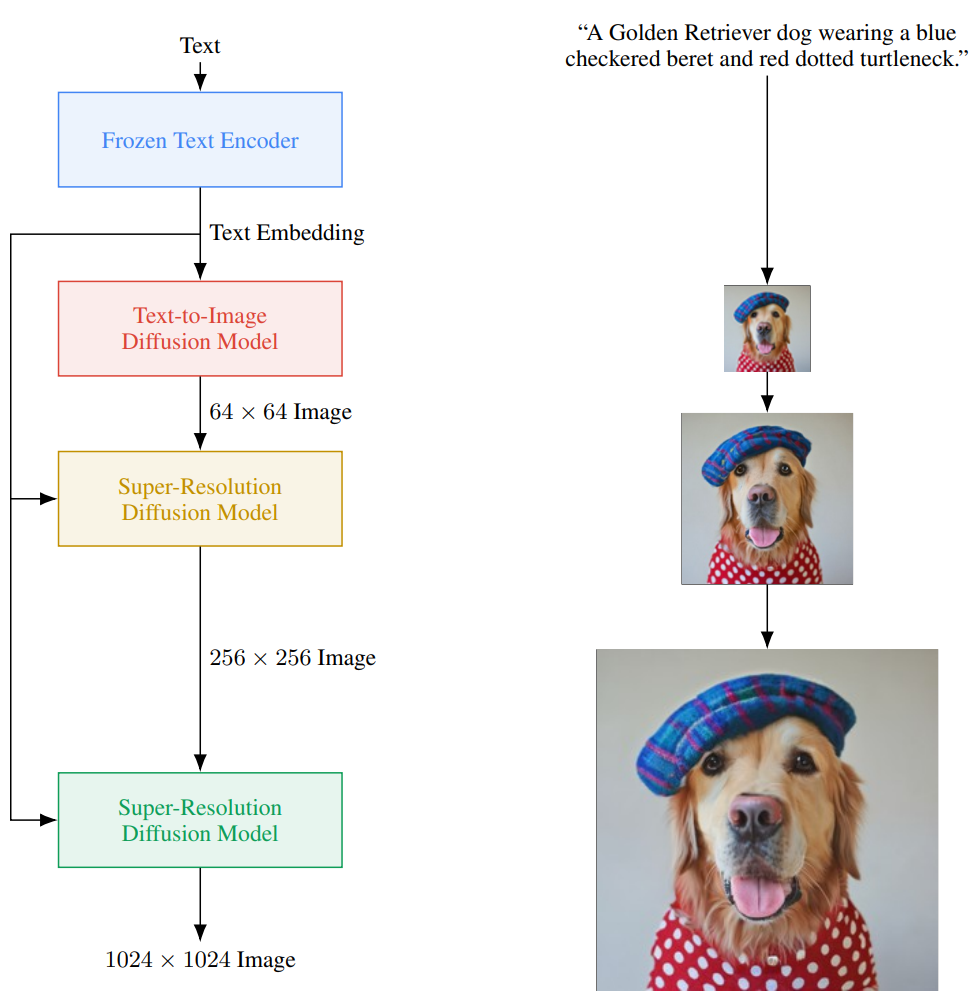
Figure 3: Model diagram from Imagen~\cite{saharia2022photorealistic}.
Latent Space Approaches
Stable Diffusion innovated by applying diffusion processes in latent spaces which results in reduced computational resources while maintaining image quality. It emphasizes cross-attention mechanisms to bind textual inputs with visual outputs efficiently.
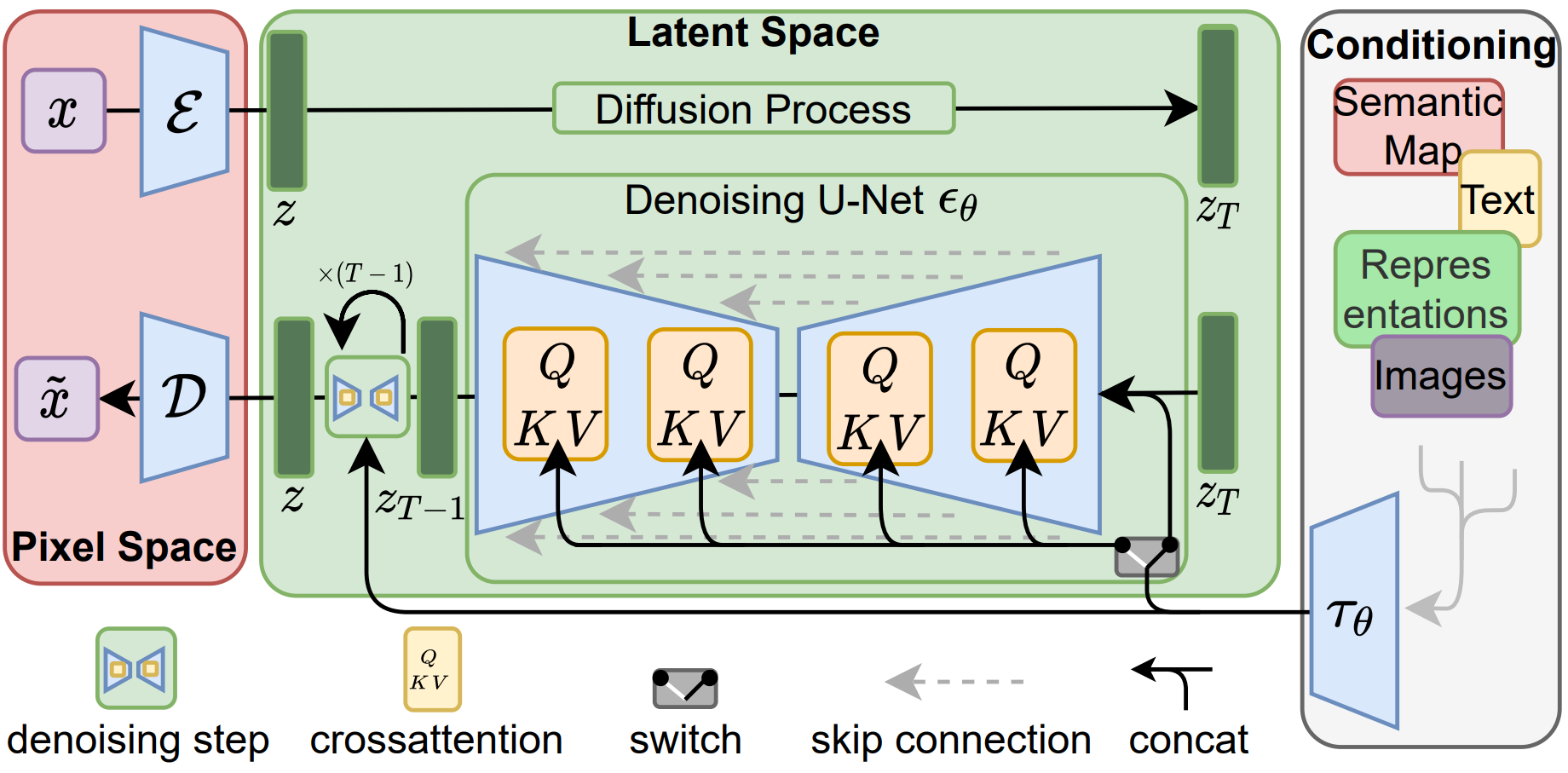
Figure 4: Overview of Stable Diffusion~\cite{rombach2022high}.
DALL-E2 leverages a multimodal latent space to bridge the gap between textual and visual data using CLIP embeddings, implementing a robust latent space translation.
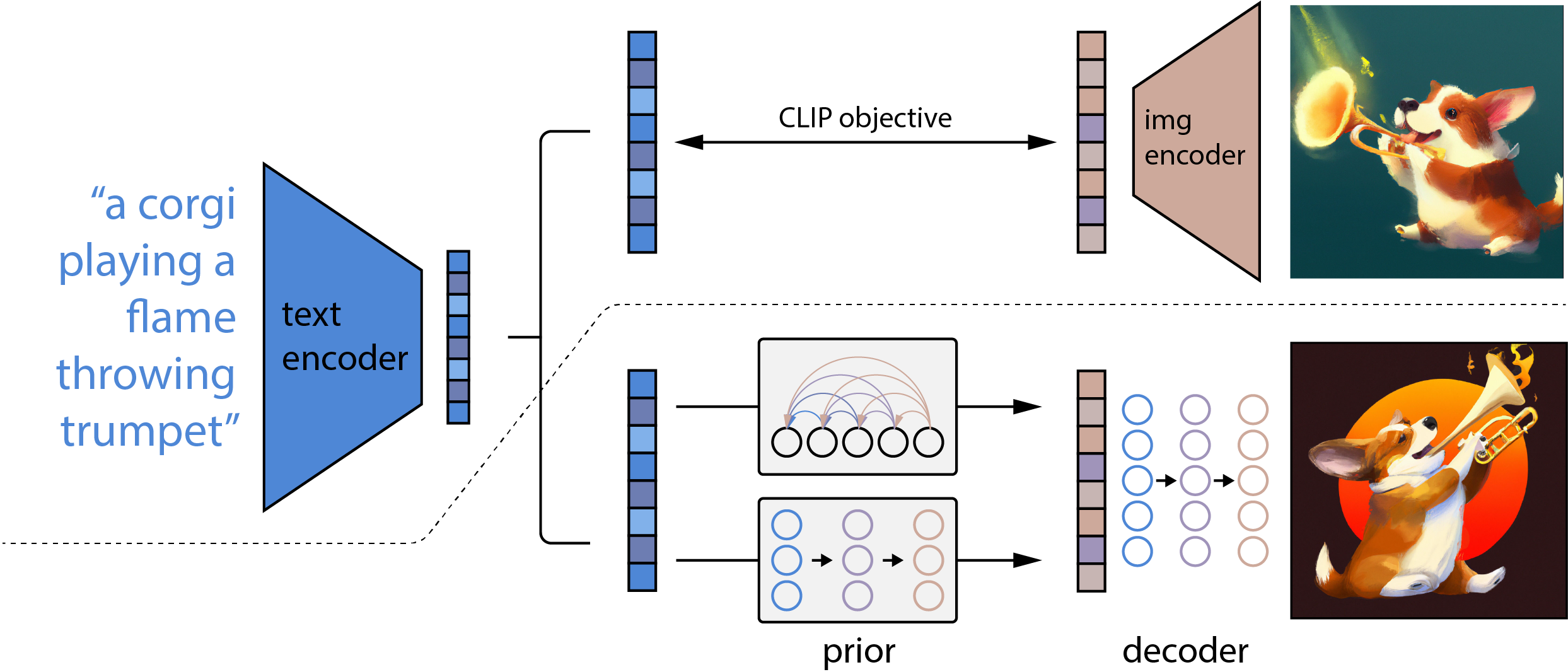
Figure 5: Overview of DALL-E2~\cite{ramesh2022hierarchical}.
Improving Text-to-Image Diffusion Models
Recent research has sought to refine various aspects of diffusion models, such as optimizing architectural designs, offering enhanced spatial control, and experimenting with textual inversion for better concept management. Methods like classifier-free guidance and adaptive model parameterization improve text alignment and image quality, pointing to continued innovation within architecture and algorithmic approaches.
Challenges and Considerations
Despite substantial progress, challenges persist, including dataset biases, computational costs, evaluation standards, and ethical implications surrounding misuse for malicious purposes. These issues necessitate ongoing refinement of both techniques and frameworks within ethical and practical boundaries.
Conclusion and Outlook
The paper anticipates further developments in boosting evaluation criteria, democratizing access to large models, and building unified multi-modality frameworks. The intertwining of text, image, and emerging AI paradigms promises to perpetuate the trajectory of innovative discoveries in generative AI. The insights provided by this survey indicate a rich landscape for future exploration and enhancement of text-to-image generation techniques.

