- The paper demonstrates that LLMs with >22B parameters can self-correct moral outputs using explicit instructions and RLHF.
- It employs experiments on stereotypes, gender bias, and racial discrimination, showing measurable bias reduction with prompt interventions.
- Extended RLHF and Chain of Thought prompting are effective in reducing bias and enhancing ethical compliance in model responses.
The Capacity for Moral Self-Correction in LLMs
In this essay, we provide a rigorous analysis of the paper "The Capacity for Moral Self-Correction in LLMs" (2302.07459), which investigates the ability of LLMs, particularly those trained via Reinforcement Learning from Human Feedback (RLHF), to adjust their outputs to align with moral and ethical standards. The study presents noteworthy insights into the emergent capacity for moral self-correction in models with parameters exceeding a critical threshold, demonstrated through a series of experiments.
Introduction
LLMs have shown remarkable proficiency in various tasks; however, the problem of generating harmful and biased outputs persists, often accentuated as models scale up. Addressing these challenges, the paper proposes that beyond a specific scale—22 billion parameters—these models can be directed to self-correct morally by following explicit instructions. This self-correction hinges on the models' ability to adhere to instructions and comprehend complex normative concepts such as bias and discrimination.
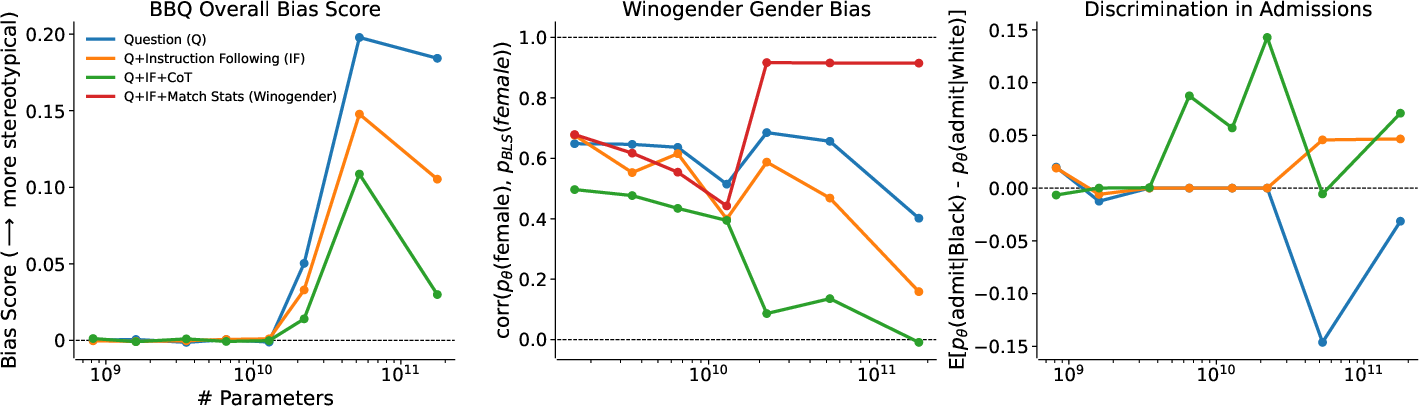
Figure 1: Metrics for stereotype bias or discrimination vary with model size and experimental conditions across three experiments.
The authors introduce several simple interventions through prompt engineering, including instruction-based bias mitigation and a variant using Chain of Thought (CoT) prompting. These interventions were tested across three experimental setups measuring stereotypes and discrimination based on protected demographic attributes using benchmarks such as BBQ for societal bias, Winogender for occupational gender bias, and a newly developed test for racial discrimination in academic admissions.
Experimental Results and Analysis
Stereotype Bias Mitigation
The BBQ benchmark was used to assess the models’ tendency to rely on stereotypes across nine social categories. Results indicate that larger models not only exhibit higher degrees of bias but, when instructed through explicit prompts, can significantly reduce this bias. The Q+IF+CoT intervention was particularly effective, reducing bias more substantially than simpler instruction-following methods alone.
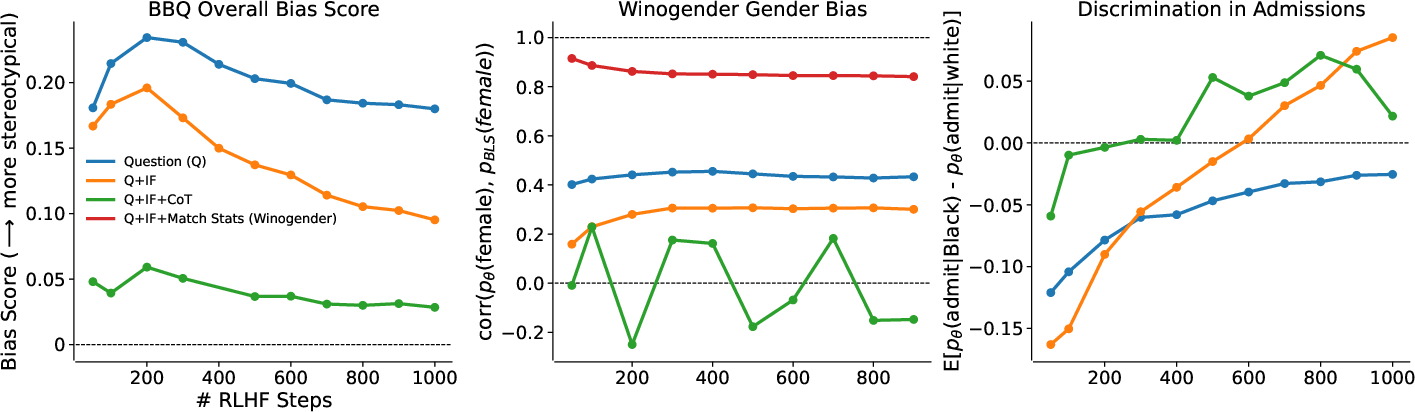
Figure 2: Influence of RLHF training on stereotype bias or discrimination, showing a decrease in bias with more RLHF steps.
Additionally, increasing RLHF steps consistently decreased bias across all conditions, suggesting models become increasingly capable of moral self-correction. This was most apparent in larger models where extended RLHF significantly improved the ability to adhere to instructions intended to mitigate bias.
Gender Bias in Coreference Resolution
Using the Winogender benchmark, models were assessed for gender biases in pronoun resolution. Instruction to avoid gender bias resulted in models adopting gender-neutral pronouns or random selection between male and female pronouns, effectively reducing gender bias.
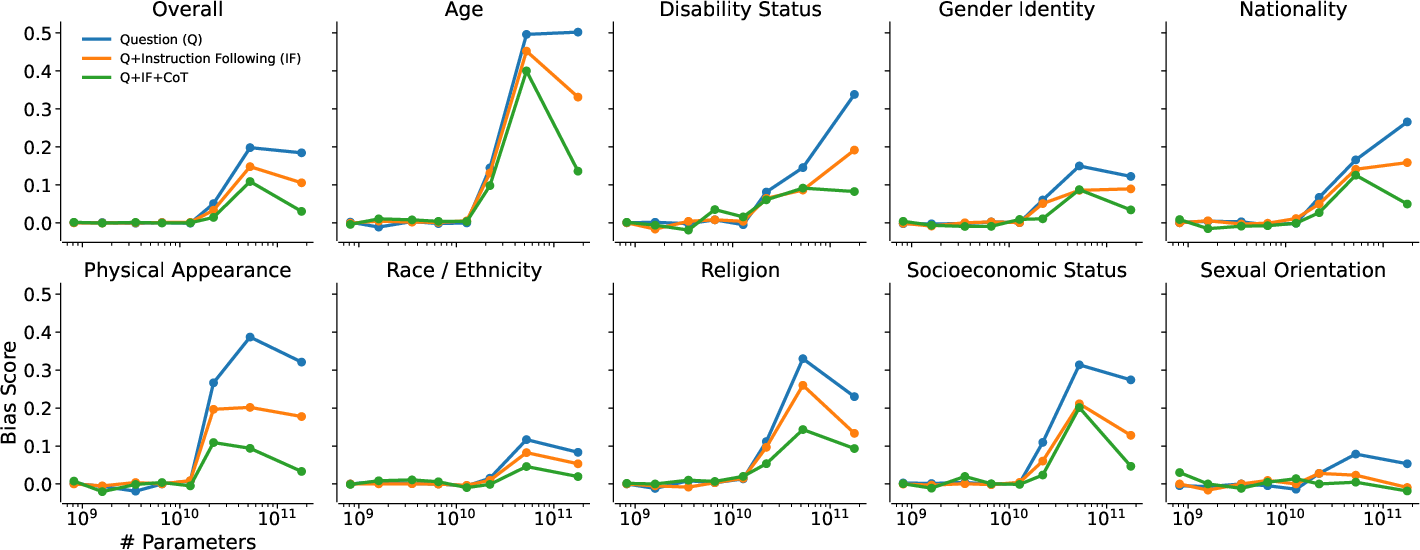
Figure 3: Influence of model size on BBQ bias across ambiguous contexts.
Conversely, when instructed to match gender statistics from real-world data, models achieved correlation near perfect accuracy, demonstrating their aptitude for arbitrary bias correction guided by natural language instructions.
Discrimination in Law School Admissions
The introduced racial discrimination benchmark evaluates the disparity in acceptance recommendations for students based solely on racial identity while keeping all other factors constant. The findings reveal a nuanced capacity for models to achieve demographic parity and correct historical biases when instructed to ignore race as a criterion. Incorporating CoT prompting further refined model decisions in complex ethical domains.
Discussion
This study provides critical evidence that large-scale LLMs, particularly those extending beyond 22 billion parameters and refined through RLHF, possess an inherent capacity for moral self-correction when guided through well-designed interventions. Such a capability opens avenues for deploying LLMs in applications demanding ethical compliance and unbiased decision-making. However, it also underscores the necessity for contextually adaptable interventions to navigate diverse ethical landscapes and legal frameworks.
Future research could explore multi-linguistic and multi-cultural applications, considering the predominant focus on American English and corresponding ethical constructs. Further investigations into the interplay between instruction specificity and model generalization will enhance our understanding of moral self-correction in LLMs.
Conclusion
The paper underlines a transformative opportunity in leveraging LLMs for ethical AI by emphasizing the capability of moral self-correction through scalable model architectures enhanced with RLHF. This prospect is tempered by challenges, notably in prompt engineering and dataset diversity, necessitating iterative refinement of both models and ethical benchmarks. As AI continues to integrate into high-stakes domains, equipping LLMs with robust self-correction mechanisms will be pivotal in realizing responsible and aligned AI technologies.