Learning Prototype Classifiers for Long-Tailed Recognition
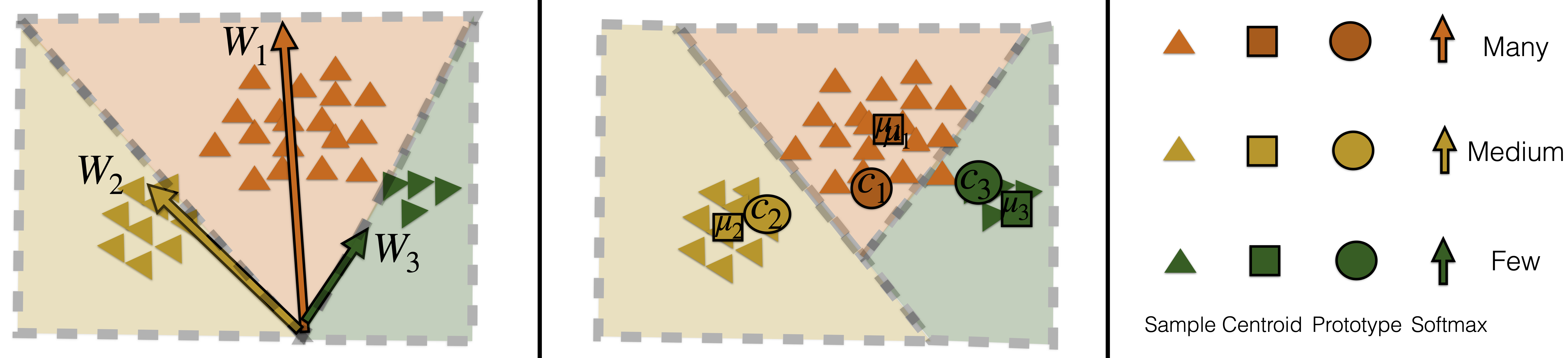
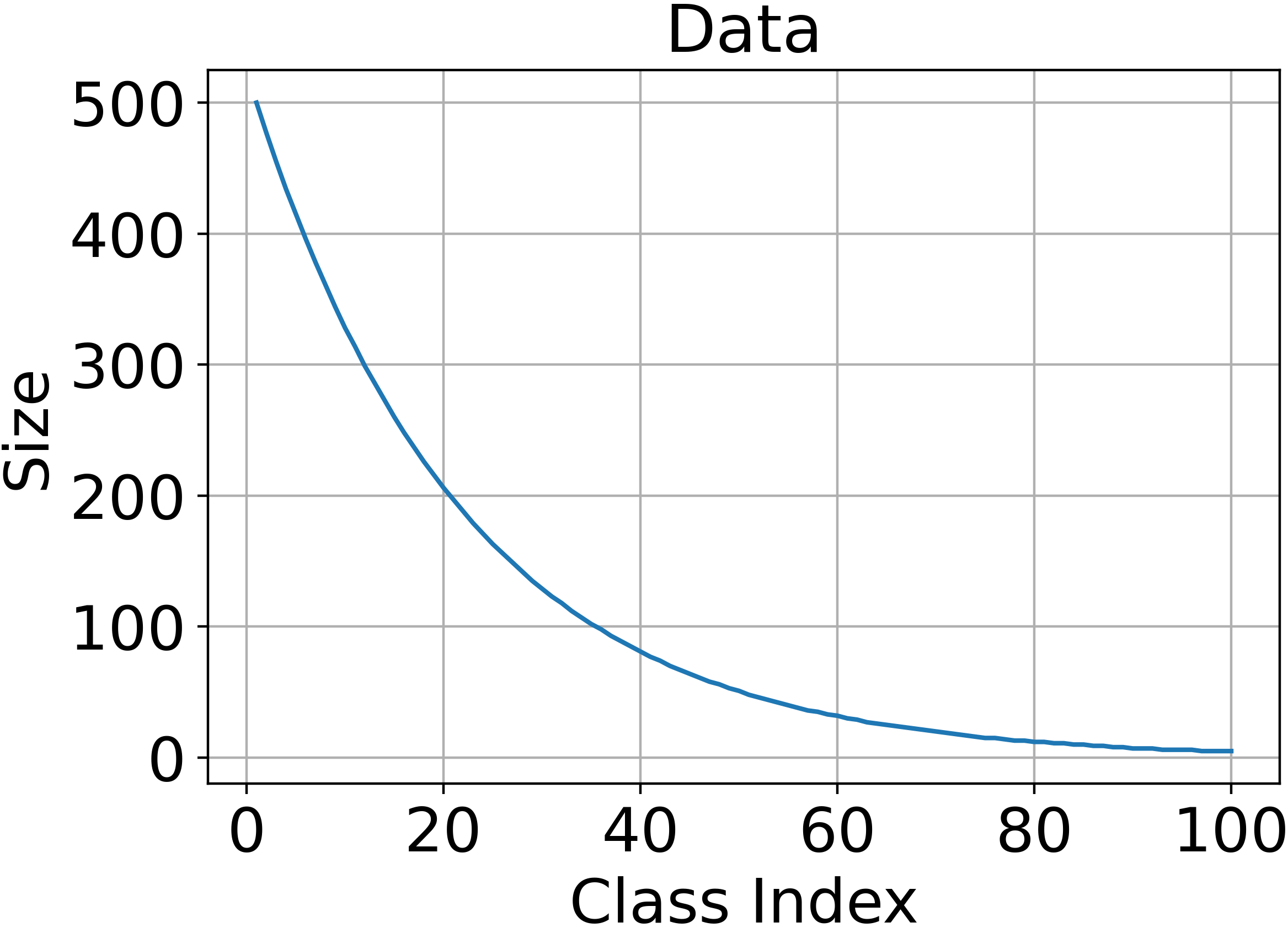
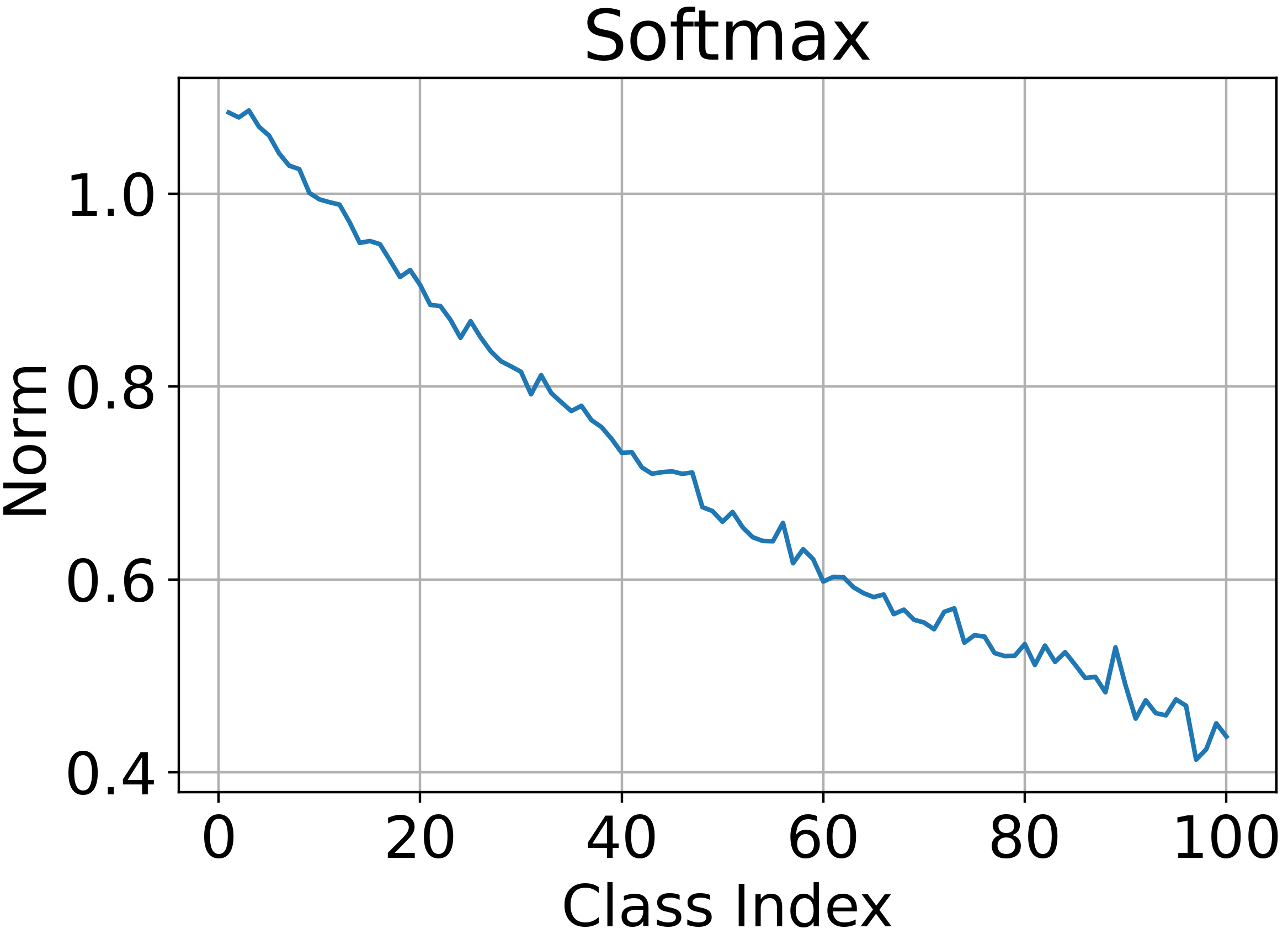
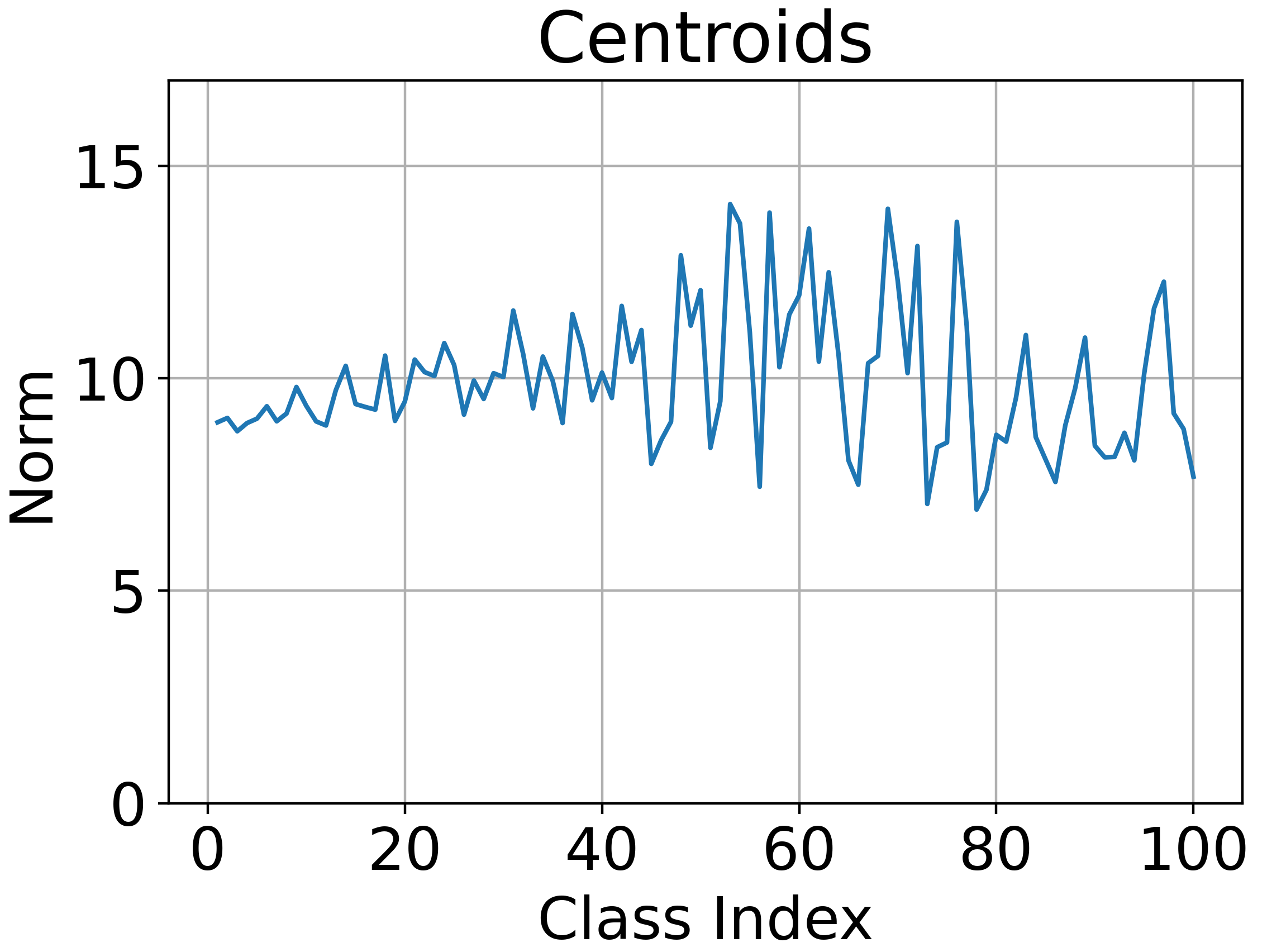
Abstract: The problem of long-tailed recognition (LTR) has received attention in recent years due to the fundamental power-law distribution of objects in the real-world. Most recent works in LTR use softmax classifiers that are biased in that they correlate classifier norm with the amount of training data for a given class. In this work, we show that learning prototype classifiers addresses the biased softmax problem in LTR. Prototype classifiers can deliver promising results simply using Nearest-Class- Mean (NCM), a special case where prototypes are empirical centroids. We go one step further and propose to jointly learn prototypes by using distances to prototypes in representation space as the logit scores for classification. Further, we theoretically analyze the properties of Euclidean distance based prototype classifiers that lead to stable gradient-based optimization which is robust to outliers. To enable independent distance scales along each channel, we enhance Prototype classifiers by learning channel-dependent temperature parameters. Our analysis shows that prototypes learned by Prototype classifiers are better separated than empirical centroids. Results on four LTR benchmarks show that Prototype classifier outperforms or is comparable to state-of-the-art methods. Our code is made available at https://github.com/saurabhsharma1993/prototype-classifier-ltr.
- Long-tailed recognition via weight balancing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6897–6907, 2022.
- Learning imbalanced datasets with label-distribution-aware margin loss. In NeurIPS, 2019.
- Smote: synthetic minority over-sampling technique. JAIR, 2002.
- Smoteboost: Improving prediction of the minority class in boosting. In European conference on principles of data mining and knowledge discovery, 2003.
- Autoaugment: Learning augmentation policies from data. arXiv preprint arXiv:1805.09501, 2018.
- Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 702–703, 2020.
- Class-balanced loss based on effective number of samples. In CVPR, 2019.
- Parametric contrastive learning. In Proceedings of the IEEE/CVF international conference on computer vision, pages 715–724, 2021.
- Imagenet: A large-scale hierarchical image database. In CVPR, 2009.
- Improved regularization of convolutional neural networks with cutout. arXiv preprint arXiv:1708.04552, 2017.
- C4. 5, class imbalance, and cost sensitivity: why under-sampling beats over-sampling. In Workshop on learning from imbalanced datasets II, 2003.
- A multiple resampling method for learning from imbalanced data sets. Computational intelligence, 2004.
- Exploring deep neural networks via layer-peeled model: Minority collapse in imbalanced training. Proceedings of the National Academy of Sciences, 118(43):e2103091118, 2021.
- Deepncm: Deep nearest class mean classifiers. In International Conference on Learning Representations Workshop, 2018.
- Learning from imbalanced data. TKDE, 2009.
- Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020.
- Decoupling representation and classifier for long-tailed recognition. In Eighth International Conference on Learning Representations (ICLR), 2020.
- Focal loss for dense object detection. In ICCV, 2017.
- Large-scale long-tailed recognition in an open world. In CVPR, 2019.
- Gistnet: a geometric structure transfer network for long-tailed recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8209–8218, 2021.
- Sgdr: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations, 2017.
- Long-tail learning via logit adjustment. In International Conference on Learning Representations, 2021.
- Distance-based image classification: Generalizing to new classes at near-zero cost. TPAMI, 2013.
- Fernando Nogueira et al. Bayesian optimization: Open source constrained global optimization tool for python. URL https://github. com/fmfn/BayesianOptimization, 2014.
- Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences, 117(40):24652–24663, 2020.
- icarl: Incremental classifier and representation learning. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, 2017.
- Balanced meta-softmax for long-tailed visual recognition. Advances in Neural Information Processing Systems, 33:4175–4186, 2020.
- Distributional robustness loss for long-tail learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021.
- Long-tailed recognition using class-balanced experts. In DAGM German Conference on Pattern Recognition. Springer, 2020.
- Prototypical networks for few-shot learning. In NeurIPS, 2017.
- Meta-transfer learning for few-shot learning. In CVPR, 2019.
- Imbalance trouble: Revisiting neural-collapse geometry. In Advances in Neural Information Processing Systems, 2022.
- The devil is in the tails: Fine-grained classification in the wild. arXiv preprint arXiv:1709.01450, 2017.
- The inaturalist species classification and detection dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8769–8778, 2018.
- Long-tailed recognition by routing diverse distribution-aware experts. In International Conference on Learning Representations, 2020.
- f-vaegan-d2: A feature generating framework for any-shot learning. In CVPR, 2019.
- Learning from multiple experts: Self-paced knowledge distillation for long-tailed classification. In European Conference on Computer Vision. Springer, 2020.
- Distribution alignment: A unified framework for long-tail visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2361–2370, 2021.
- Bbn: Bilateral-branch network with cumulative learning for long-tailed visual recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9719–9728, 2020.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper; each item is framed to suggest concrete directions for future work.
- Assumption of unimodal class-conditional Gaussians: The method assumes a single prototype per class and unit-variance Gaussian likelihoods, which may be unrealistic for multi-modal classes; effectiveness with multiple prototypes per class or mixture models is not explored.
- Prototype count per class: The paper does not investigate learning K>1 prototypes per class (e.g., clustering-based initialization or learnable K) or selection criteria for K.
- Theoretical analysis limited to Euclidean distance without CDT/LA: Stability proofs cover Euclidean distance only, but not the actual training objective with channel-dependent temperatures and logit adjustment; formal guarantees under CDT and LA are absent.
- Squared Euclidean analysis vs practice mismatch: The “bias negation via coupling” argument uses squared Euclidean distance, whereas training uses Euclidean distance; there is no theoretical bridge showing the same bias behavior under the Euclidean metric used in practice.
- Convergence and generalization guarantees: No formal convergence rates, sample complexity, or generalization bounds are provided for the prototype learning dynamics under long-tailed distributions.
- Robustness to label noise and heavy-tailed feature noise: Although the gradient is distance-invariant for Euclidean distance, the method’s sensitivity to mislabeled samples and systematic noise is untested; robust distance losses (Huber/Tukey) or robust prototype regularizers are not studied.
- CDT positivity and regularization: The paper does not specify how T_i are constrained to be positive nor how they are regularized (e.g., softplus parameterization, priors/penalties), risking invalid or degenerate temperatures.
- Overfitting risks of CDT: There is no study of overfitting when learning channel-wise temperatures on scarce tail-class data; regularization strategies (e.g., sparsity, shrinkage to 1, layer-wise grouping) are untested.
- Scope of metric learning: CDT implements only a diagonal Mahalanobis metric; full (low-rank or structured) Mahalanobis learning, class-wise or prototype-wise metrics, or input-conditional metrics are not explored.
- Calibration and uncertainty: The paper reports accuracy only; calibration metrics (ECE, Brier), class-wise calibration under imbalance, and the effect of LA on calibration are not measured.
- Inference-time prior shift: Logit adjustment is used during training only; strategies for handling changing class priors at inference (e.g., posterior recalibration, Bayes correction) are not evaluated.
- Computational and memory scalability: With thousands of classes (e.g., iNat18) the O(C·d) cost of per-sample distance computation may be significant; techniques like approximate nearest prototypes, hierarchical search, or prototype pruning are not analyzed.
- Prototype initialization strategies: Only centroid initialization is considered; sensitivity to initialization and alternatives (e.g., K-means, medoids, density-weighted centroids) are not studied.
- Training schedule minimalism: Prototype learning uses only one epoch; the impact of longer training, different optimizers, or annealing schedules (for CDT/LA) is not investigated.
- Sensitivity analyses: No systematic ablation for the logit-adjustment strength τ, prototype learning rate, CDT learning rate, momentum, or data-augmentation choices is provided.
- Data augmentation with frozen features: Prototype training applies augmentations while freezing the backbone; it is unclear if features are recomputed online or cached; the trade-offs and consistency of this setup are not examined.
- End-to-end vs decoupled training: The paper adopts two-stage training with frozen backbones; whether joint end-to-end training of features and prototypes (possibly with prototype/metric regularization) improves performance is untested.
- Comparison breadth: Methods closely related to normalized/margin-based softmax (e.g., NormFace/CosFace/ArcFace variants) and strong long-tail baselines beyond LDAM/LA are not comprehensively compared under identical backbones and tuning.
- Backbone diversity: Experiments use specific CNN backbones; generality to modern transformers, larger models, or self-supervised backbones is not evaluated.
- Feature normalization effects: The role of feature normalization (e.g., L2 normalization, whitening) on prototype learning and CDT behavior is not investigated.
- Handling multi-label or hierarchical labels: The method targets single-label classification; extension to multi-label or hierarchical long-tailed recognition (e.g., leveraging class taxonomies) is unexplored.
- Real-world test distributions: Results are reported on balanced validation/test sets; performance under naturally imbalanced test distributions, cost-sensitive metrics, or class-conditional risk is not studied.
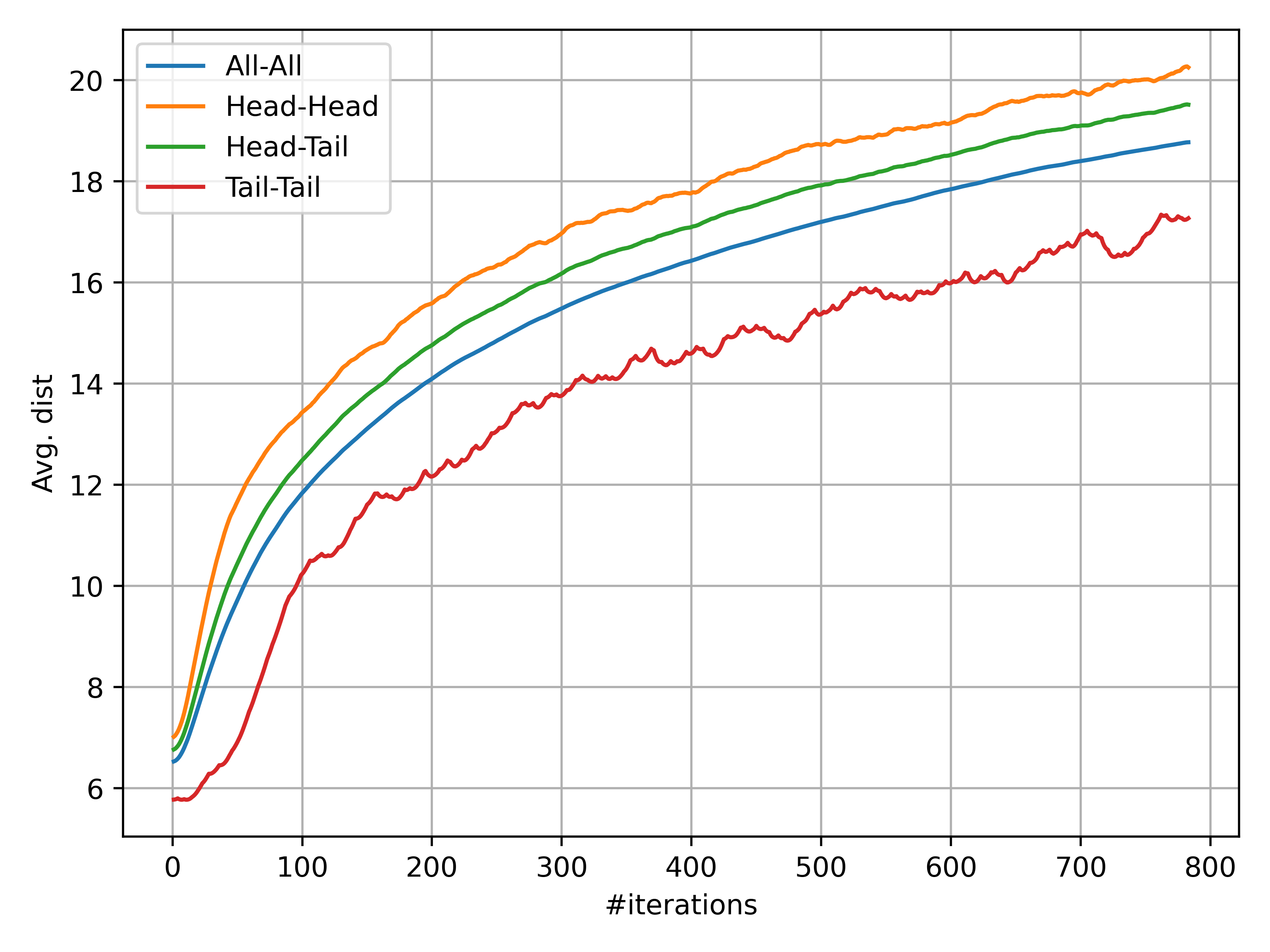
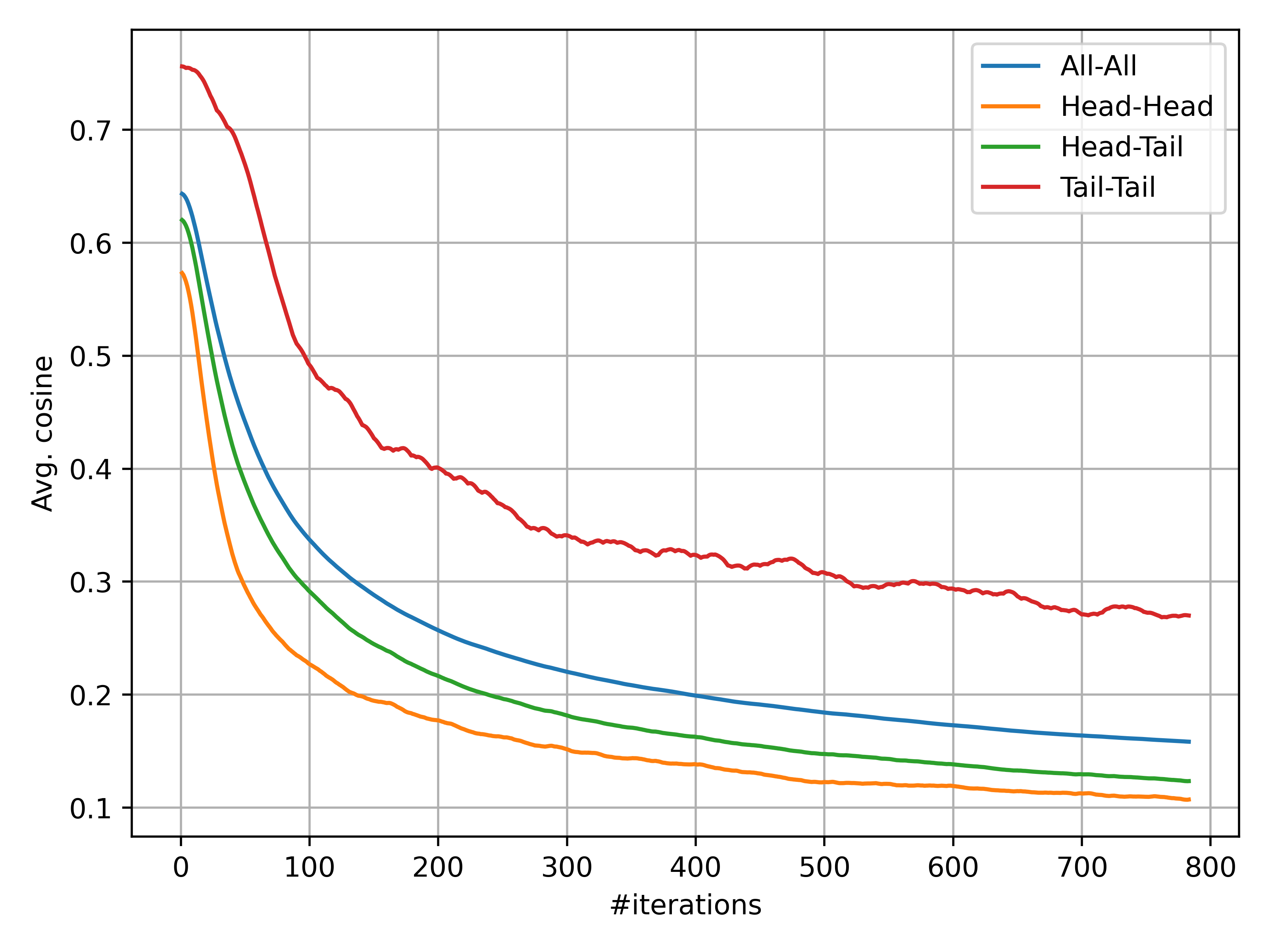
- Tail-class minority collapse: While prototype separation increases on average, Tail–Tail separation remains smaller than Head–Head; mechanisms explicitly countering minority collapse (e.g., margin constraints between tail prototypes) are not proposed.
- OOD detection and rejection: Prototype-based models often lend themselves to distance-based rejection; the method’s OOD detection or abstention capabilities are not evaluated.
- Fairness and “more fair decision boundaries” claim: The claim of fairer boundaries is not validated with fairness metrics or analyses of per-class decision margins under imbalance.
- Effect of feature scale shifts: Because distances are sensitive to representation scaling, robustness to backbone scale shifts (e.g., due to different normalization/weight decay) is not assessed.
- Prototype and CDT regularization: There is no exploration of explicit prototype norm constraints, inter-prototype margin regularizers, or CDT sparsity/entropy penalties to improve separation and generalization.
- Large-class regimes: Feasibility and performance for very large label spaces (e.g., 100k classes) in terms of search, memory, and prototype sharing/tying are not examined.
- Beyond accuracy: No analysis of error types (confusion matrices, per-class recall/precision), long-tail macro/micro-F1, or tail vs head calibration trade-offs is provided.
- Multi-task or incremental learning: Prototypes are a natural fit for class-incremental or few-shot tail updates; incremental addition of classes, prototype replay, or continual learning settings are not tested.
- Domain shift robustness: The approach is evaluated in in-domain settings only; robustness to domain shift, corruption, and distribution drift is not measured.
- Adversarial robustness: The sensitivity of distance-based prototypes to adversarial perturbations and potential defenses (e.g., adversarially robust metrics) remain open.
- Theoretical link to Bayes-optimality under imbalance: A formal treatment connecting prototype learning with Bayes-optimal classifiers under imbalanced priors (with/without LA) is missing.
- Practical constraints on T_i: No discussion of numerical stability (e.g., division by very small T_i), parameterization tricks, or bounds to ensure stable training and inference.
Collections
Sign up for free to add this paper to one or more collections.