- The paper introduces the DGA approach that balances domain adaptation with general knowledge preservation via soft-masking and a proxy KL-divergence loss.
- The method leverages contrastive learning to integrate domain-specific insights without overwriting essential general representations.
- Experimental results across six domains show significant improvements in F1 and accuracy compared to traditional DA-training methods.
Adapting a LLM While Preserving its General Knowledge
Introduction and Problem Statement
The paper "Adapting a LLM While Preserving its General Knowledge" (2301.08986) addresses the challenge of domain-adaptive pre-training (DA-training) for LMs. Traditional DA-training aims to adapt a pre-trained general-purpose LM using a domain-specific corpus, which improves performance on domain-relevant tasks. However, existing approaches often fail to explicitly preserve the valuable general knowledge embedded in the LM while incorporating domain-specific insights.
The authors propose a method termed DGA (DA-training - General knowledge preservation and LM Adaptation), which aims to achieve a fine balance by preserving general knowledge while integrating domain-specific information effectively. The DGA approach involves the innovative use of soft-masking on attention heads and a novel contrastive representation learning technique.
Methodological Innovations
The core contribution of the paper is the DGA approach, which consists of two innovative strategies:
- Soft-Masking of Attention Heads: This involves determining the importance of each attention head within the LM for preserving its general knowledge. The authors employ a novel proxy KL-divergence loss to quantify head importance without needing the original pre-training data. Higher importance scores lead to more constrained gradient updates during DA-training, which effectively "soft-masks" the attention heads to safeguard general knowledge against unwarranted modifications.
- Contrastive Learning: A key aspect of DGA is its contrastive learning framework, which contrasts general and full (general plus domain-specific) knowledge representations. The approach helps in learning robust and integrated representations, ensuring that domain-specific adaptations complement instead of overwrite the general knowledge. This method diverges from traditional contrastive learning by specifically targeting knowledge integration rather than just representation quality.
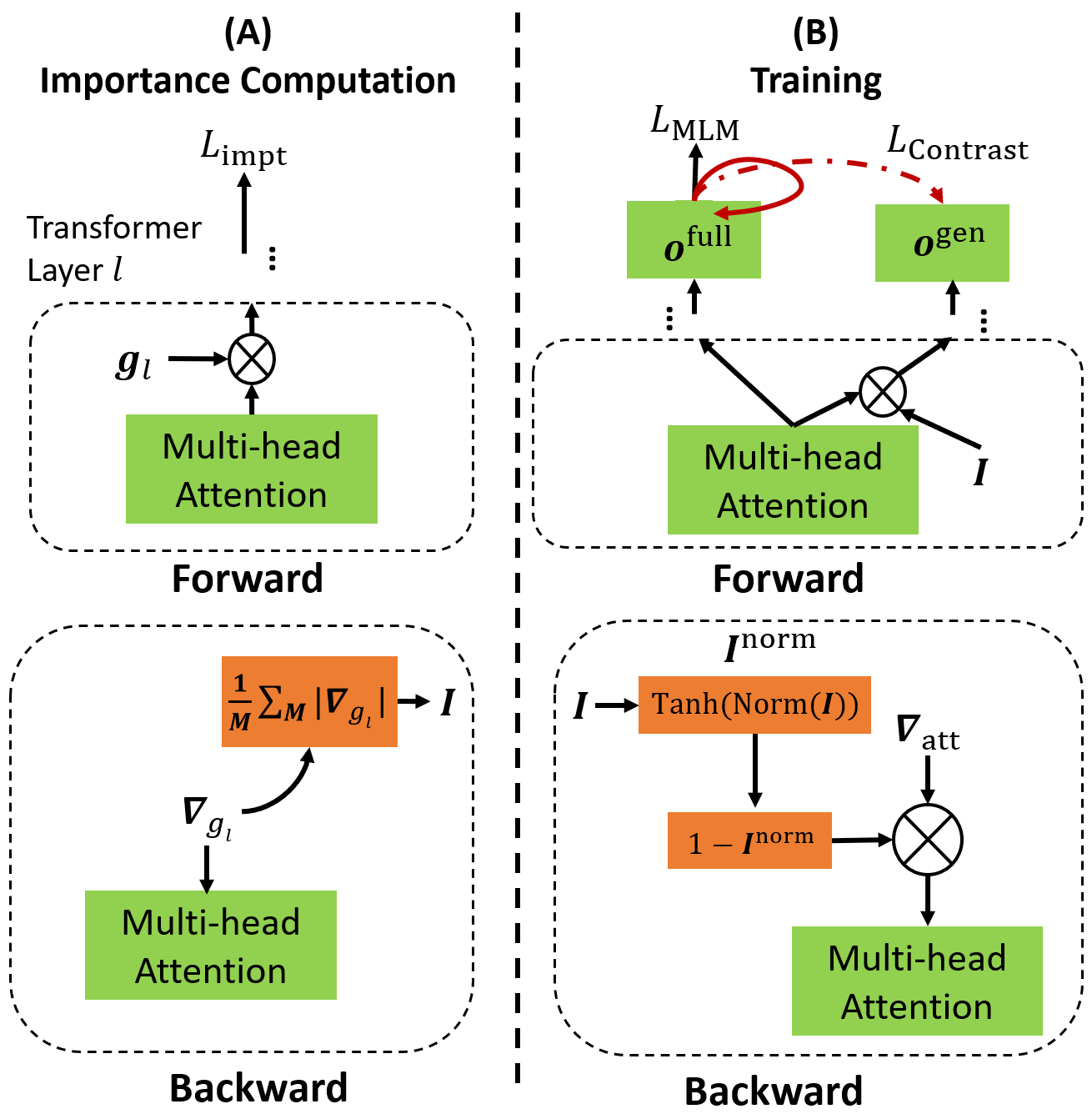
Figure 1: Illustration of DGA. Key components include importance computation and soft-masking for preserving general knowledge, and contrastive learning for knowledge integration.
Experimental Results
The experimental validation of DGA spans six different domains, demonstrating its efficacy over ten baseline methods, including traditional MLM-based DA-training, adapter-based methods, prompt-tuning, and various contrastive learning techniques.
The results indicate that DGA significantly outperforms baselines by effectively combining domain-specific adaptations with preserved general knowledge. Improvements are consistent across metrics such as F1 and accuracy, confirming that the proposed soft-masking and contrasting techniques address the limitations of conventional DA-training strategies.
Implications and Future Directions
The implications of DGA are substantial in the context of fine-tuning LMs for domain-specific tasks without sacrificing their general applicability. This work opens avenues for more informed adaptation techniques that consider the nuances of knowledge preservation alongside domain adaptation.
Practically, DGA can be leveraged in scenarios where domain-specific improvements are crucial, yet the integrity of general knowledge cannot be compromised—such as in medical or legal text processing. Theoretically, the methodological innovations call for further exploration into alternative importance quantification methods and broader applications of contrastive learning in knowledge integration.
Future research could focus on expanding DGA to multi-domain or lifelong learning settings, where cumulative domain knowledge must be efficiently managed without catastrophic forgetting.
Conclusion
The paper makes a significant contribution by addressing a critical gap in DA-training of LMs. Through innovative mechanisms like soft-masking and contrastive learning, it ensures that LMs can adapt to new domains while preserving essential general knowledge. The approach and its promising results not only enhance the practical utility of LMs in diverse domains but also encourage further exploration of seamless knowledge integration in machine learning.

