- The paper introduces a task-guided scientific knowledge retrieval paradigm that aligns computational representations with human cognitive workflows for innovative research.
- It demonstrates prototype systems like Bridger, a TGKR engine, and BEEP that improve ideation, blindspot discovery, and predictive accuracy across diverse domains.
- Empirical evidence indicates that targeted augmentation of scientific documents mitigates biases and overcomes information overload to enhance cross-disciplinary productivity.
Computational Augmentation for Scientific Discovery: Human-Centric Task-Guided Retrieval
Background: Human and Computational Bottlenecks in Scientific Progress
The paper "A Computational Inflection for Scientific Discovery" (2205.02007) articulates a fundamental tension in modern science: the exponential growth of digital scientific artifacts versus the bounded cognitive capacity of human researchers. While the global scientific output now grows at an unprecedented rate, primarily facilitated by digitization of literature, data, and discourse, the human brain remains limited in its ability to comprehensively ingest, assimilate, and reason over this ever-expanding corpus. This cognitive bottleneck is further exacerbated by intrinsic biases—such as attention, confirmation, and homophily biases—which restrict researchers' ability to explore novel directions and draw connections across disciplinary divides.
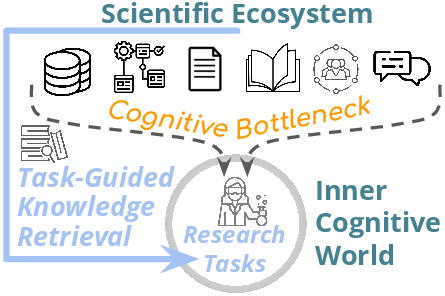
Figure 1: Information flows from the outer world into the inner cognitive world of researchers, constrained by cognitive capacity and biases.
The increasing digitization of both formal (e.g., articles, code) and informal artifacts (e.g., communications, notes) has not correspondingly augmented the internal cognitive mechanisms of scientific reasoning, decision-making, and creativity. The resulting "information overload" creates not only broad knowledge gaps but also personal "unknowns"—gaps in individual researchers’ understanding of the collective scientific corpus.
Task-Guided Scientific Knowledge Retrieval: Concept and Instantiations
The authors propose a strategic research agenda around "task-guided scientific knowledge retrieval" (TGKR). The paradigm is motivated by two core desiderata:
- Systems must enhance the flow from public knowledge (outer world) into the individual's internal reasoning (inner world), directly targeting core research tasks.
- Conceptual and algorithmic models must explicitly encode the diversity and complexity of cognitive processes underlying scientific research and align computational representations to these processes.
The TGKR paradigm challenges the dominant relevance-centric IR frameworks and emphasizes a wider spectrum of scholarly intents—ideation, hypothesis generation, learning, problem abstraction, and experimental design. This vision advocates for models that retrieve and synthesize knowledge for direct task utility, leveraging user-specific inferences about goals, background, biases, and knowledge state.
Prototypes and Empirical Evidence
A set of prototype systems is summarized to substantiate the utility and viability of TGKR:
1. Direction Generation via Analogical Author Discovery:
The Bridger system leverages structured representations of "problems" and "methods" as extracted from researchers’ own publications to surface authors with overlapping problems but with methodologically orthogonal approaches. Human-computer interaction studies reveal that Bridger significantly boosts creative ideation and facilitates cross-domain transfer, outperforming state-of-the-art neural search baselines in surfacing novel, actionable research connections.
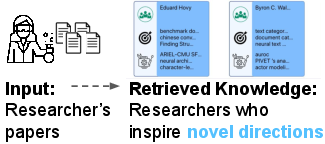
Figure 2: Matching researchers to authors with whom they are unfamiliar, to help in generating directions. Author cards show key problems and methods extracted from their papers.
2. Opportunity Identification and Blindspot Discovery:
A targeted TGKR engine identifies gaps in collective knowledge on query topics by mining explicit statements about uncertainty, difficulties, and open hypotheses from the literature. Evaluations, including users drawn from clinical settings, show that focusing search on explicit "unknowns" and uncertainties—rather than established literature—greatly increases the likelihood of surfacing new research directions and challenge areas. A related study of protein-protein interaction network curation unravels a pronounced locality bias, systematically obscuring large segments of biological knowledge and providing empirical support for attention-guiding retrieval tools.
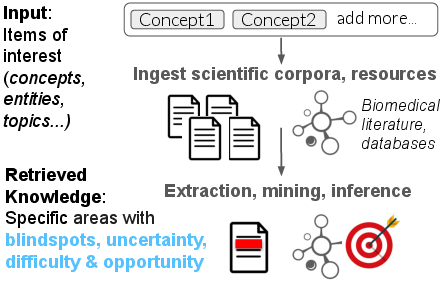
Figure 3: Suggesting research opportunities for query concepts (e.g., medical topics) by identifying blindspots, gaps in collective knowledge and promising areas for exploration.
3. Literature-Augmented Experimentation and Prediction:
Beyond awareness and ideation, systems such as BEEP use literature retrieval to directly inform experimental pipelines. Specifically, BEEP retrieves contextually matched clinical publications vis-à-vis the medical record of an ICU patient and fuses this with local EMR data for outcome prediction. The results indicate statistically significant improvements in predictive accuracy over classical models, and user studies suggest improved interpretability and actionability for clinicians.
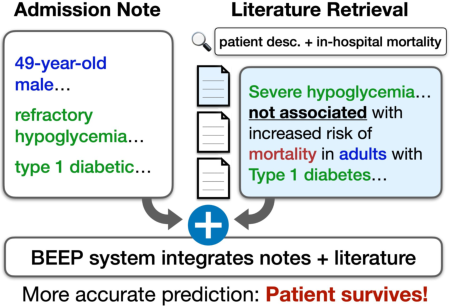
Figure 4: Leveraging medical corpora to enhance the precision of AI models for inference about patient outcomes.
4. Personalized Knowledge Alignment for Learning:
Systems that deliver definitions and explanations of unfamiliar concepts by explicitly grounding them in the prior knowledge of individual researchers improve learning outcomes and foster productive transfer.
The empirical studies uniformly show that TGKR methods—when aligned to the actual cognitive workflow and information needs of researchers—outperform traditional search and retrieval in both inspiration and decision support.
Research Trajectory: Representational and Inference Challenges
The aspirational systems outlined demand robust advances on several computational axes:
- Task-aligned Semantic Representations:
Building representations that capture the multi-faceted, hierarchical, and functionally operative relationships in scientific ideas—not just surface textual similarities—is critical. This includes mining for causal mechanisms, functional hierarchies, experimental methodologies, and design affordances. Limitations with current LLMs, such as lack of control "hooks" and interpretability, hinder alignment with user desiderata in cognitive workflows.
- Computational Algebra of Ideas:
Future systems should facilitate compositional reasoning, i.e., the ability to synthesize new hypotheses by algebraic recombination of concepts and methods, with the possibility of predicting the affordances that result from such combinations.
- Inference Over Personal Knowledge and Preferences:
Automated estimation of a user's latent knowledge, goals, and preferences—potentially via digital traces such as readings, writings, conversations—remains a fundamentally open problem. Mixed-initiative interfaces are advocated to allow humans to correct or augment machine-inferred models of their inner knowledge state.
- Bias Mitigation and Prioritization:
Automated systems are positioned to counteract human attention and confirmation biases by systematically mapping and prioritizing under-explored regions of the knowledge space, informed by both explicit content and latent structural indicators (e.g., citation and usage patterns).
- Personalized, Actionable Scientific Documents:
The vision extends to dynamic "living documents" that adapt explanations, summarization, and reflections based on who the reader is and what they already know, moving beyond static PDFs.
Implications and Forward-Looking AI Perspectives
This agenda presents profound implications for AI and the scientific enterprise:
AI systems derived from TGKR could mitigate the productivity deceleration observed in saturated scientific fields, increase cross-disciplinary fertilization, and democratize access to actionable insights, particularly for those outside traditional scientific hubs.
Advances in personal knowledge inference, computational representations of scientific concepts, and debiased exploration will feed back into foundational AI research—including representation learning, neural-symbolic integration, and mixed-initiative systems.
- Synergy with LLM Developments:
The framework identifies the limitations of current LLM-based systems—namely, lack of explicit user-model alignment and abstraction across fields—and sketches a roadmap for their integration as components within TGKR systems capable of reasoning compositionally and interactively at scale.
- Ethical and Sociotechnical Aspects:
Deployment of such augmentation tools necessitates attention to privacy, interpretability, and workflow integration, as evidenced by failed or stalled efforts in translational domains like healthcare.
Conclusion
The paper provides a comprehensive conceptual and empirical foundation for a shift in computational support for scientific discovery, centered on human-cognitive alignment and task-driven knowledge retrieval. The vision necessitates closed-loop, personalized, and cognitively aware AI systems capable of bridging the rapidly widening gap between the ever-growing digital corpus of science and the bounded rationality of human investigators. Realizing this vision entails advances in scientific NLP, representational abstraction, user modeling, and system integration, with the potential to reconfigure the landscape of scientific innovation and discovery (2205.02007).