- The paper presents how PKGs transform e-learning by personalizing recommendations and improving collaborative search functionalities.
- It details an architecture that processes user data with NLP and a weighted algorithm to integrate personal interests with semantic web resources.
- Preliminary evaluations indicate enhanced user engagement, while also highlighting challenges in semantic integration, privacy, and dynamic updates.
The paper introduces the concept of Personal Knowledge Graphs (PKGs) within the e-learning domain, focusing on how these user-centric knowledge representations can enhance personalization and collaborative search functionalities on educational platforms.
Introduction
PKGs have emerged from the semantic web community as compact representations tailored to individual users, bridging the use of encyclopedic knowledge graphs with personalized data. In educational settings, the interplay between PKGs and established knowledge bases like DBpedia can afford significant advantages in terms of tailored recommendations and enriched user interactions. This research focuses on deploying PKGs to enhance e-learning platforms by providing semantic recommendations and personalized collaborative search features.
Problem Statement
The paper identifies a critical gap in existing e-learning platforms, which typically lack semantic enrichment and personalization capabilities. PKGs present a solution to this problem by integrating personal data into broader knowledge bases, allowing for enhanced user-specific and group-specific recommendations. Particularly, the implementation of PKGs can address the needs for personalization in collaborative search environments and e-learning platforms, providing more tailored educational experiences and collaborative learning opportunities.
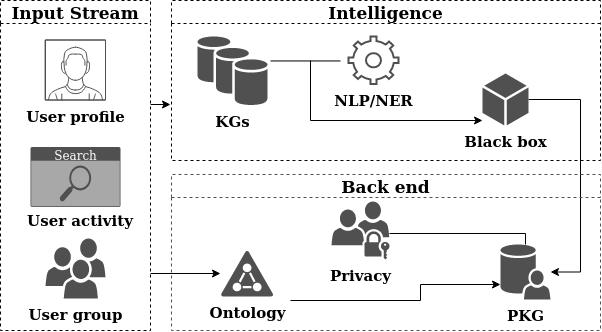
Figure 1: The overall architecture that includes the input stream, intelligence computation and back end creation of a personal knowledge graph (PKG).
Proposed Architecture
The architecture outlined in the paper incorporates an input stream, intelligence computation, and backend creation of PKGs. The process begins with collecting user-generated data, which is then processed through named entity recognition and natural language processing to identify relevant entities within the knowledge base. A weighted algorithm is employed to prioritize user interests, which evolve over time. The backend creation of PKGs also considers privacy constraints to ensure user consent and data protection.
Use Cases
Collaborative Search
Implementing PKGs in collaborative search settings facilitates personalized experiences by linking user actions to semantic web technologies. This integration allows for enhanced group collaboration by providing semantically enriched features that are informed by users' search histories and preferences. The collaborative search use case aims to utilize PKGs to improve team dynamics and provide insights into group performance, behavior, and collaborative effectiveness.
In e-learning settings, PKGs can be leveraged to provide personalized recommendations that align with users' learning preferences and skill development needs. The eDoer platform, focusing on Data Science skills, serves as a prototype for integrating PKGs to connect users with relevant educational resources. This approach supports adaptive learning experiences with semantic-based solutions.
Evaluation and Results
The paper discusses the need for rigorous evaluation methods involving user feedback and interaction studies. Preliminary experiments incorporating PKGs into learning platforms, and collaborative search environments have shown positive outcomes in user engagement and system transparency. Figures like semantic-enhanced visualizations in collaborative learning environments have been well received by participants, highlighting the potential for improved learning experiences.
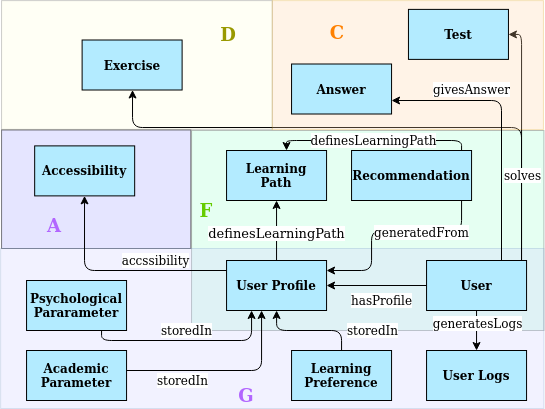
Figure 2: User Profile pattern that EduCOR suggests.
Challenges and Opportunities
Implementing PKGs presents several challenges, notably in semantic integration, privacy compliance, and maintaining dynamic user interests. The paper emphasizes the importance of addressing these issues and suggests open research directions including privacy models, real-time KG updates, and advanced recommendation algorithms.
Conclusion and Future Work
The integration of PKGs into e-learning platforms offers promising improvements in personalization and collaborative search capabilities. Future work will focus on refining PKG architectures, expanding semantic enrichment processes, and conducting comprehensive user evaluations to further validate the efficacy of these systems in educational settings. The continued convergence of semantic web technologies and personalized learning platforms presents significant opportunities for advancing the effectiveness and accessibility of online education.
This paper thus underlines the transformative potential of Personal Knowledge Graphs in the evolving landscape of digital education, where personalization and collaborative functionalities are increasingly paramount.

