- The paper introduces MaskGIT, a novel non-autoregressive framework that uses masked token modeling with parallel decoding to enhance image synthesis efficiency.
- It employs a two-stage process of image tokenization and masked visual token modeling, achieving faster decoding and improved quality metrics compared to autoregressive models.
- Experimental results on ImageNet highlight MaskGIT’s ability to outperform competitors in Inception Score, FID, and classification accuracy while enabling versatile image editing.
Introduction
The Masked Generative Image Transformer (MaskGIT) introduces a novel paradigm in the field of image synthesis by utilizing a bidirectional transformer decoder. Traditional generative models such as GANs and autoregressive transformers have achieved significant success in generating high-fidelity images but suffer from issues like training instability and inefficient decoding. MaskGIT aims to address these limitations by implementing a non-autoregressive, parallel decoding strategy that leverages a bidirectional self-attention mechanism. This facilitates significant speed improvements and broader applicability in image editing tasks, making it a promising approach for both generation and manipulation of images.
Methodology
MaskGIT operates in two main stages: image tokenization and masked visual token modeling (MVTM). In the first stage, images are tokenized into discrete visual tokens using an encoder and a codebook. Following this, the core innovation lies in the second stage, where a bidirectional transformer predicts masked tokens iteratively. Instead of generating tokens sequentially, MaskGIT predicts all image tokens in parallel, retaining the most confident predictions and masking others for refinement in subsequent iterations. The mask scheduling function, critical to this approach, orchestrates the iterative prediction process, optimizing both convergence and generation quality through a decreasing mask ratio strategy.

Figure 1: Comparison between sequential decoding and MaskGIT's scheduled parallel decoding.
Experimental Results
Empirical evaluation on the ImageNet dataset demonstrates MaskGIT's superior performance both in terms of quality and efficiency. On the 256x256 and 512x512 resolutions, MaskGIT significantly outperforms autoregressive models like VQGAN, achieving improved Inception Scores (IS) and Fréchet Inception Distance (FID) metrics. Additionally, the model sets new benchmarks on classification accuracy scores, highlighting its balanced performance across fidelity and diversity metrics. The parallel decoding capability allows MaskGIT to operate up to 64 times faster than traditional autoregressive methods, a substantial improvement reflected in wall-clock runtime measurements.
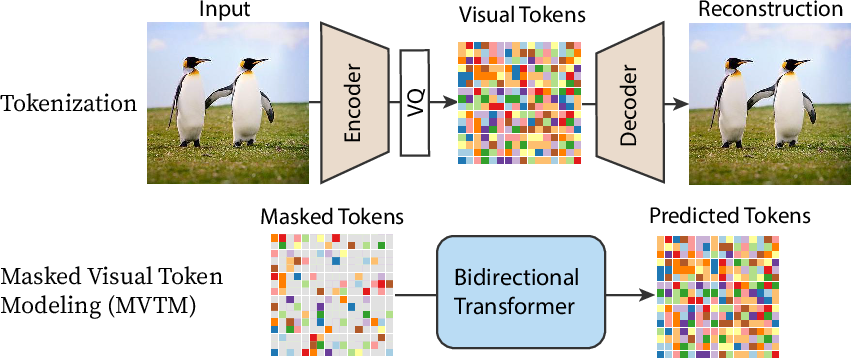
Figure 2: Pipeline Overview. MaskGIT follows a two-stage design, with a tokenizer and a bidirectional transformer model for MVTM.
Applications in Image Editing
Beyond synthesis, MaskGIT's design inherently supports diverse image editing tasks like inpainting, outpainting, and class-conditional editing. The non-sequential nature of its decoding process facilitates easy adaptation to scenarios requiring selective content modification while maintaining contextual fidelity. Experiments on image inpainting and outpainting showcase MaskGIT's capability to generate plausible extensions and repairs of image content, often producing superior results compared to contemporary GAN-based methods.




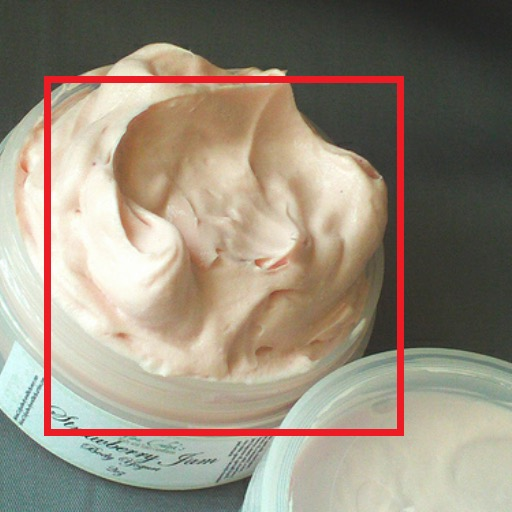







Figure 3: Class-conditional image editing. MaskGIT replaces bounding boxed regions with specified class content.
Future Directions and Implications
MaskGIT sets a precedent for utilizing masked token modeling in image generation, challenging the traditional autoregressive methods. Its scalability and adaptability to various editing tasks suggest potential applications in creative industries, automated content generation, and even real-time visual data augmentation. Future work could explore enhancements in attention mechanisms, further refinements in mask scheduling functions, and integrations with multimodal data inputs to extend the versatility of generative transformers.
Conclusion
MaskGIT represents a significant evolution in image synthesis methodology, combining the strengths of bidirectional transformers with innovative parallel decoding strategies. Its enhanced efficiency, coupled with competitive quality metrics, positions it as a state-of-the-art model for practical and theoretical advancements in generative modeling. By laying the groundwork for non-autoregressive, parallel image generation, MaskGIT opens new avenues for research and application development in computer vision.